 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirectly Optimizing Explanations for Desired Properties
Oct 31, 2024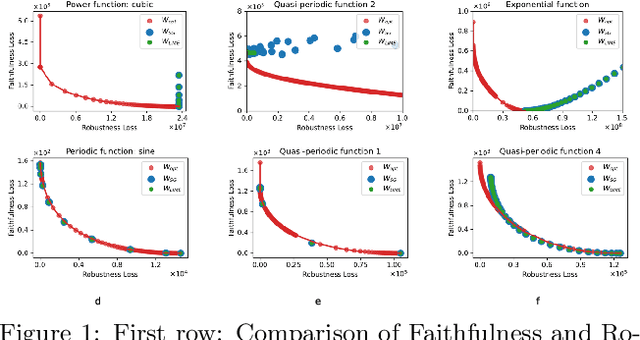
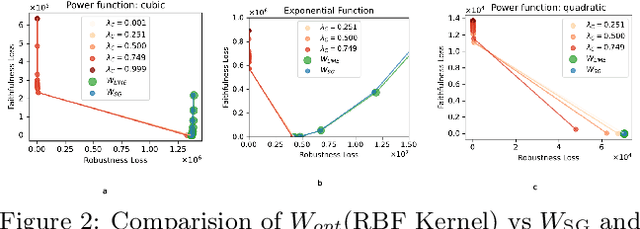
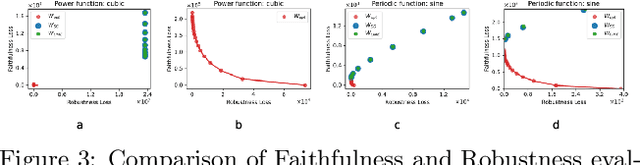
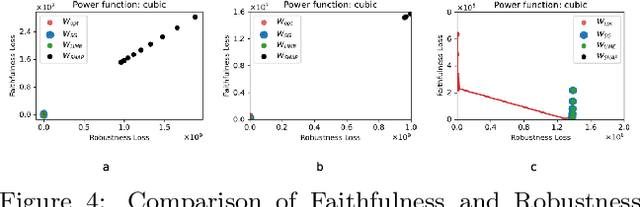
When explaining black-box machine learning models, it's often important for explanations to have certain desirable properties. Most existing methods `encourage' desirable properties in their construction of explanations. In this work, we demonstrate that these forms of encouragement do not consistently create explanations with the properties that are supposedly being targeted. Moreover, they do not allow for any control over which properties are prioritized when different properties are at odds with each other. We propose to directly optimize explanations for desired properties. Our direct approach not only produces explanations with optimal properties more consistently but also empowers users to control trade-offs between different properties, allowing them to create explanations with exactly what is needed for a particular task.
Is What You Ask For What You Get? Investigating Concept Associations in Text-to-Image Models
Oct 06, 2024


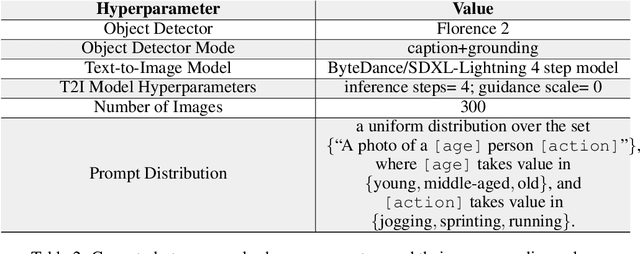
Text-to-image (T2I) models are increasingly used in impactful real-life applications. As such, there is a growing need to audit these models to ensure that they generate desirable, task-appropriate images. However, systematically inspecting the associations between prompts and generated content in a human-understandable way remains challenging. To address this, we propose \emph{Concept2Concept}, a framework where we characterize conditional distributions of vision language models using interpretable concepts and metrics that can be defined in terms of these concepts. This characterization allows us to use our framework to audit models and prompt-datasets. To demonstrate, we investigate several case studies of conditional distributions of prompts, such as user defined distributions or empirical, real world distributions. Lastly, we implement Concept2Concept as an open-source interactive visualization tool facilitating use by non-technical end-users. Warning: This paper contains discussions of harmful content, including CSAM and NSFW material, which may be disturbing to some readers.
