 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Predictive and Interpretable Timeseries Summaries from ICU Data
Sep 22, 2021
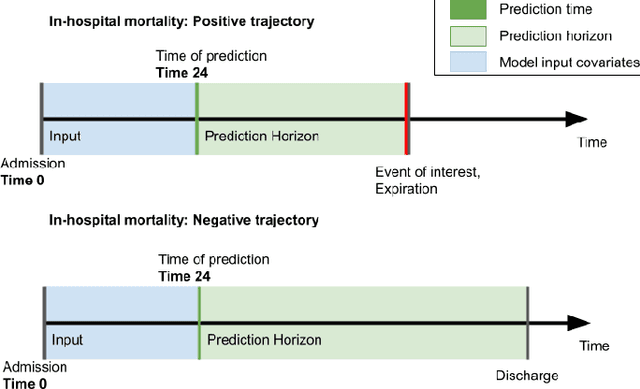
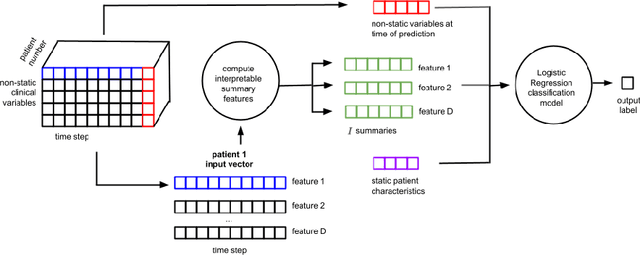
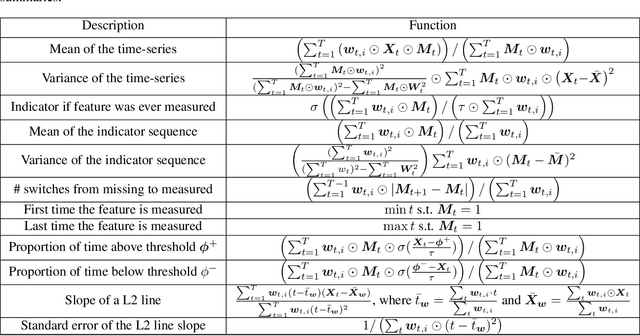
Machine learning models that utilize patient data across time (rather than just the most recent measurements) have increased performance for many risk stratification tasks in the intensive care unit. However, many of these models and their learned representations are complex and therefore difficult for clinicians to interpret, creating challenges for validation. Our work proposes a new procedure to learn summaries of clinical time-series that are both predictive and easily understood by humans. Specifically, our summaries consist of simple and intuitive functions of clinical data (e.g. falling mean arterial pressure). Our learned summaries outperform traditional interpretable model classes and achieve performance comparable to state-of-the-art deep learning models on an in-hospital mortality classification task.
Benchmarks, Algorithms, and Metrics for Hierarchical Disentanglement
Feb 09, 2021

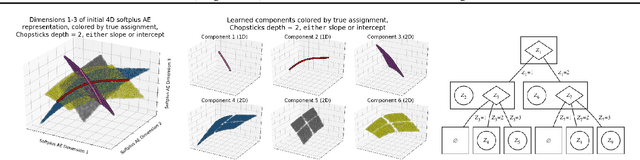
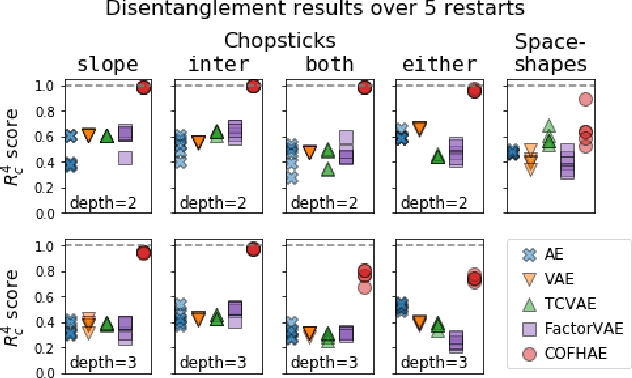
In representation learning, there has been recent interest in developing algorithms to disentangle the ground-truth generative factors behind data, and metrics to quantify how fully this occurs. However, these algorithms and metrics often assume that both representations and ground-truth factors are flat, continuous, and factorized, whereas many real-world generative processes involve rich hierarchical structure, mixtures of discrete and continuous variables with dependence between them, and even varying intrinsic dimensionality. In this work, we develop benchmarks, algorithms, and metrics for learning such hierarchical representations.
