 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvocation: Who benefits from "inclusion" in Generative AI?
Nov 14, 2024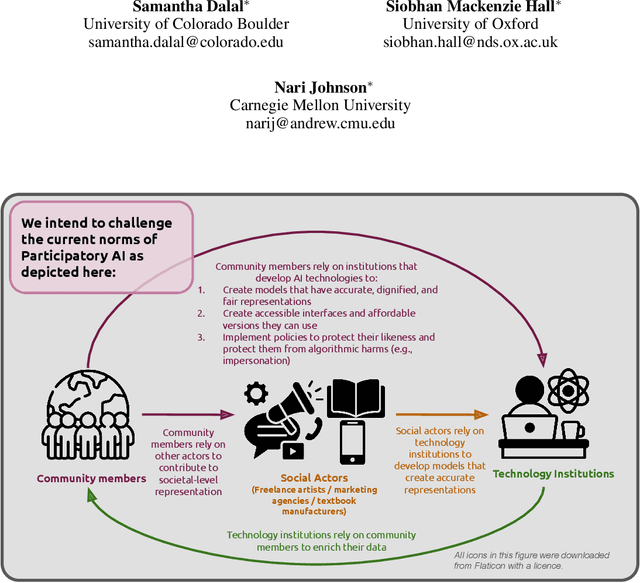
The demands for accurate and representative generative AI systems means there is an increased demand on participatory evaluation structures. While these participatory structures are paramount to to ensure non-dominant values, knowledge and material culture are also reflected in AI models and the media they generate, we argue that dominant structures of community participation in AI development and evaluation are not explicit enough about the benefits and harms that members of socially marginalized groups may experience as a result of their participation. Without explicit interrogation of these benefits by AI developers, as a community we may remain blind to the immensity of systemic change that is needed as well. To support this provocation, we present a speculative case study, developed from our own collective experiences as AI researchers. We use this speculative context to itemize the barriers that need to be overcome in order for the proposed benefits to marginalized communities to be realized, and harms mitigated.
Public Procurement for Responsible AI? Understanding U.S. Cities' Practices, Challenges, and Needs
Nov 07, 2024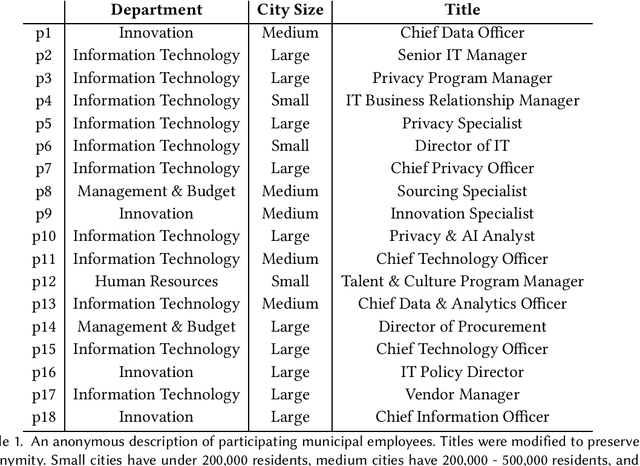
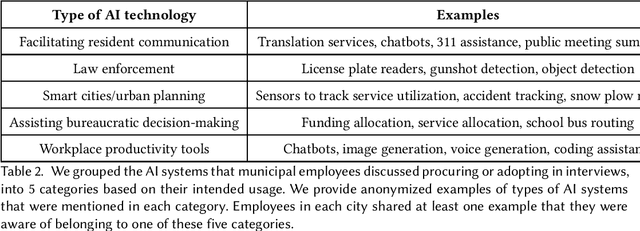
Most AI tools adopted by governments are not developed internally, but instead are acquired from third-party vendors in a process called public procurement. While scholars and regulatory proposals have recently turned towards procurement as a site of intervention to encourage responsible AI governance practices, little is known about the practices and needs of city employees in charge of AI procurement. In this paper, we present findings from semi-structured interviews with 18 city employees across 7 US cities. We find that AI acquired by cities often does not go through a conventional public procurement process, posing challenges to oversight and governance. We identify five key types of challenges to leveraging procurement for responsible AI that city employees face when interacting with colleagues, AI vendors, and members of the public. We conclude by discussing recommendations and implications for governments, researchers, and policymakers.
