 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssisting Human Decisions in Document Matching
Feb 16, 2023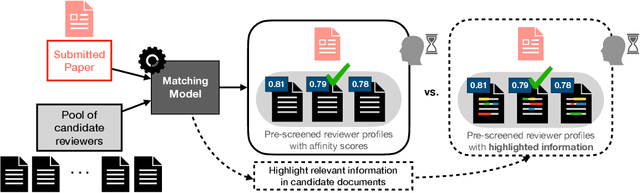

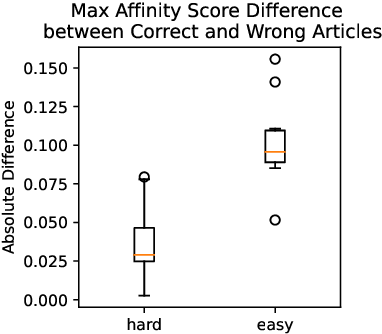
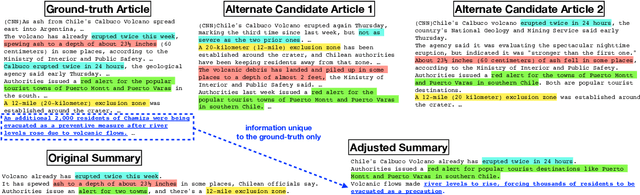
Many practical applications, ranging from paper-reviewer assignment in peer review to job-applicant matching for hiring, require human decision makers to identify relevant matches by combining their expertise with predictions from machine learning models. In many such model-assisted document matching tasks, the decision makers have stressed the need for assistive information about the model outputs (or the data) to facilitate their decisions. In this paper, we devise a proxy matching task that allows us to evaluate which kinds of assistive information improve decision makers' performance (in terms of accuracy and time). Through a crowdsourced (N=271 participants) study, we find that providing black-box model explanations reduces users' accuracy on the matching task, contrary to the commonly-held belief that they can be helpful by allowing better understanding of the model. On the other hand, custom methods that are designed to closely attend to some task-specific desiderata are found to be effective in improving user performance. Surprisingly, we also find that the users' perceived utility of assistive information is misaligned with their objective utility (measured through their task performance).
Bayesian Persuasion for Algorithmic Recourse
Dec 12, 2021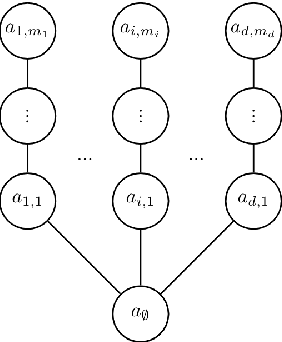
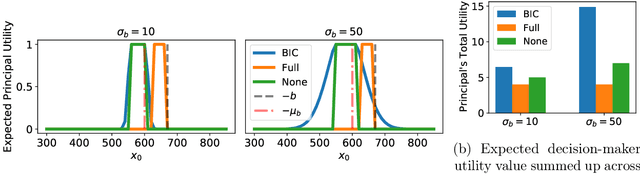
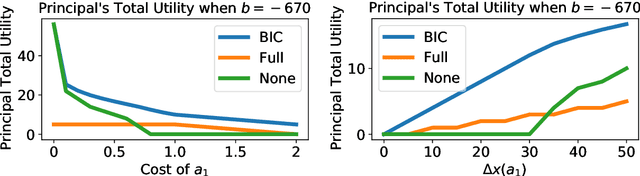
When subjected to automated decision-making, decision-subjects will strategically modify their observable features in ways they believe will maximize their chances of receiving a desirable outcome. In many situations, the underlying predictive model is deliberately kept secret to avoid gaming and maintain competitive advantage. This opacity forces the decision subjects to rely on incomplete information when making strategic feature modifications. We capture such settings as a game of Bayesian persuasion, in which the decision-maker sends a signal, e.g., an action recommendation, to a decision subject to incentivize them to take desirable actions. We formulate the decision-maker's problem of finding the optimal Bayesian incentive-compatible (BIC) action recommendation policy as an optimization problem and characterize the solution via a linear program. Through this characterization, we observe that while the problem of finding the optimal BIC recommendation policy can be simplified dramatically, the computational complexity of solving this linear program is closely tied to (1) the relative size of the decision-subjects' action space, and (2) the number of features utilized by the underlying predictive model. Finally, we provide bounds on the performance of the optimal BIC recommendation policy and show that it can lead to arbitrarily better outcomes compared to standard baselines.
