Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Efficient Distributed Dual Coordinate Ascent
Paper and Code
Sep 29, 2014
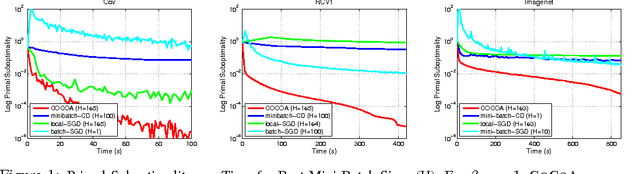
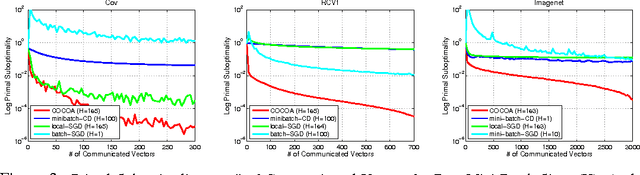
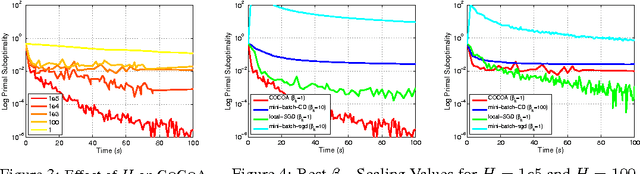
Communication remains the most significant bottleneck in the performance of distributed optimization algorithms for large-scale machine learning. In this paper, we propose a communication-efficient framework, CoCoA, that uses local computation in a primal-dual setting to dramatically reduce the amount of necessary communication. We provide a strong convergence rate analysis for this class of algorithms, as well as experiments on real-world distributed datasets with implementations in Spark. In our experiments, we find that as compared to state-of-the-art mini-batch versions of SGD and SDCA algorithms, CoCoA converges to the same .001-accurate solution quality on average 25x as quickly.
* NIPS 2014 version, including proofs. Published in Advances in Neural
Information Processing Systems 27 (NIPS 2014)
View paper on