Assessing AI Impact Assessments: A Classroom Study
Nov 19, 2023



Artificial Intelligence Impact Assessments ("AIIAs"), a family of tools that provide structured processes to imagine the possible impacts of a proposed AI system, have become an increasingly popular proposal to govern AI systems. Recent efforts from government or private-sector organizations have proposed many diverse instantiations of AIIAs, which take a variety of forms ranging from open-ended questionnaires to graded score-cards. However, to date that has been limited evaluation of existing AIIA instruments. We conduct a classroom study (N = 38) at a large research-intensive university (R1) in an elective course focused on the societal and ethical implications of AI. We assign students to different organizational roles (for example, an ML scientist or product manager) and ask participant teams to complete one of three existing AI impact assessments for one of two imagined generative AI systems. In our thematic analysis of participants' responses to pre- and post-activity questionnaires, we find preliminary evidence that impact assessments can influence participants' perceptions of the potential risks of generative AI systems, and the level of responsibility held by AI experts in addressing potential harm. We also discover a consistent set of limitations shared by several existing AIIA instruments, which we group into concerns about their format and content, as well as the feasibility and effectiveness of the activity in foreseeing and mitigating potential harms. Drawing on the findings of this study, we provide recommendations for future work on developing and validating AIIAs.
Where Does My Model Underperform? A Human Evaluation of Slice Discovery Algorithms
Jun 13, 2023Machine learning (ML) models that achieve high average accuracy can still underperform on semantically coherent subsets (i.e. "slices") of data. This behavior can have significant societal consequences for the safety or bias of the model in deployment, but identifying these underperforming slices can be difficult in practice, especially in domains where practitioners lack access to group annotations to define coherent subsets of their data. Motivated by these challenges, ML researchers have developed new slice discovery algorithms that aim to group together coherent and high-error subsets of data. However, there has been little evaluation focused on whether these tools help humans form correct hypotheses about where (for which groups) their model underperforms. We conduct a controlled user study (N = 15) where we show 40 slices output by two state-of-the-art slice discovery algorithms to users, and ask them to form hypotheses about where an object detection model underperforms. Our results provide positive evidence that these tools provide some benefit over a naive baseline, and also shed light on challenges faced by users during the hypothesis formation step. We conclude by discussing design opportunities for ML and HCI researchers. Our findings point to the importance of centering users when designing and evaluating new tools for slice discovery.
Evaluating Systemic Error Detection Methods using Synthetic Images
Jul 08, 2022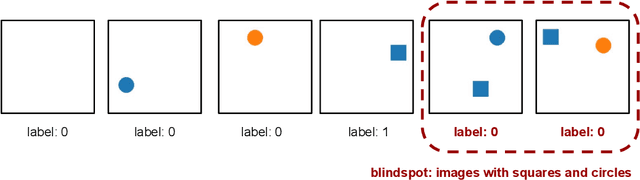
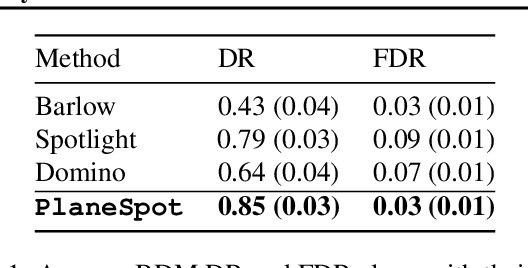
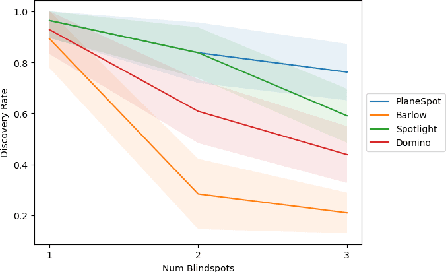

We introduce SpotCheck, a framework for generating synthetic datasets to use for evaluating methods for discovering blindspots (i.e., systemic errors) in image classifiers. We use SpotCheck to run controlled studies of how various factors influence the performance of blindspot discovery methods. Our experiments reveal several shortcomings of existing methods, such as relatively poor performance in settings with multiple blindspots and sensitivity to hyperparameters. Further, we find that a method based on dimensionality reduction, PlaneSpot, is competitive with existing methods, which has promising implications for the development of interactive tools.
