 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsembles of Locally Independent Prediction Models
Paper and Code
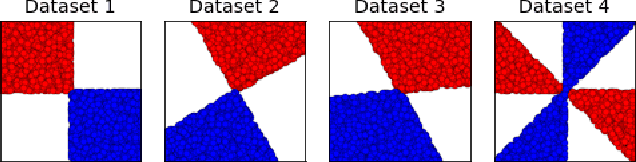
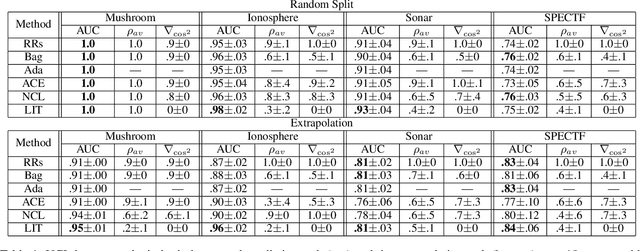
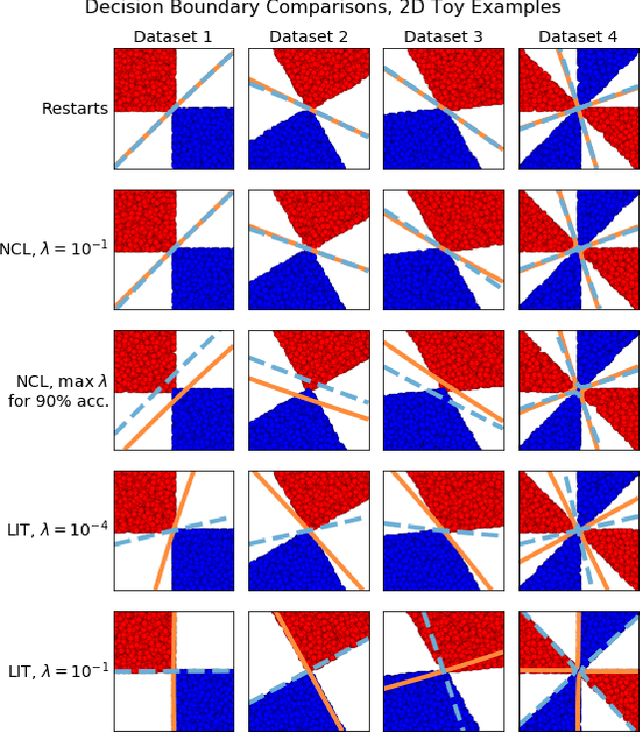
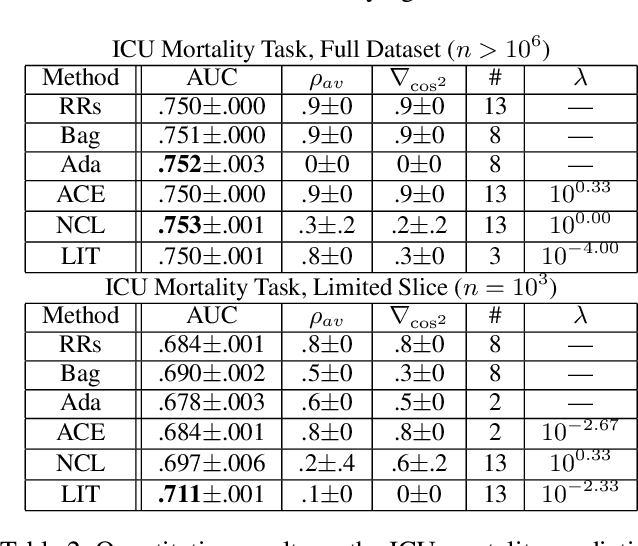
Ensembles depend on diversity for improved performance. Many ensemble training methods, therefore, attempt to optimize for diversity, which they almost always define in terms of differences in training set predictions. In this paper, however, we demonstrate the diversity of predictions on the training set does not necessarily imply diversity under mild covariate shift, which can harm generalization in practical settings. To address this issue, we introduce a new diversity metric and associated method of training ensembles of models that extrapolate differently on local patches of the data manifold. Across a variety of synthetic and real-world tasks, we find that our method improves generalization and diversity in qualitatively novel ways, especially under data limits and covariate shift.