Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Qualitatively Diverse and Interpretable Rules for Classification
Paper and Code
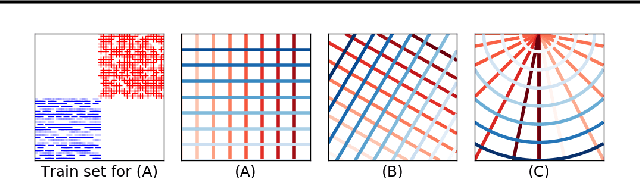
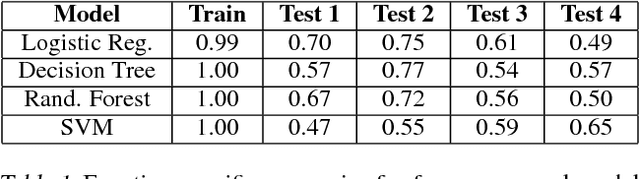
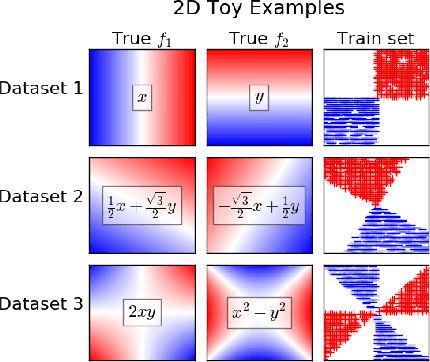
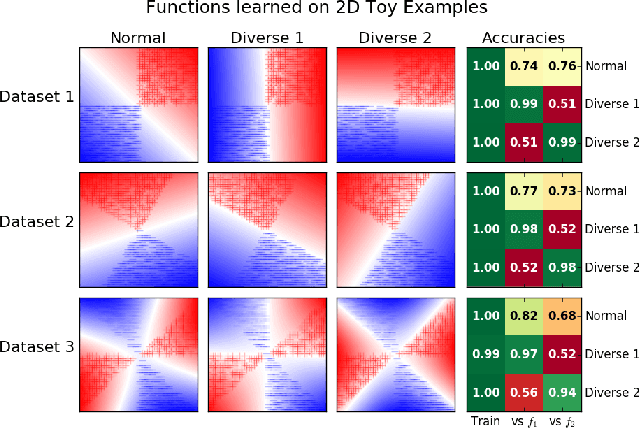
There has been growing interest in developing accurate models that can also be explained to humans. Unfortunately, if there exist multiple distinct but accurate models for some dataset, current machine learning methods are unlikely to find them: standard techniques will likely recover a complex model that combines them. In this work, we introduce a way to identify a maximal set of distinct but accurate models for a dataset. We demonstrate empirically that, in situations where the data supports multiple accurate classifiers, we tend to recover simpler, more interpretable classifiers rather than more complex ones.
* Presented at 2018 ICML Workshop on Human Interpretability in Machine
Learning (WHI 2018), Stockholm, Sweden (revision fixes minor issues)
View paper on