OpenXAI: Towards a Transparent Evaluation of Model Explanations
Jun 22, 2022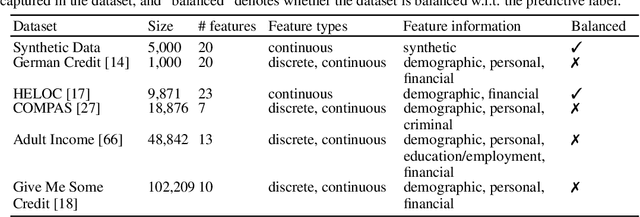
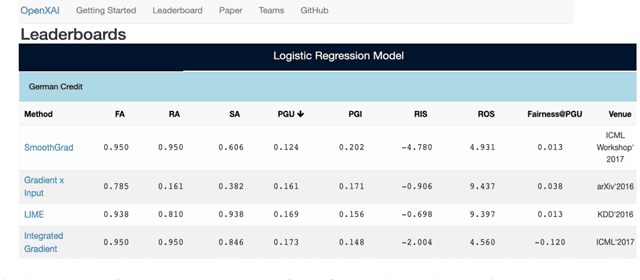
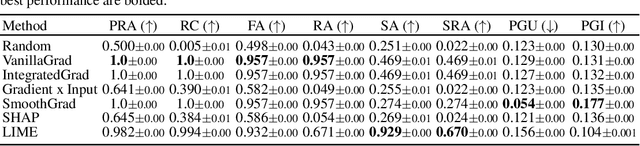
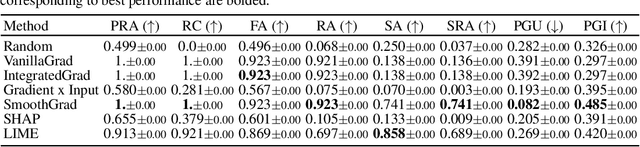
While several types of post hoc explanation methods (e.g., feature attribution methods) have been proposed in recent literature, there is little to no work on systematically benchmarking these methods in an efficient and transparent manner. Here, we introduce OpenXAI, a comprehensive and extensible open source framework for evaluating and benchmarking post hoc explanation methods. OpenXAI comprises of the following key components: (i) a flexible synthetic data generator and a collection of diverse real-world datasets, pre-trained models, and state-of-the-art feature attribution methods, (ii) open-source implementations of twenty-two quantitative metrics for evaluating faithfulness, stability (robustness), and fairness of explanation methods, and (iii) the first ever public XAI leaderboards to benchmark explanations. OpenXAI is easily extensible, as users can readily evaluate custom explanation methods and incorporate them into our leaderboards. Overall, OpenXAI provides an automated end-to-end pipeline that not only simplifies and standardizes the evaluation of post hoc explanation methods, but also promotes transparency and reproducibility in benchmarking these methods. OpenXAI datasets and data loaders, implementations of state-of-the-art explanation methods and evaluation metrics, as well as leaderboards are publicly available at https://open-xai.github.io/.