Evaluating the Interpretability of Generative Models by Interactive Reconstruction
Feb 02, 2021


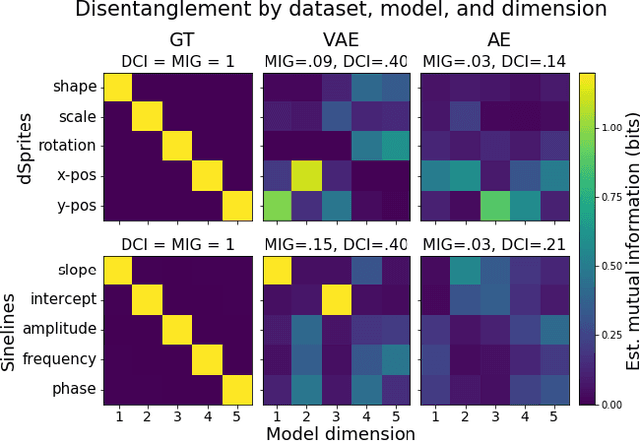
For machine learning models to be most useful in numerous sociotechnical systems, many have argued that they must be human-interpretable. However, despite increasing interest in interpretability, there remains no firm consensus on how to measure it. This is especially true in representation learning, where interpretability research has focused on "disentanglement" measures only applicable to synthetic datasets and not grounded in human factors. We introduce a task to quantify the human-interpretability of generative model representations, where users interactively modify representations to reconstruct target instances. On synthetic datasets, we find performance on this task much more reliably differentiates entangled and disentangled models than baseline approaches. On a real dataset, we find it differentiates between representation learning methods widely believed but never shown to produce more or less interpretable models. In both cases, we ran small-scale think-aloud studies and large-scale experiments on Amazon Mechanical Turk to confirm that our qualitative and quantitative results agreed.
Ensembles of Locally Independent Prediction Models
Nov 27, 2019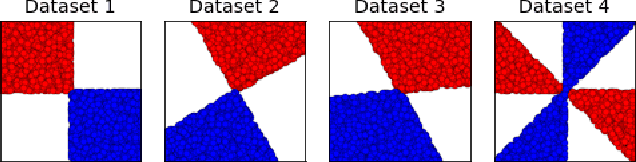
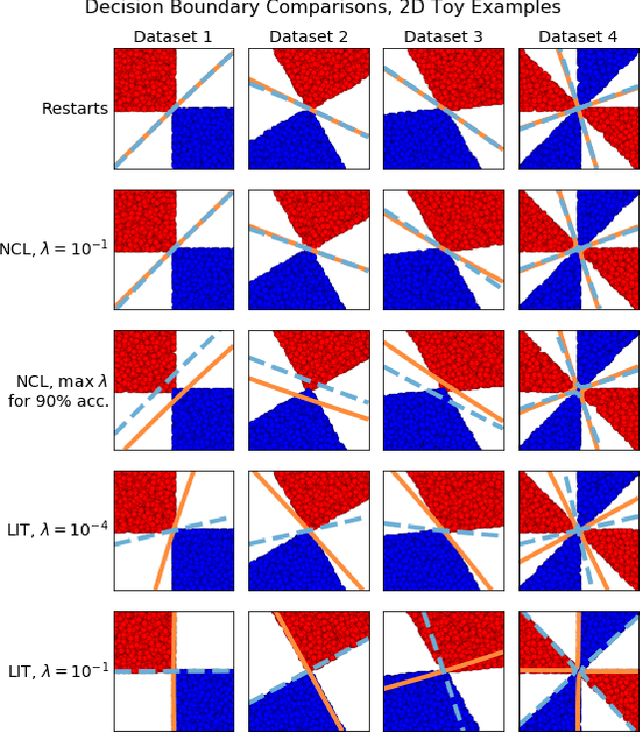
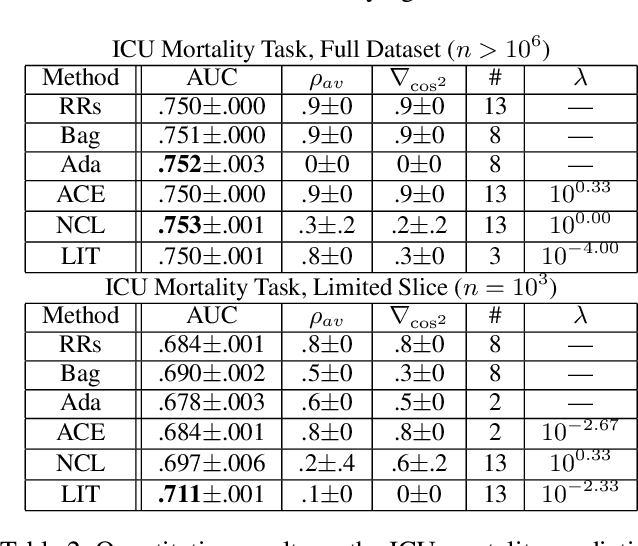
