 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias at the End of the Score
Apr 14, 2026Reward models (RMs) are inherently non-neutral value functions designed and trained to encode specific objectives, such as human preferences or text-image alignment. RMs have become crucial components of text-to-image (T2I) generation systems where they are used at various stages for dataset filtering, as evaluation metrics, as a supervisory signal during optimization of parameters, and for post-generation safety and quality filtering of T2I outputs. While specific problems with the integration of RMs into the T2I pipeline have been studied (e.g. reward hacking or mode collapse), their robustness and fairness as scoring functions remains largely unknown. We conduct a large scale audit of RM robustness with respect to demographic biases during T2I model training and generation. We provide quantitative and qualitative evidence that while originally developed as quality measures, RMs encode demographic biases, which cause reward-guided optimization to disproportionately sexualize female image subjects reinforce gender/racial stereotypes, and collapse demographic diversity. These findings highlight shortcomings in current reward models, challenge their reliability as quality metrics, and underscore the need for improved data collection and training procedures to enable more robust scoring.
When Visuals Aren't the Problem: Evaluating Vision-Language Models on Misleading Data Visualizations
Mar 23, 2026Visualizations help communicate data insights, but deceptive data representations can distort their interpretation and propagate misinformation. While recent Vision Language Models (VLMs) perform well on many chart understanding tasks, their ability to detect misleading visualizations, especially when deception arises from subtle reasoning errors in captions, remains poorly understood. Here, we evaluate VLMs on misleading visualization-caption pairs grounded in a fine-grained taxonomy of reasoning errors (e.g., Cherry-picking, Causal inference) and visualization design errors (e.g., Truncated axis, Dual axis, inappropriate encodings). To this end, we develop a benchmark that combines real-world visualization with human-authored, curated misleading captions designed to elicit specific reasoning and visualization error types, enabling controlled analysis across error categories and modalities of misleadingness. Evaluating many commercial and open-source VLMs, we find that models detect visual design errors substantially more reliably than reasoning-based misinformation, and frequently misclassify non-misleading visualizations as deceptive. Overall, our work fills a gap between coarse detection of misleading content and the attribution of the specific reasoning or visualization errors that give rise to it.
Understanding Graphical Perception in Data Visualization through Zero-shot Prompting of Vision-Language Models
Oct 31, 2024Vision Language Models (VLMs) have been successful at many chart comprehension tasks that require attending to both the images of charts and their accompanying textual descriptions. However, it is not well established how VLM performance profiles map to human-like behaviors. If VLMs can be shown to have human-like chart comprehension abilities, they can then be applied to a broader range of tasks, such as designing and evaluating visualizations for human readers. This paper lays the foundations for such applications by evaluating the accuracy of zero-shot prompting of VLMs on graphical perception tasks with established human performance profiles. Our findings reveal that VLMs perform similarly to humans under specific task and style combinations, suggesting that they have the potential to be used for modeling human performance. Additionally, variations to the input stimuli show that VLM accuracy is sensitive to stylistic changes such as fill color and chart contiguity, even when the underlying data and data mappings are the same.
Is What You Ask For What You Get? Investigating Concept Associations in Text-to-Image Models
Oct 06, 2024


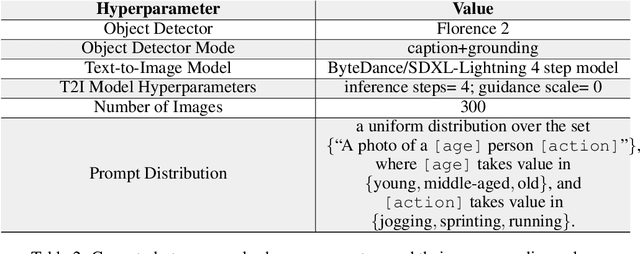
Text-to-image (T2I) models are increasingly used in impactful real-life applications. As such, there is a growing need to audit these models to ensure that they generate desirable, task-appropriate images. However, systematically inspecting the associations between prompts and generated content in a human-understandable way remains challenging. To address this, we propose \emph{Concept2Concept}, a framework where we characterize conditional distributions of vision language models using interpretable concepts and metrics that can be defined in terms of these concepts. This characterization allows us to use our framework to audit models and prompt-datasets. To demonstrate, we investigate several case studies of conditional distributions of prompts, such as user defined distributions or empirical, real world distributions. Lastly, we implement Concept2Concept as an open-source interactive visualization tool facilitating use by non-technical end-users. Warning: This paper contains discussions of harmful content, including CSAM and NSFW material, which may be disturbing to some readers.
MiMICRI: Towards Domain-centered Counterfactual Explanations of Cardiovascular Image Classification Models
Apr 24, 2024



The recent prevalence of publicly accessible, large medical imaging datasets has led to a proliferation of artificial intelligence (AI) models for cardiovascular image classification and analysis. At the same time, the potentially significant impacts of these models have motivated the development of a range of explainable AI (XAI) methods that aim to explain model predictions given certain image inputs. However, many of these methods are not developed or evaluated with domain experts, and explanations are not contextualized in terms of medical expertise or domain knowledge. In this paper, we propose a novel framework and python library, MiMICRI, that provides domain-centered counterfactual explanations of cardiovascular image classification models. MiMICRI helps users interactively select and replace segments of medical images that correspond to morphological structures. From the counterfactuals generated, users can then assess the influence of each segment on model predictions, and validate the model against known medical facts. We evaluate this library with two medical experts. Our evaluation demonstrates that a domain-centered XAI approach can enhance the interpretability of model explanations, and help experts reason about models in terms of relevant domain knowledge. However, concerns were also surfaced about the clinical plausibility of the counterfactuals generated. We conclude with a discussion on the generalizability and trustworthiness of the MiMICRI framework, as well as the implications of our findings on the development of domain-centered XAI methods for model interpretability in healthcare contexts.
