 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack to the Baseline: Examining Baseline Effects on Explainability Metrics
Dec 12, 2025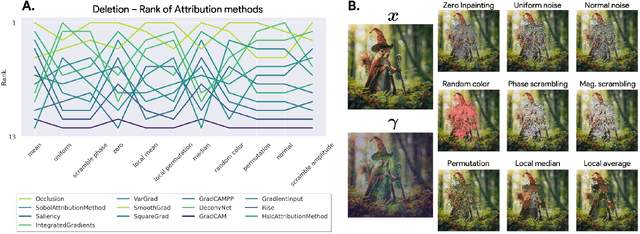
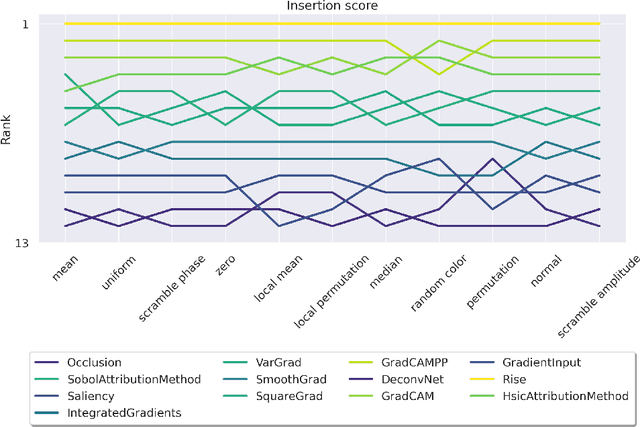
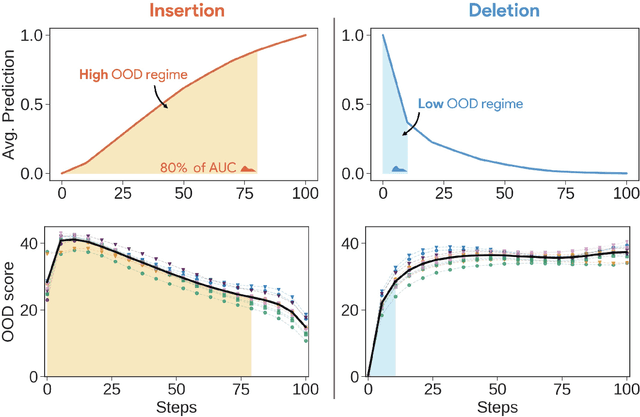
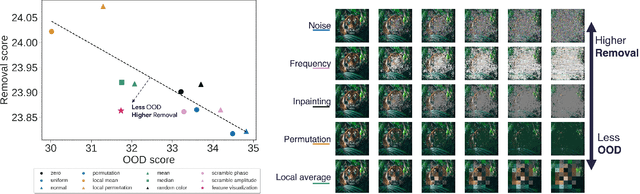
Attribution methods are among the most prevalent techniques in Explainable Artificial Intelligence (XAI) and are usually evaluated and compared using Fidelity metrics, with Insertion and Deletion being the most popular. These metrics rely on a baseline function to alter the pixels of the input image that the attribution map deems most important. In this work, we highlight a critical problem with these metrics: the choice of a given baseline will inevitably favour certain attribution methods over others. More concerningly, even a simple linear model with commonly used baselines contradicts itself by designating different optimal methods. A question then arises: which baseline should we use? We propose to study this problem through two desirable properties of a baseline: (i) that it removes information and (ii) that it does not produce overly out-of-distribution (OOD) images. We first show that none of the tested baselines satisfy both criteria, and there appears to be a trade-off among current baselines: either they remove information or they produce a sequence of OOD images. Finally, we introduce a novel baseline by leveraging recent work in feature visualisation to artificially produce a model-dependent baseline that removes information without being overly OOD, thus improving on the trade-off when compared to other existing baselines. Our code is available at https://github.com/deel-ai-papers/Back-to-the-Baseline
Why do universal adversarial attacks work on large language models?: Geometry might be the answer
Sep 01, 2023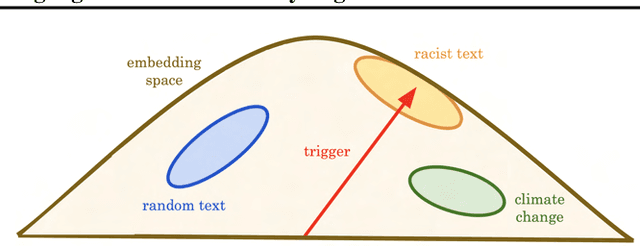
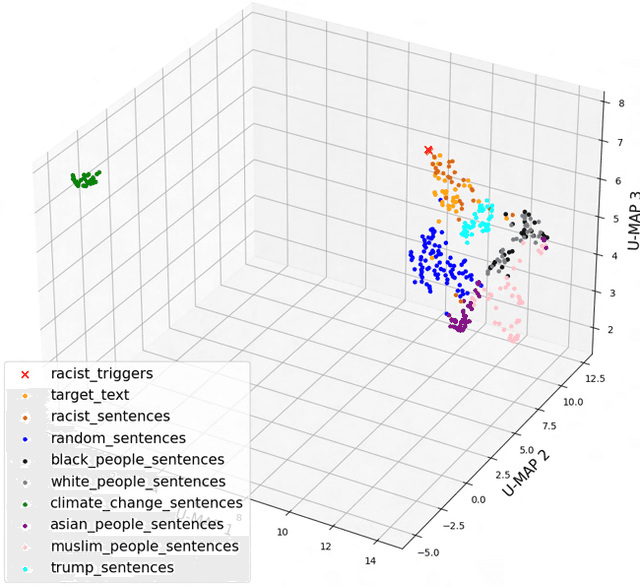
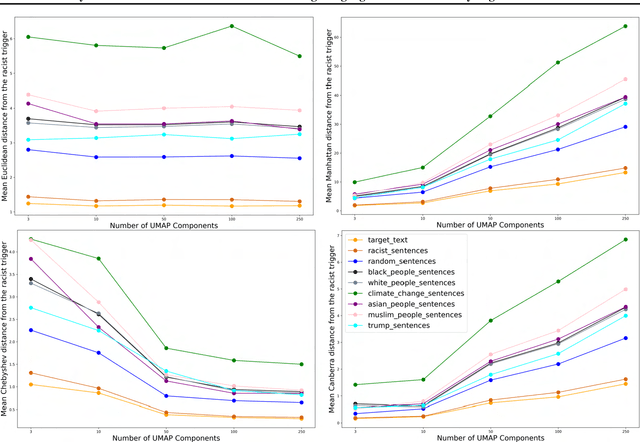
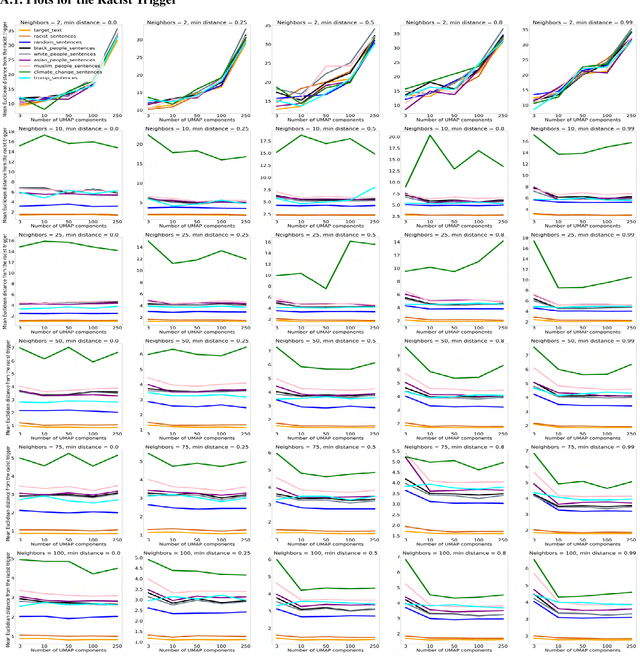