Ensembles depend on diversity for improved performance. Many ensemble training methods, therefore, attempt to optimize for diversity, which they almost always define in terms of differences in training set predictions. In this paper, however, we demonstrate the diversity of predictions on the training set does not necessarily imply diversity under mild covariate shift, which can harm generalization in practical settings. To address this issue, we introduce a new diversity metric and associated method of training ensembles of models that extrapolate differently on local patches of the data manifold. Across a variety of synthetic and real-world tasks, we find that our method improves generalization and diversity in qualitatively novel ways, especially under data limits and covariate shift.
Tackling Climate Change with Machine Learning
Jun 10, 2019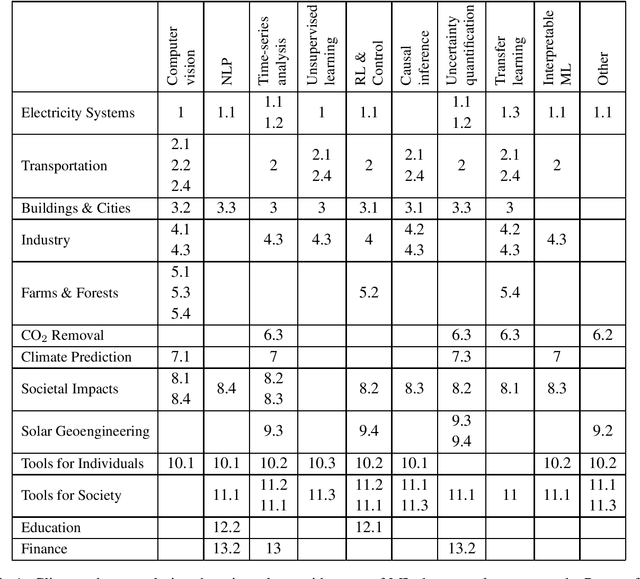
Climate change is one of the greatest challenges facing humanity, and we, as machine learning experts, may wonder how we can help. Here we describe how machine learning can be a powerful tool in reducing greenhouse gas emissions and helping society adapt to a changing climate. From smart grids to disaster management, we identify high impact problems where existing gaps can be filled by machine learning, in collaboration with other fields. Our recommendations encompass exciting research questions as well as promising business opportunities. We call on the machine learning community to join the global effort against climate change.