Sanity Simulations for Saliency Methods
May 13, 2021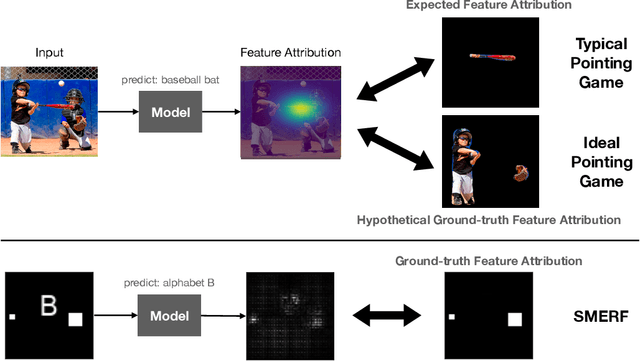
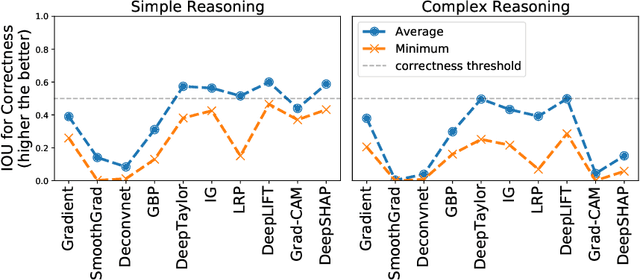
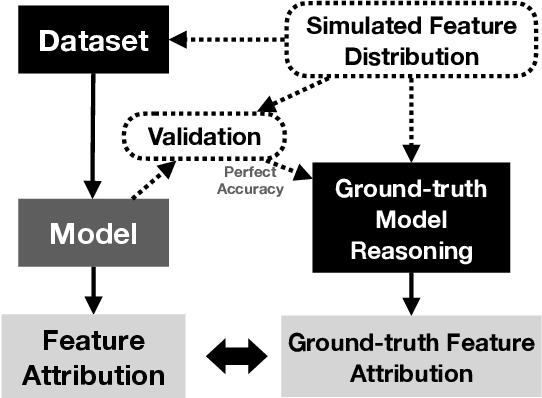
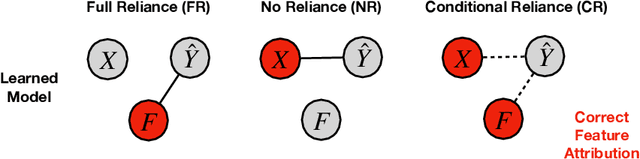
Saliency methods are a popular class of feature attribution tools that aim to capture a model's predictive reasoning by identifying "important" pixels in an input image. However, the development and adoption of saliency methods are currently hindered by the lack of access to underlying model reasoning, which prevents accurate method evaluation. In this work, we design a synthetic evaluation framework, SMERF, that allows us to perform ground-truth-based evaluation of saliency methods while controlling the underlying complexity of model reasoning. Experimental evaluations via SMERF reveal significant limitations in existing saliency methods, especially given the relative simplicity of SMERF's synthetic evaluation tasks. Moreover, the SMERF benchmarking suite represents a useful tool in the development of new saliency methods to potentially overcome these limitations.
