 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Machine Learning Models by Regularizing their Explanations
Paper and Code

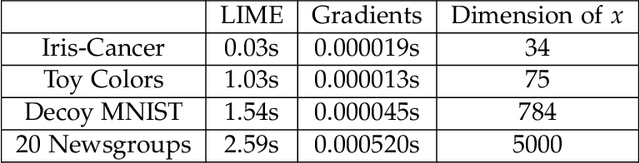
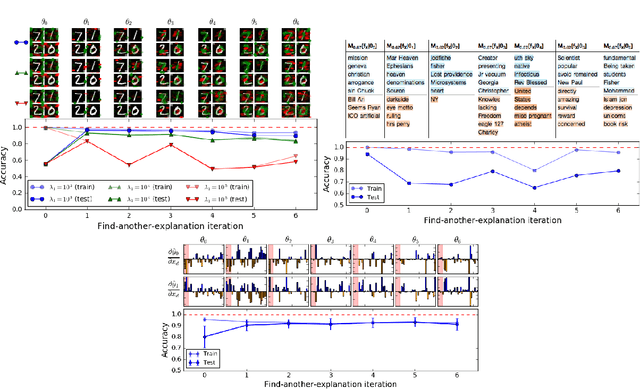

Neural networks are among the most accurate supervised learning methods in use today. However, their opacity makes them difficult to trust in critical applications, especially when conditions in training may differ from those in practice. Recent efforts to develop explanations for neural networks and machine learning models more generally have produced tools to shed light on the implicit rules behind predictions. These tools can help us identify when models are right for the wrong reasons. However, they do not always scale to explaining predictions for entire datasets, are not always at the right level of abstraction, and most importantly cannot correct the problems they reveal. In this thesis, we explore the possibility of training machine learning models (with a particular focus on neural networks) using explanations themselves. We consider approaches where models are penalized not only for making incorrect predictions but also for providing explanations that are either inconsistent with domain knowledge or overly complex. These methods let us train models which can not only provide more interpretable rationales for their predictions but also generalize better when training data is confounded or meaningfully different from test data (even adversarially so).