Human-in-the-Loop Interpretability Prior
Oct 30, 2018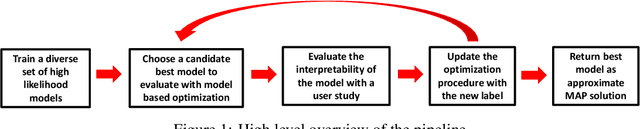
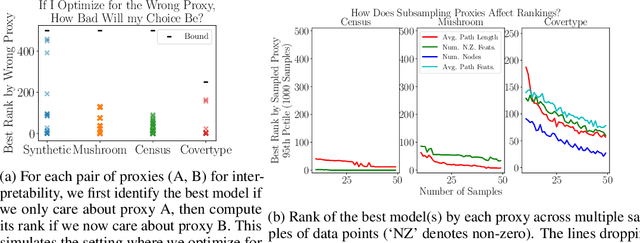
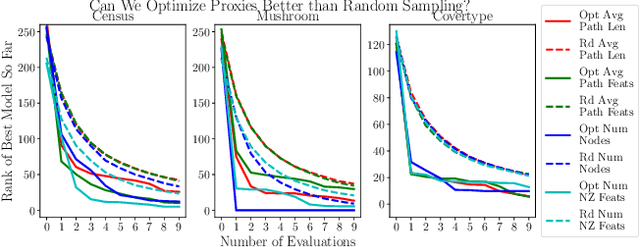
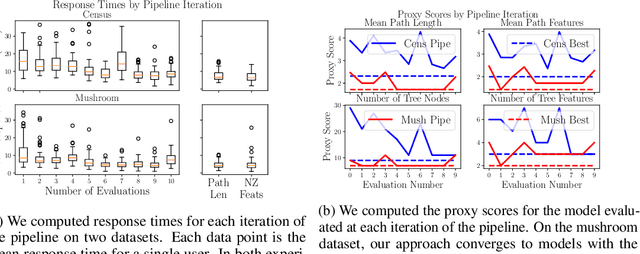
We often desire our models to be interpretable as well as accurate. Prior work on optimizing models for interpretability has relied on easy-to-quantify proxies for interpretability, such as sparsity or the number of operations required. In this work, we optimize for interpretability by directly including humans in the optimization loop. We develop an algorithm that minimizes the number of user studies to find models that are both predictive and interpretable and demonstrate our approach on several data sets. Our human subjects results show trends towards different proxy notions of interpretability on different datasets, which suggests that different proxies are preferred on different tasks.
Training Machine Learning Models by Regularizing their Explanations
Sep 29, 2018
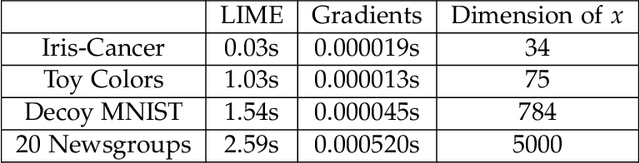
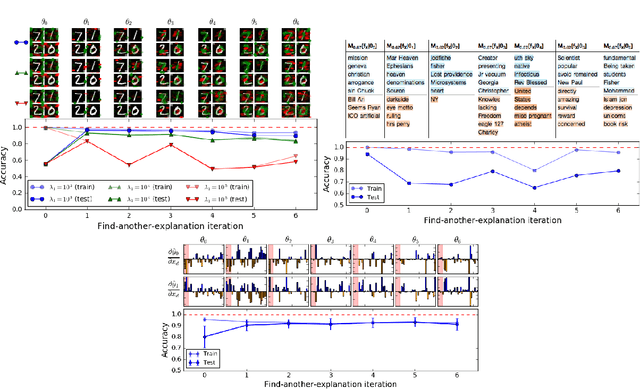

Neural networks are among the most accurate supervised learning methods in use today. However, their opacity makes them difficult to trust in critical applications, especially when conditions in training may differ from those in practice. Recent efforts to develop explanations for neural networks and machine learning models more generally have produced tools to shed light on the implicit rules behind predictions. These tools can help us identify when models are right for the wrong reasons. However, they do not always scale to explaining predictions for entire datasets, are not always at the right level of abstraction, and most importantly cannot correct the problems they reveal. In this thesis, we explore the possibility of training machine learning models (with a particular focus on neural networks) using explanations themselves. We consider approaches where models are penalized not only for making incorrect predictions but also for providing explanations that are either inconsistent with domain knowledge or overly complex. These methods let us train models which can not only provide more interpretable rationales for their predictions but also generalize better when training data is confounded or meaningfully different from test data (even adversarially so).