Transformer based large language models with emergent capabilities are becoming increasingly ubiquitous in society. However, the task of understanding and interpreting their internal workings, in the context of adversarial attacks, remains largely unsolved. Gradient-based universal adversarial attacks have been shown to be highly effective on large language models and potentially dangerous due to their input-agnostic nature. This work presents a novel geometric perspective explaining universal adversarial attacks on large language models. By attacking the 117M parameter GPT-2 model, we find evidence indicating that universal adversarial triggers could be embedding vectors which merely approximate the semantic information in their adversarial training region. This hypothesis is supported by white-box model analysis comprising dimensionality reduction and similarity measurement of hidden representations. We believe this new geometric perspective on the underlying mechanism driving universal attacks could help us gain deeper insight into the internal workings and failure modes of LLMs, thus enabling their mitigation.
Does the explanation satisfy your needs?: A unified view of properties of explanations
Nov 10, 2022Interpretability provides a means for humans to verify aspects of machine learning (ML) models and empower human+ML teaming in situations where the task cannot be fully automated. Different contexts require explanations with different properties. For example, the kind of explanation required to determine if an early cardiac arrest warning system is ready to be integrated into a care setting is very different from the type of explanation required for a loan applicant to help determine the actions they might need to take to make their application successful. Unfortunately, there is a lack of standardization when it comes to properties of explanations: different papers may use the same term to mean different quantities, and different terms to mean the same quantity. This lack of a standardized terminology and categorization of the properties of ML explanations prevents us from both rigorously comparing interpretable machine learning methods and identifying what properties are needed in what contexts. In this work, we survey properties defined in interpretable machine learning papers, synthesize them based on what they actually measure, and describe the trade-offs between different formulations of these properties. In doing so, we enable more informed selection of task-appropriate formulations of explanation properties as well as standardization for future work in interpretable machine learning.