Towards Connecting Use Cases and Methods in Interpretable Machine Learning
Mar 10, 2021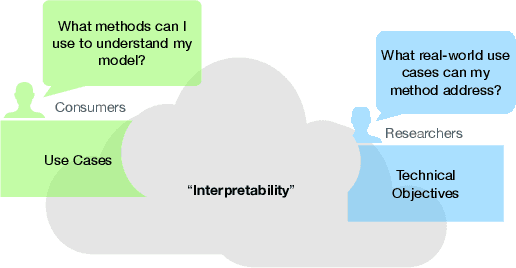

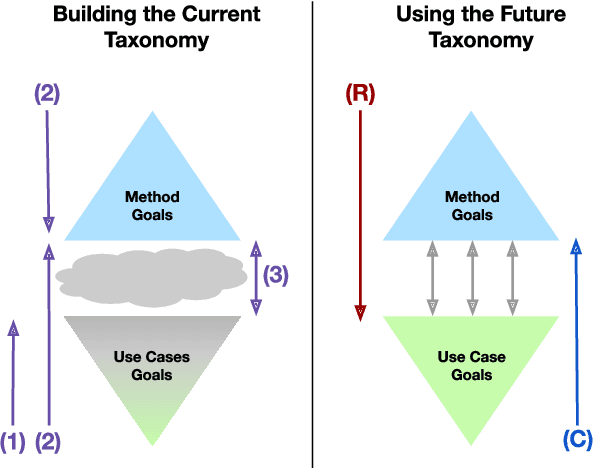
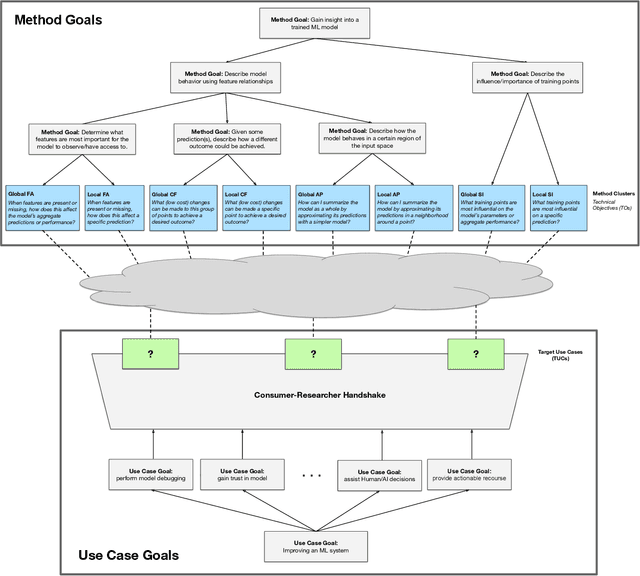
Despite increasing interest in the field of Interpretable Machine Learning (IML), a significant gap persists between the technical objectives targeted by researchers' methods and the high-level goals of consumers' use cases. In this work, we synthesize foundational work on IML methods and evaluation into an actionable taxonomy. This taxonomy serves as a tool to conceptualize the gap between researchers and consumers, illustrated by the lack of connections between its methods and use cases components. It also provides the foundation from which we describe a three-step workflow to better enable researchers and consumers to work together to discover what types of methods are useful for what use cases. Eventually, by building on the results generated from this workflow, a more complete version of the taxonomy will increasingly allow consumers to find relevant methods for their target use cases and researchers to identify applicable use cases for their proposed methods.
Model-Agnostic Characterization of Fairness Trade-offs
Apr 08, 2020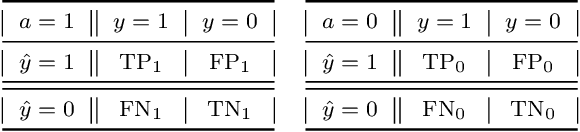

There exist several inherent trade-offs in designing a fair model, such as those between the model's predictive performance and fairness, or even among different notions of fairness. In practice, exploring these trade-offs requires significant human and computational resources. We propose a diagnostic that enables practitioners to explore these trade-offs without training a single model. Our work hinges on the observation that many widely-used fairness definitions can be expressed via the fairness-confusion tensor, an object obtained by splitting the traditional confusion matrix according to protected data attributes. Optimizing accuracy and fairness objectives directly over the elements in this tensor yields a data-dependent yet model-agnostic way of understanding several types of trade-offs. We further leverage this tensor-based perspective to generalize existing theoretical impossibility results to a wider range of fairness definitions. Finally, we demonstrate the usefulness of the proposed diagnostic on synthetic and real datasets.