Learning Qualitatively Diverse and Interpretable Rules for Classification
Jul 19, 2018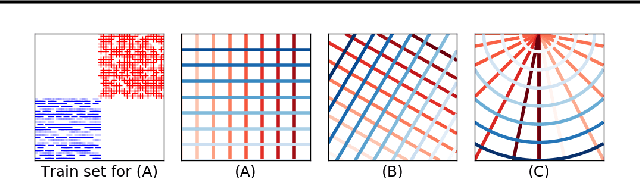
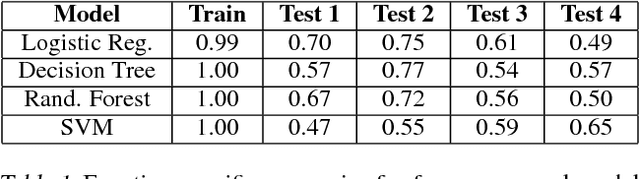
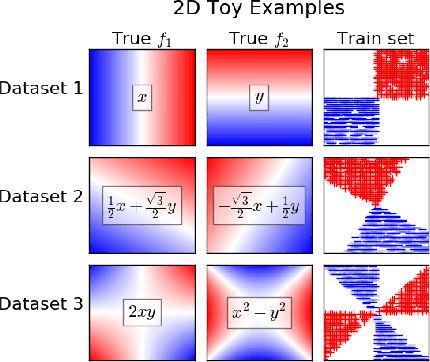
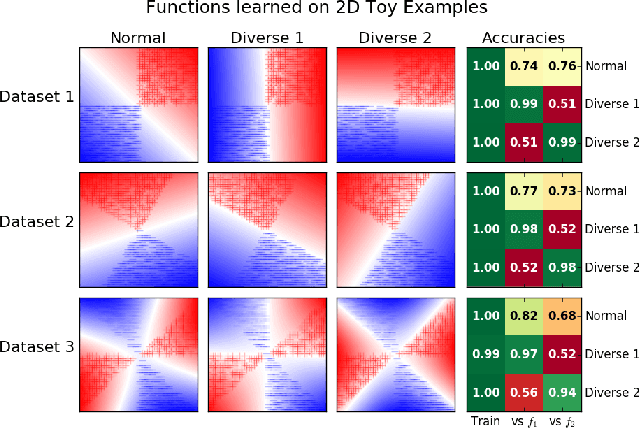
There has been growing interest in developing accurate models that can also be explained to humans. Unfortunately, if there exist multiple distinct but accurate models for some dataset, current machine learning methods are unlikely to find them: standard techniques will likely recover a complex model that combines them. In this work, we introduce a way to identify a maximal set of distinct but accurate models for a dataset. We demonstrate empirically that, in situations where the data supports multiple accurate classifiers, we tend to recover simpler, more interpretable classifiers rather than more complex ones.
Improving the Adversarial Robustness and Interpretability of Deep Neural Networks by Regularizing their Input Gradients
Nov 26, 2017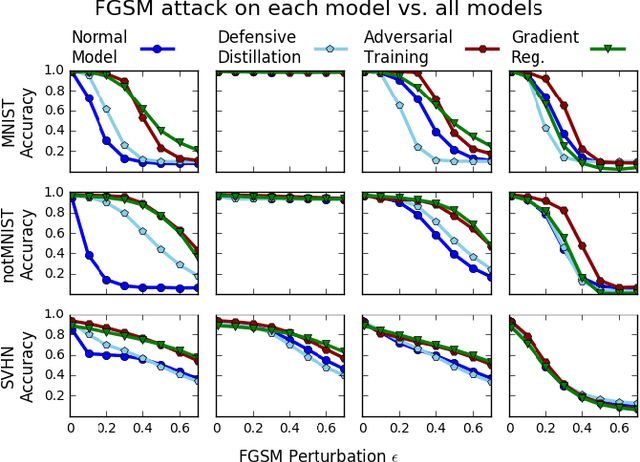

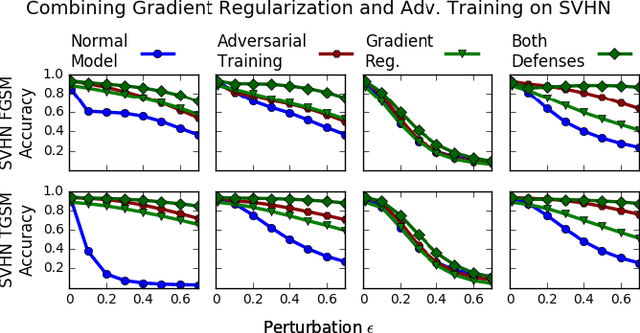
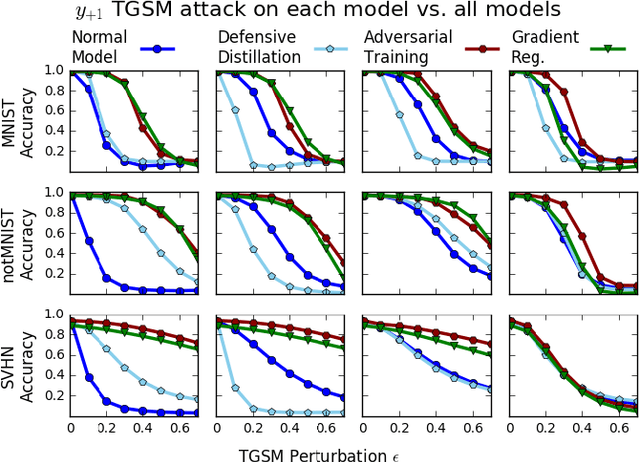
Deep neural networks have proven remarkably effective at solving many classification problems, but have been criticized recently for two major weaknesses: the reasons behind their predictions are uninterpretable, and the predictions themselves can often be fooled by small adversarial perturbations. These problems pose major obstacles for the adoption of neural networks in domains that require security or transparency. In this work, we evaluate the effectiveness of defenses that differentiably penalize the degree to which small changes in inputs can alter model predictions. Across multiple attacks, architectures, defenses, and datasets, we find that neural networks trained with this input gradient regularization exhibit robustness to transferred adversarial