 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRight for the Right Reasons: Training Differentiable Models by Constraining their Explanations
Paper and Code

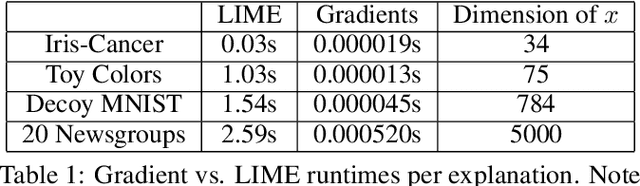
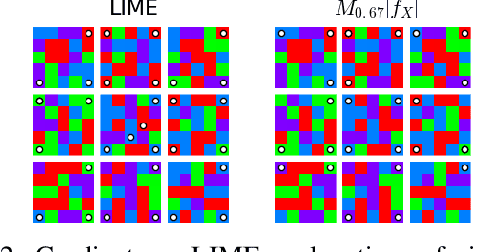
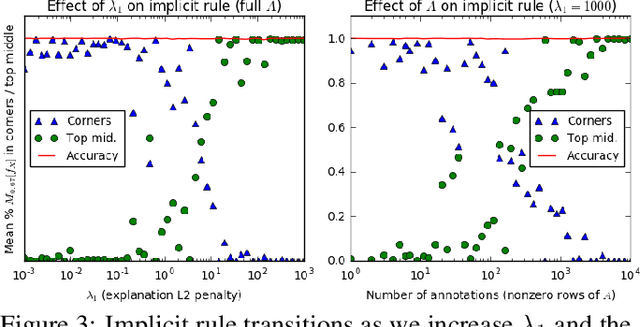
Neural networks are among the most accurate supervised learning methods in use today, but their opacity makes them difficult to trust in critical applications, especially when conditions in training differ from those in test. Recent work on explanations for black-box models has produced tools (e.g. LIME) to show the implicit rules behind predictions, which can help us identify when models are right for the wrong reasons. However, these methods do not scale to explaining entire datasets and cannot correct the problems they reveal. We introduce a method for efficiently explaining and regularizing differentiable models by examining and selectively penalizing their input gradients, which provide a normal to the decision boundary. We apply these penalties both based on expert annotation and in an unsupervised fashion that encourages diverse models with qualitatively different decision boundaries for the same classification problem. On multiple datasets, we show our approach generates faithful explanations and models that generalize much better when conditions differ between training and test.