Use-Case-Grounded Simulations for Explanation Evaluation
Jun 05, 2022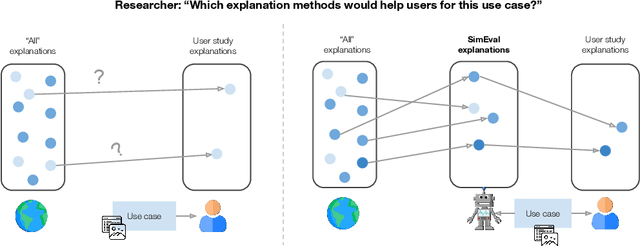
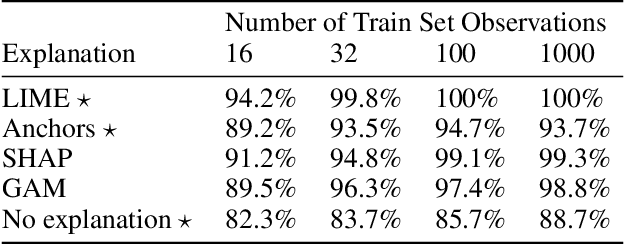
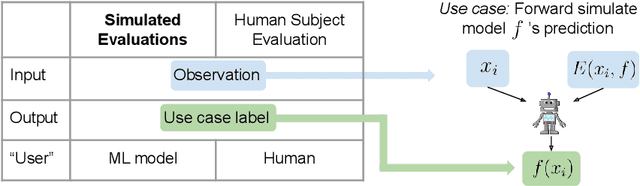
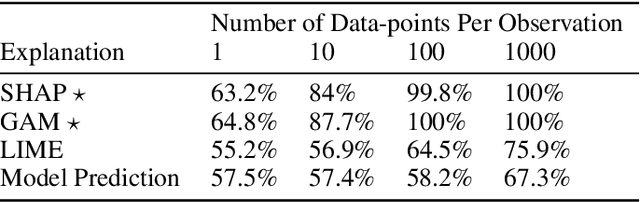
A growing body of research runs human subject evaluations to study whether providing users with explanations of machine learning models can help them with practical real-world use cases. However, running user studies is challenging and costly, and consequently each study typically only evaluates a limited number of different settings, e.g., studies often only evaluate a few arbitrarily selected explanation methods. To address these challenges and aid user study design, we introduce Use-Case-Grounded Simulated Evaluations (SimEvals). SimEvals involve training algorithmic agents that take as input the information content (such as model explanations) that would be presented to each participant in a human subject study, to predict answers to the use case of interest. The algorithmic agent's test set accuracy provides a measure of the predictiveness of the information content for the downstream use case. We run a comprehensive evaluation on three real-world use cases (forward simulation, model debugging, and counterfactual reasoning) to demonstrate that Simevals can effectively identify which explanation methods will help humans for each use case. These results provide evidence that SimEvals can be used to efficiently screen an important set of user study design decisions, e.g. selecting which explanations should be presented to the user, before running a potentially costly user study.