Efficient Topological Layer based on Persistent Landscapes
Feb 07, 2020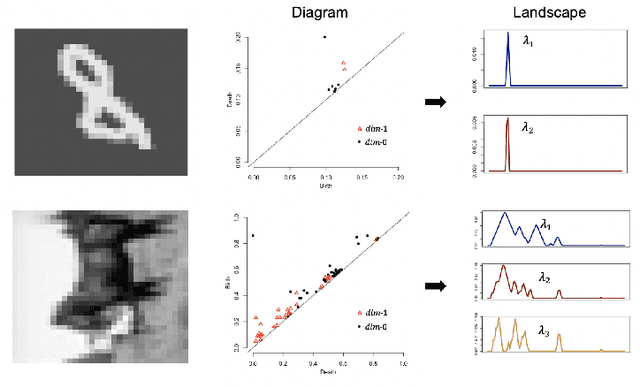

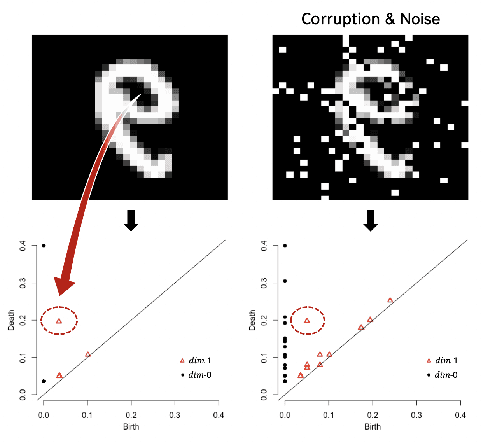

We propose a novel topological layer for general deep learning models based on persistent landscapes, in which we can efficiently exploit underlying topological features of the input data structure. We use the robust DTM function and show differentiability with respect to layer inputs, for a general persistent homology with arbitrary filtration. Thus, our proposed layer can be placed anywhere in the network architecture and feed critical information on the topological features of input data into subsequent layers to improve the learnability of the networks toward a given task. A task-optimal structure of the topological layer is learned during training via backpropagation, without requiring any input featurization or data preprocessing. We provide a tight stability theorem, and show that the proposed layer is robust towards noise and outliers. We demonstrate the effectiveness of our approach by classification experiments on various datasets.
Diagnostic Curves for Black Box Models
Dec 02, 2019
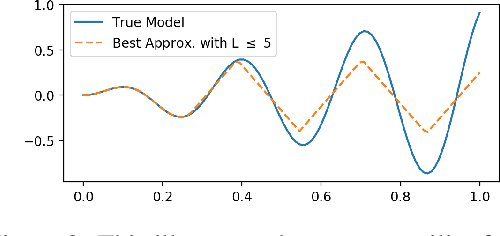
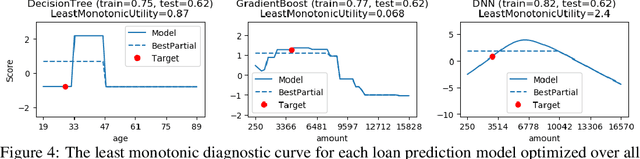
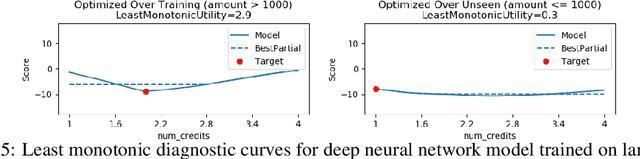
In safety-critical applications of machine learning, it is often necessary to look beyond standard metrics such as test accuracy in order to validate various qualitative properties such as monotonicity with respect to a feature or combination of features, checking for undesirable changes or oscillations in the response, and differences in outcomes (e.g. discrimination) for a protected class. To help answer this need, we propose a framework for approximately validating (or invalidating) various properties of a black box model by finding a univariate diagnostic curve in the input space whose output maximally violates a given property. These diagnostic curves show the exact value of the model along the curve and can be displayed with a simple and intuitive line graph. We demonstrate the usefulness of these diagnostic curves across multiple use-cases and datasets including selecting between two models and understanding out-of-sample behavior.