A Sim2Real Approach for Identifying Task-Relevant Properties in Interpretable Machine Learning
May 31, 2024
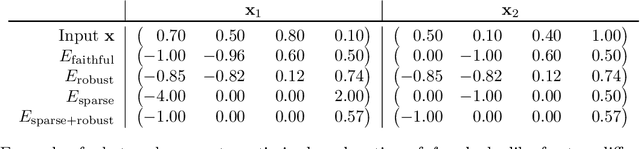


Existing user studies suggest that different tasks may require explanations with different properties. However, user studies are expensive. In this paper, we introduce a generalizable, cost-effective method for identifying task-relevant explanation properties in silico, which can guide the design of more expensive user studies. We use our approach to identify relevant proxies for three example tasks and validate our simulation with real user studies.
Towards Model-Agnostic Posterior Approximation for Fast and Accurate Variational Autoencoders
Mar 13, 2024



Inference for Variational Autoencoders (VAEs) consists of learning two models: (1) a generative model, which transforms a simple distribution over a latent space into the distribution over observed data, and (2) an inference model, which approximates the posterior of the latent codes given data. The two components are learned jointly via a lower bound to the generative model's log marginal likelihood. In early phases of joint training, the inference model poorly approximates the latent code posteriors. Recent work showed that this leads optimization to get stuck in local optima, negatively impacting the learned generative model. As such, recent work suggests ensuring a high-quality inference model via iterative training: maximizing the objective function relative to the inference model before every update to the generative model. Unfortunately, iterative training is inefficient, requiring heuristic criteria for reverting from iterative to joint training for speed. Here, we suggest an inference method that trains the generative and inference models independently. It approximates the posterior of the true model a priori; fixing this posterior approximation, we then maximize the lower bound relative to only the generative model. By conventional wisdom, this approach should rely on the true prior and likelihood of the true model to approximate its posterior (which are unknown). However, we show that we can compute a deterministic, model-agnostic posterior approximation (MAPA) of the true model's posterior. We then use MAPA to develop a proof-of-concept inference method. We present preliminary results on low-dimensional synthetic data that (1) MAPA captures the trend of the true posterior, and (2) our MAPA-based inference performs better density estimation with less computation than baselines. Lastly, we present a roadmap for scaling the MAPA-based inference method to high-dimensional data.
Reinforcement Learning Interventions on Boundedly Rational Human Agents in Frictionful Tasks
Jan 26, 2024Many important behavior changes are frictionful; they require individuals to expend effort over a long period with little immediate gratification. Here, an artificial intelligence (AI) agent can provide personalized interventions to help individuals stick to their goals. In these settings, the AI agent must personalize rapidly (before the individual disengages) and interpretably, to help us understand the behavioral interventions. In this paper, we introduce Behavior Model Reinforcement Learning (BMRL), a framework in which an AI agent intervenes on the parameters of a Markov Decision Process (MDP) belonging to a boundedly rational human agent. Our formulation of the human decision-maker as a planning agent allows us to attribute undesirable human policies (ones that do not lead to the goal) to their maladapted MDP parameters, such as an extremely low discount factor. Furthermore, we propose a class of tractable human models that captures fundamental behaviors in frictionful tasks. Introducing a notion of MDP equivalence specific to BMRL, we theoretically and empirically show that AI planning with our human models can lead to helpful policies on a wide range of more complex, ground-truth humans.
Signature Activation: A Sparse Signal View for Holistic Saliency
Sep 20, 2023The adoption of machine learning in healthcare calls for model transparency and explainability. In this work, we introduce Signature Activation, a saliency method that generates holistic and class-agnostic explanations for Convolutional Neural Network (CNN) outputs. Our method exploits the fact that certain kinds of medical images, such as angiograms, have clear foreground and background objects. We give theoretical explanation to justify our methods. We show the potential use of our method in clinical settings through evaluating its efficacy for aiding the detection of lesions in coronary angiograms.