Rethinking Stability for Attribution-based Explanations
Mar 14, 2022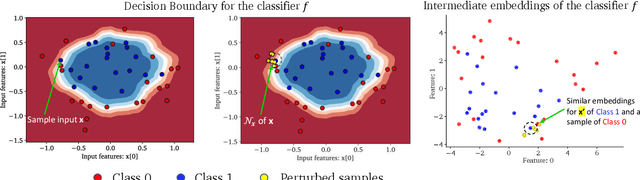


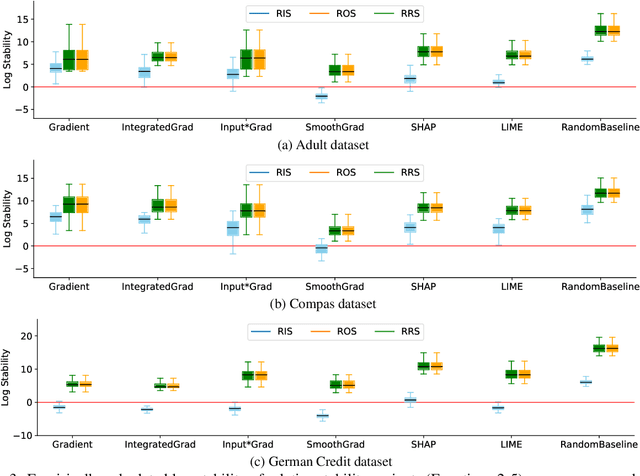
As attribution-based explanation methods are increasingly used to establish model trustworthiness in high-stakes situations, it is critical to ensure that these explanations are stable, e.g., robust to infinitesimal perturbations to an input. However, previous works have shown that state-of-the-art explanation methods generate unstable explanations. Here, we introduce metrics to quantify the stability of an explanation and show that several popular explanation methods are unstable. In particular, we propose new Relative Stability metrics that measure the change in output explanation with respect to change in input, model representation, or output of the underlying predictor. Finally, our experimental evaluation with three real-world datasets demonstrates interesting insights for seven explanation methods and different stability metrics.
Learning Predictive and Interpretable Timeseries Summaries from ICU Data
Sep 22, 2021
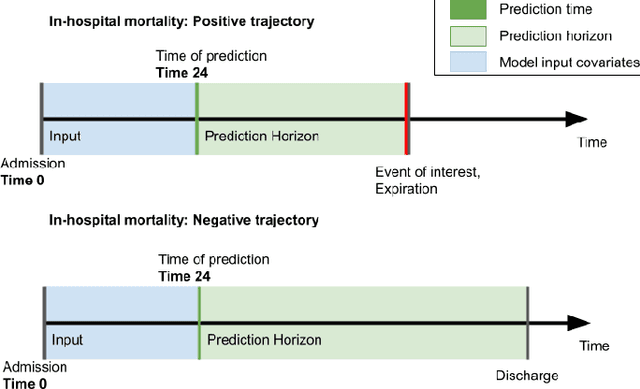
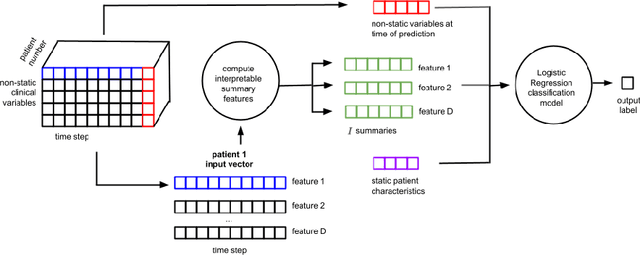
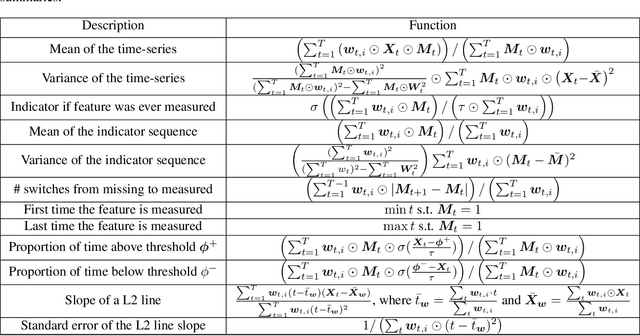
Machine learning models that utilize patient data across time (rather than just the most recent measurements) have increased performance for many risk stratification tasks in the intensive care unit. However, many of these models and their learned representations are complex and therefore difficult for clinicians to interpret, creating challenges for validation. Our work proposes a new procedure to learn summaries of clinical time-series that are both predictive and easily understood by humans. Specifically, our summaries consist of simple and intuitive functions of clinical data (e.g. falling mean arterial pressure). Our learned summaries outperform traditional interpretable model classes and achieve performance comparable to state-of-the-art deep learning models on an in-hospital mortality classification task.