Representer Point Selection for Explaining Deep Neural Networks
Nov 23, 2018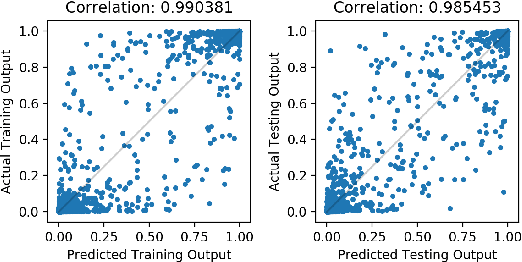

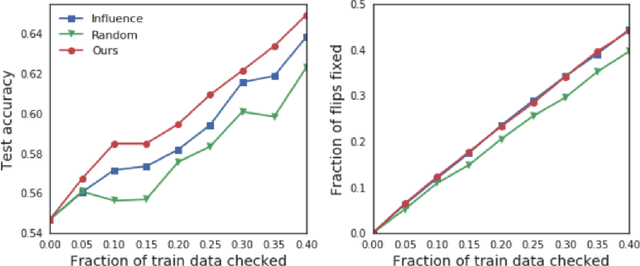

We propose to explain the predictions of a deep neural network, by pointing to the set of what we call representer points in the training set, for a given test point prediction. Specifically, we show that we can decompose the pre-activation prediction of a neural network into a linear combination of activations of training points, with the weights corresponding to what we call representer values, which thus capture the importance of that training point on the learned parameters of the network. But it provides a deeper understanding of the network than simply training point influence: with positive representer values corresponding to excitatory training points, and negative values corresponding to inhibitory points, which as we show provides considerably more insight. Our method is also much more scalable, allowing for real-time feedback in a manner not feasible with influence functions.
A Rotation Invariant Latent Factor Model for Moveme Discovery from Static Poses
Sep 23, 2016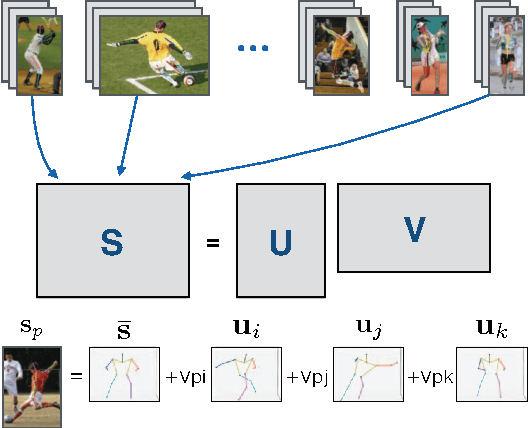
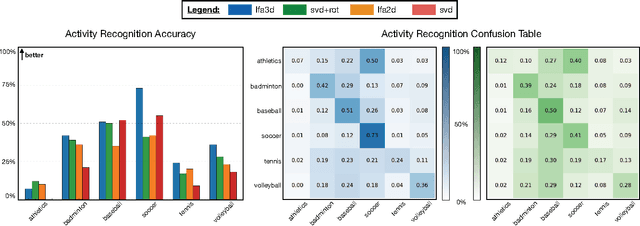
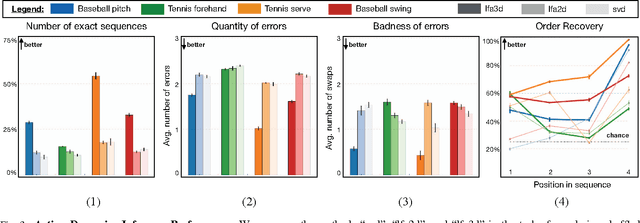

We tackle the problem of learning a rotation invariant latent factor model when the training data is comprised of lower-dimensional projections of the original feature space. The main goal is the discovery of a set of 3-D bases poses that can characterize the manifold of primitive human motions, or movemes, from a training set of 2-D projected poses obtained from still images taken at various camera angles. The proposed technique for basis discovery is data-driven rather than hand-designed. The learned representation is rotation invariant, and can reconstruct any training instance from multiple viewing angles. We apply our method to modeling human poses in sports (via the Leeds Sports Dataset), and demonstrate the effectiveness of the learned bases in a range of applications such as activity classification, inference of dynamics from a single frame, and synthetic representation of movements.