Why do universal adversarial attacks work on large language models?: Geometry might be the answer
Sep 01, 2023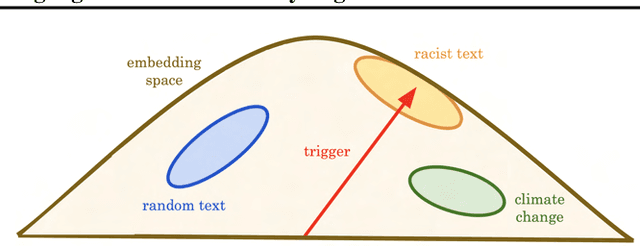
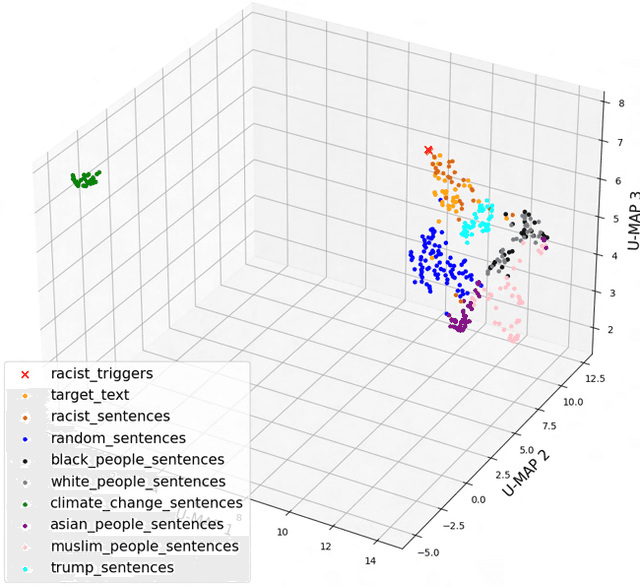
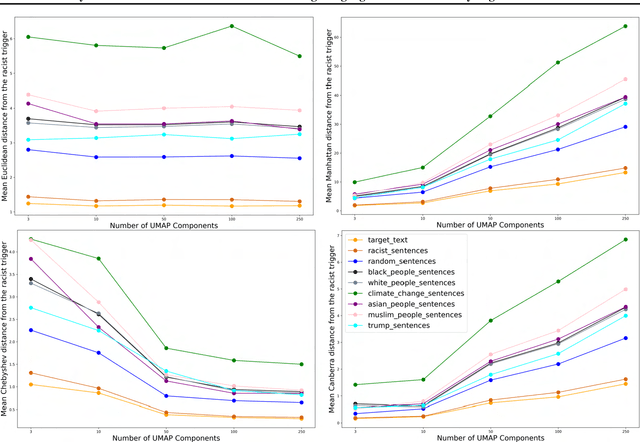
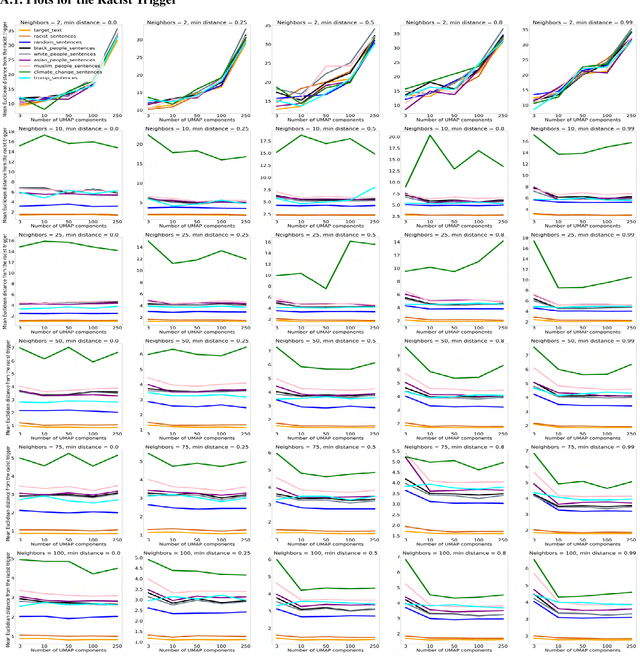
Transformer based large language models with emergent capabilities are becoming increasingly ubiquitous in society. However, the task of understanding and interpreting their internal workings, in the context of adversarial attacks, remains largely unsolved. Gradient-based universal adversarial attacks have been shown to be highly effective on large language models and potentially dangerous due to their input-agnostic nature. This work presents a novel geometric perspective explaining universal adversarial attacks on large language models. By attacking the 117M parameter GPT-2 model, we find evidence indicating that universal adversarial triggers could be embedding vectors which merely approximate the semantic information in their adversarial training region. This hypothesis is supported by white-box model analysis comprising dimensionality reduction and similarity measurement of hidden representations. We believe this new geometric perspective on the underlying mechanism driving universal attacks could help us gain deeper insight into the internal workings and failure modes of LLMs, thus enabling their mitigation.