examples generated to fool all of the other models. We also find that adversarial examples generated to fool gradient-regularized models fool all other models equally well, and actually lead to more "legitimate," interpretable misclassifications as rated by people (which we confirm in a human subject experiment). Finally, we demonstrate that regularizing input gradients makes them more naturally interpretable as rationales for model predictions. We conclude by discussing this relationship between interpretability and robustness in deep neural networks.
Right for the Right Reasons: Training Differentiable Models by Constraining their Explanations
May 25, 2017
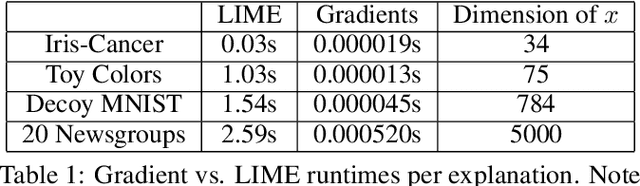
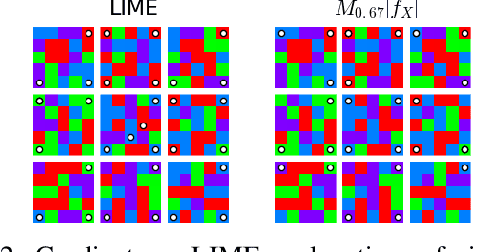
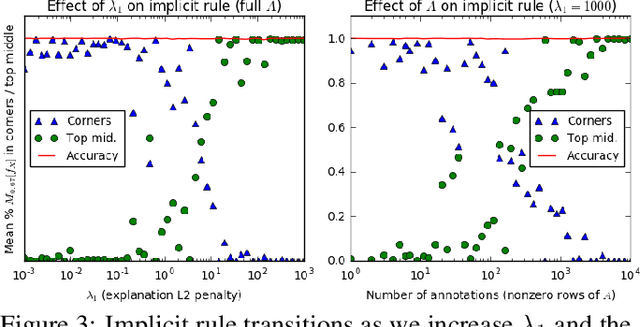
Neural networks are among the most accurate supervised learning methods in use today, but their opacity makes them difficult to trust in critical applications, especially when conditions in training differ from those in test. Recent work on explanations for black-box models has produced tools (e.g. LIME) to show the implicit rules behind predictions, which can help us identify when models are right for the wrong reasons. However, these methods do not scale to explaining entire datasets and cannot correct the problems they reveal. We introduce a method for efficiently explaining and regularizing differentiable models by examining and selectively penalizing their input gradients, which provide a normal to the decision boundary. We apply these penalties both based on expert annotation and in an unsupervised fashion that encourages diverse models with qualitatively different decision boundaries for the same classification problem. On multiple datasets, we show our approach generates faithful explanations and models that generalize much better when conditions differ between training and test.