 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategically Linked Decisions in Long-Term Planning and Reinforcement Learning
May 22, 2025Long-term planning, as in reinforcement learning (RL), involves finding strategies: actions that collectively work toward a goal rather than individually optimizing their immediate outcomes. As part of a strategy, some actions are taken at the expense of short-term benefit to enable future actions with even greater returns. These actions are only advantageous if followed up by the actions they facilitate, consequently, they would not have been taken if those follow-ups were not available. In this paper, we quantify such dependencies between planned actions with strategic link scores: the drop in the likelihood of one decision under the constraint that a follow-up decision is no longer available. We demonstrate the utility of strategic link scores through three practical applications: (i) explaining black-box RL agents by identifying strategically linked pairs among decisions they make, (ii) improving the worst-case performance of decision support systems by distinguishing whether recommended actions can be adopted as standalone improvements or whether they are strategically linked hence requiring a commitment to a broader strategy to be effective, and (iii) characterizing the planning processes of non-RL agents purely through interventions aimed at measuring strategic link scores - as an example, we consider a realistic traffic simulator and analyze through road closures the effective planning horizon of the emergent routing behavior of many drivers.
Towards Regulatory-Confirmed Adaptive Clinical Trials: Machine Learning Opportunities and Solutions
Mar 12, 2025



Randomized Controlled Trials (RCTs) are the gold standard for evaluating the effect of new medical treatments. Treatments must pass stringent regulatory conditions in order to be approved for widespread use, yet even after the regulatory barriers are crossed, real-world challenges might arise: Who should get the treatment? What is its true clinical utility? Are there discrepancies in the treatment effectiveness across diverse and under-served populations? We introduce two new objectives for future clinical trials that integrate regulatory constraints and treatment policy value for both the entire population and under-served populations, thus answering some of the questions above in advance. Designed to meet these objectives, we formulate Randomize First Augment Next (RFAN), a new framework for designing Phase III clinical trials. Our framework consists of a standard randomized component followed by an adaptive one, jointly meant to efficiently and safely acquire and assign patients into treatment arms during the trial. Then, we propose strategies for implementing RFAN based on causal, deep Bayesian active learning. Finally, we empirically evaluate the performance of our framework using synthetic and real-world semi-synthetic datasets.
Compositional Causal Reasoning Evaluation in Language Models
Mar 06, 2025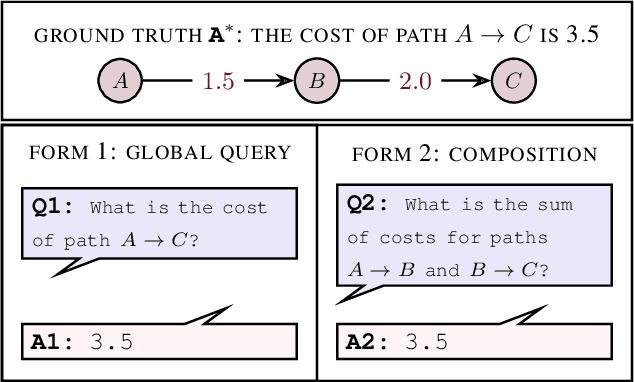