SAP-sLDA: An Interpretable Interface for Exploring Unstructured Text
Jul 28, 2023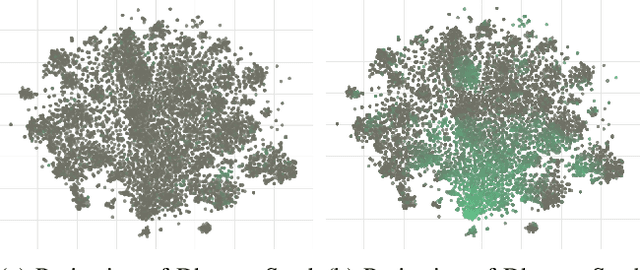



A common way to explore text corpora is through low-dimensional projections of the documents, where one hopes that thematically similar documents will be clustered together in the projected space. However, popular algorithms for dimensionality reduction of text corpora, like Latent Dirichlet Allocation (LDA), often produce projections that do not capture human notions of document similarity. We propose a semi-supervised human-in-the-loop LDA-based method for learning topics that preserve semantically meaningful relationships between documents in low-dimensional projections. On synthetic corpora, our method yields more interpretable projections than baseline methods with only a fraction of labels provided. On a real corpus, we obtain qualitatively similar results.
The Unintended Consequences of Discount Regularization: Improving Regularization in Certainty Equivalence Reinforcement Learning
Jun 20, 2023
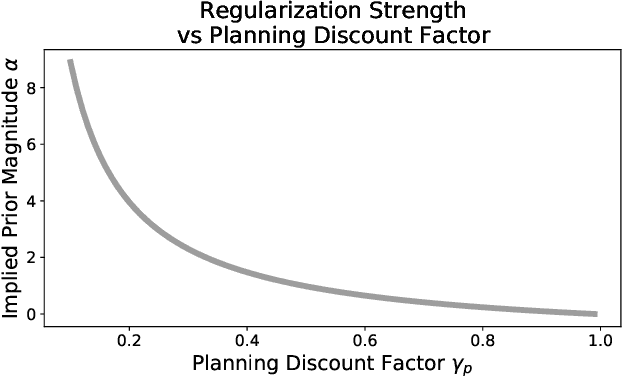


Discount regularization, using a shorter planning horizon when calculating the optimal policy, is a popular choice to restrict planning to a less complex set of policies when estimating an MDP from sparse or noisy data (Jiang et al., 2015). It is commonly understood that discount regularization functions by de-emphasizing or ignoring delayed effects. In this paper, we reveal an alternate view of discount regularization that exposes unintended consequences. We demonstrate that planning under a lower discount factor produces an identical optimal policy to planning using any prior on the transition matrix that has the same distribution for all states and actions. In fact, it functions like a prior with stronger regularization on state-action pairs with more transition data. This leads to poor performance when the transition matrix is estimated from data sets with uneven amounts of data across state-action pairs. Our equivalence theorem leads to an explicit formula to set regularization parameters locally for individual state-action pairs rather than globally. We demonstrate the failures of discount regularization and how we remedy them using our state-action-specific method across simple empirical examples as well as a medical cancer simulator.
Modeling Mobile Health Users as Reinforcement Learning Agents
Dec 01, 2022



Mobile health (mHealth) technologies empower patients to adopt/maintain healthy behaviors in their daily lives, by providing interventions (e.g. push notifications) tailored to the user's needs. In these settings, without intervention, human decision making may be impaired (e.g. valuing near term pleasure over own long term goals). In this work, we formalize this relationship with a framework in which the user optimizes a (potentially impaired) Markov Decision Process (MDP) and the mHealth agent intervenes on the user's MDP parameters. We show that different types of impairments imply different types of optimal intervention. We also provide analytical and empirical explorations of these differences.