Should We Trust AI? Design Dimensions for Structured Experimental Evaluations
Sep 14, 2020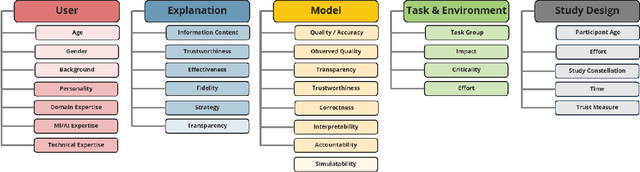
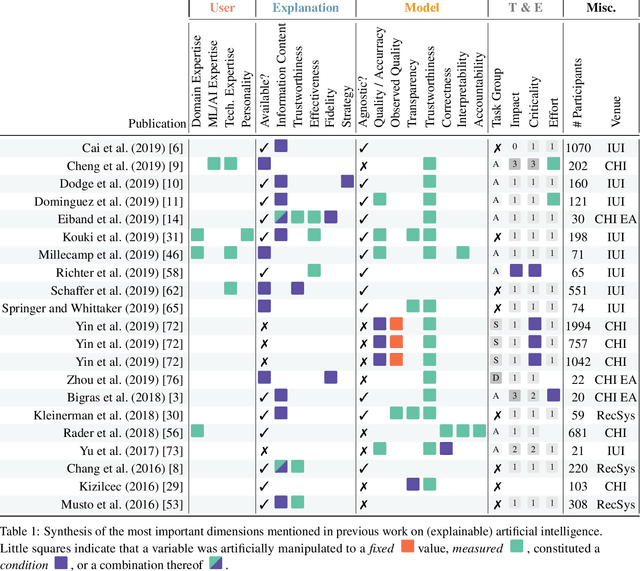
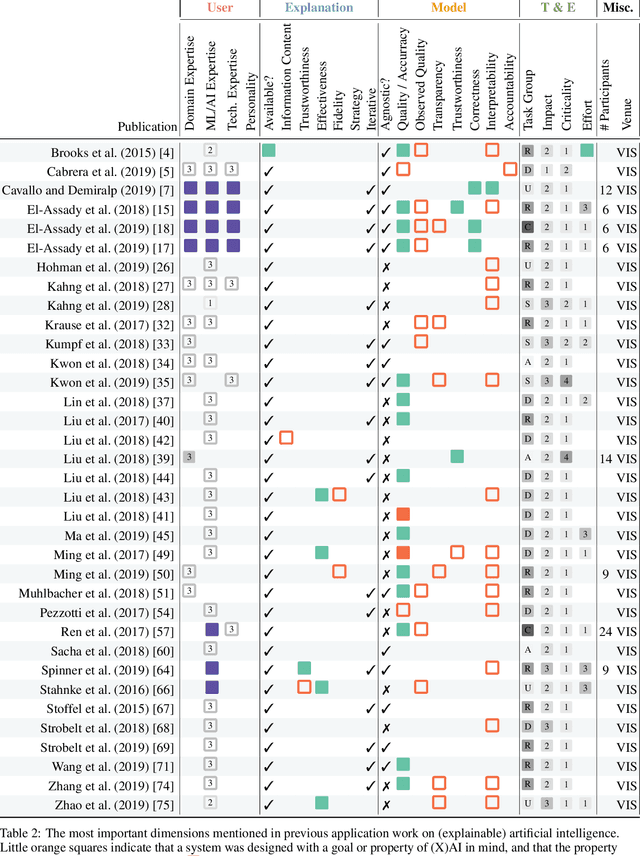
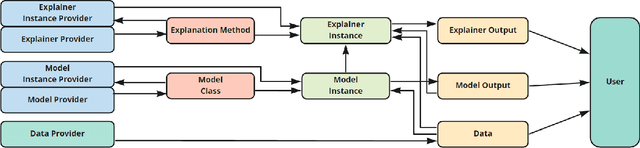
This paper systematically derives design dimensions for the structured evaluation of explainable artificial intelligence (XAI) approaches. These dimensions enable a descriptive characterization, facilitating comparisons between different study designs. They further structure the design space of XAI, converging towards a precise terminology required for a rigorous study of XAI. Our literature review differentiates between comparative studies and application papers, revealing methodological differences between the fields of machine learning, human-computer interaction, and visual analytics. Generally, each of these disciplines targets specific parts of the XAI process. Bridging the resulting gaps enables a holistic evaluation of XAI in real-world scenarios, as proposed by our conceptual model characterizing bias sources and trust-building. Furthermore, we identify and discuss the potential for future work based on observed research gaps that should lead to better coverage of the proposed model.