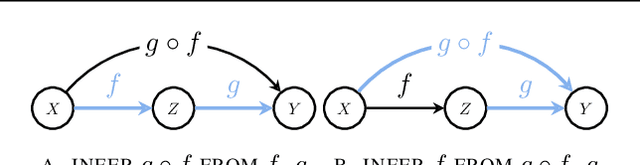

Causal reasoning and compositional reasoning are two core aspirations in generative AI. Measuring the extent of these behaviors requires principled evaluation methods. We explore a unified perspective that considers both behaviors simultaneously, termed compositional causal reasoning (CCR): the ability to infer how causal measures compose and, equivalently, how causal quantities propagate through graphs. We instantiate a framework for the systematic evaluation of CCR for the average treatment effect and the probability of necessity and sufficiency. As proof of concept, we demonstrate the design of CCR tasks for language models in the LLama, Phi, and GPT families. On a math word problem, our framework revealed a range of taxonomically distinct error patterns. Additionally, CCR errors increased with the complexity of causal paths for all models except o1.
Directly Optimizing Explanations for Desired Properties
Oct 31, 2024
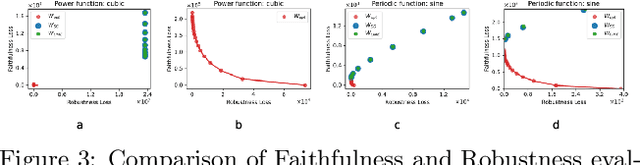
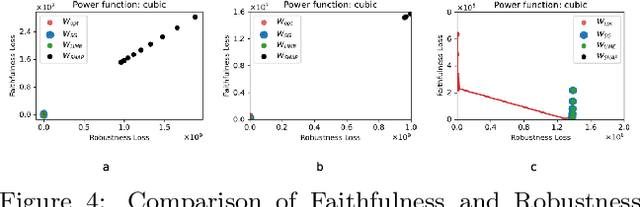
When explaining black-box machine learning models, it's often important for explanations to have certain desirable properties. Most existing methods `encourage' desirable properties in their construction of explanations. In this work, we demonstrate that these forms of encouragement do not consistently create explanations with the properties that are supposedly being targeted. Moreover, they do not allow for any control over which properties are prioritized when different properties are at odds with each other. We propose to directly optimize explanations for desired properties. Our direct approach not only produces explanations with optimal properties more consistently but also empowers users to control trade-offs between different properties, allowing them to create explanations with exactly what is needed for a particular task.
Reasoning Elicitation in Language Models via Counterfactual Feedback
Oct 02, 2024



Despite the increasing effectiveness of language models, their reasoning capabilities remain underdeveloped. In particular, causal reasoning through counterfactual question answering is lacking. This work aims to bridge this gap. We first derive novel metrics that balance accuracy in factual and counterfactual questions, capturing a more complete view of the reasoning abilities of language models than traditional factual-only based metrics. Second, we propose several fine-tuning approaches that aim to elicit better reasoning mechanisms, in the sense of the proposed metrics. Finally, we evaluate the performance of the fine-tuned language models in a variety of realistic scenarios. In particular, we investigate to what extent our fine-tuning approaches systemically achieve better generalization with respect to the base models in several problems that require, among others, inductive and deductive reasoning capabilities.
Defining Expertise: Applications to Treatment Effect Estimation
Mar 01, 2024



Decision-makers are often experts of their domain and take actions based on their domain knowledge. Doctors, for instance, may prescribe treatments by predicting the likely outcome of each available treatment. Actions of an expert thus naturally encode part of their domain knowledge, and can help make inferences within the same domain: Knowing doctors try to prescribe the best treatment for their patients, we can tell treatments prescribed more frequently are likely to be more effective. Yet in machine learning, the fact that most decision-makers are experts is often overlooked, and "expertise" is seldom leveraged as an inductive bias. This is especially true for the literature on treatment effect estimation, where often the only assumption made about actions is that of overlap. In this paper, we argue that expertise - particularly the type of expertise the decision-makers of a domain are likely to have - can be informative in designing and selecting methods for treatment effect estimation. We formally define two types of expertise, predictive and prognostic, and demonstrate empirically that: (i) the prominent type of expertise in a domain significantly influences the performance of different methods in treatment effect estimation, and (ii) it is possible to predict the type of expertise present in a dataset, which can provide a quantitative basis for model selection.
Adaptive Experiment Design with Synthetic Controls
Jan 30, 2024Clinical trials are typically run in order to understand the effects of a new treatment on a given population of patients. However, patients in large populations rarely respond the same way to the same treatment. This heterogeneity in patient responses necessitates trials that investigate effects on multiple subpopulations - especially when a treatment has marginal or no benefit for the overall population but might have significant benefit for a particular subpopulation. Motivated by this need, we propose Syntax, an exploratory trial design that identifies subpopulations with positive treatment effect among many subpopulations. Syntax is sample efficient as it (i) recruits and allocates patients adaptively and (ii) estimates treatment effects by forming synthetic controls for each subpopulation that combines control samples from other subpopulations. We validate the performance of Syntax and provide insights into when it might have an advantage over conventional trial designs through experiments.
When is Off-Policy Evaluation Useful? A Data-Centric Perspective
Nov 23, 2023



Evaluating the value of a hypothetical target policy with only a logged dataset is important but challenging. On the one hand, it brings opportunities for safe policy improvement under high-stakes scenarios like clinical guidelines. On the other hand, such opportunities raise a need for precise off-policy evaluation (OPE). While previous work on OPE focused on improving the algorithm in value estimation, in this work, we emphasize the importance of the offline dataset, hence putting forward a data-centric framework for evaluating OPE problems. We propose DataCOPE, a data-centric framework for evaluating OPE, that answers the questions of whether and to what extent we can evaluate a target policy given a dataset. DataCOPE (1) forecasts the overall performance of OPE algorithms without access to the environment, which is especially useful before real-world deployment where evaluating OPE is impossible; (2) identifies the sub-group in the dataset where OPE can be inaccurate; (3) permits evaluations of datasets or data-collection strategies for OPE problems. Our empirical analysis of DataCOPE in the logged contextual bandit settings using healthcare datasets confirms its ability to evaluate both machine-learning and human expert policies like clinical guidelines.
Online Decision Mediation
Oct 28, 2023

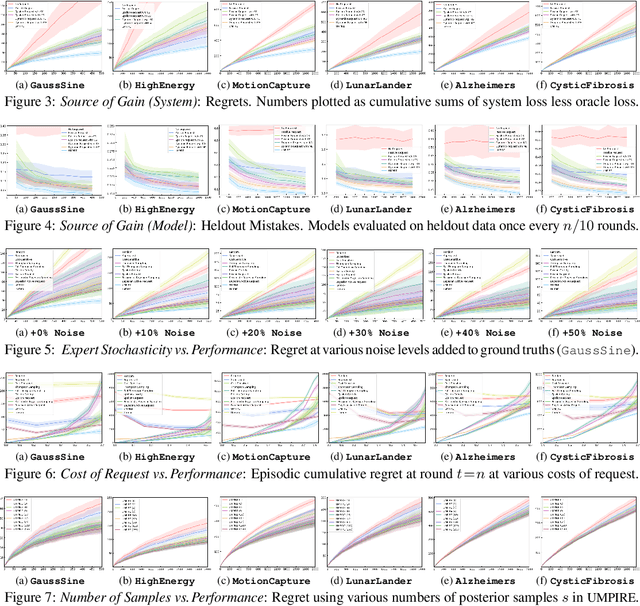
Consider learning a decision support assistant to serve as an intermediary between (oracle) expert behavior and (imperfect) human behavior: At each time, the algorithm observes an action chosen by a fallible agent, and decides whether to *accept* that agent's decision, *intervene* with an alternative, or *request* the expert's opinion. For instance, in clinical diagnosis, fully-autonomous machine behavior is often beyond ethical affordances, thus real-world decision support is often limited to monitoring and forecasting. Instead, such an intermediary would strike a prudent balance between the former (purely prescriptive) and latter (purely descriptive) approaches, while providing an efficient interface between human mistakes and expert feedback. In this work, we first formalize the sequential problem of *online decision mediation* -- that is, of simultaneously learning and evaluating mediator policies from scratch with *abstentive feedback*: In each round, deferring to the oracle obviates the risk of error, but incurs an upfront penalty, and reveals the otherwise hidden expert action as a new training data point. Second, we motivate and propose a solution that seeks to trade off (immediate) loss terms against (future) improvements in generalization error; in doing so, we identify why conventional bandit algorithms may fail. Finally, through experiments and sensitivities on a variety of datasets, we illustrate consistent gains over applicable benchmarks on performance measures with respect to the mediator policy, the learned model, and the decision-making system as a whole.
Explaining by Imitating: Understanding Decisions by Interpretable Policy Learning
Oct 28, 2023



Understanding human behavior from observed data is critical for transparency and accountability in decision-making. Consider real-world settings such as healthcare, in which modeling a decision-maker's policy is challenging -- with no access to underlying states, no knowledge of environment dynamics, and no allowance for live experimentation. We desire learning a data-driven representation of decision-making behavior that (1) inheres transparency by design, (2) accommodates partial observability, and (3) operates completely offline. To satisfy these key criteria, we propose a novel model-based Bayesian method for interpretable policy learning ("Interpole") that jointly estimates an agent's (possibly biased) belief-update process together with their (possibly suboptimal) belief-action mapping. Through experiments on both simulated and real-world data for the problem of Alzheimer's disease diagnosis, we illustrate the potential of our approach as an investigative device for auditing, quantifying, and understanding human decision-making behavior.