 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstructive Circuit Amplification: Improving Math Reasoning in LLMs via Targeted Sub-Network Updates
Dec 18, 2025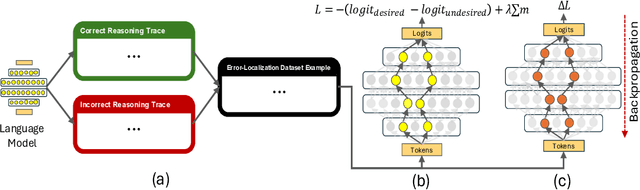
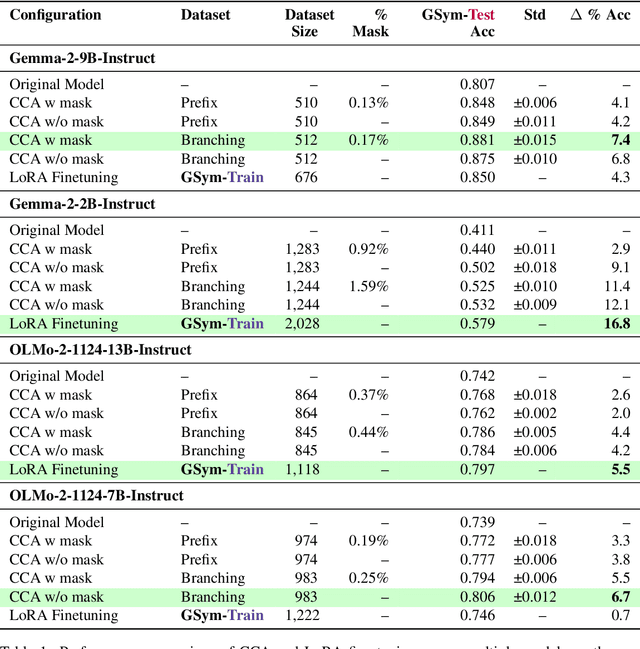

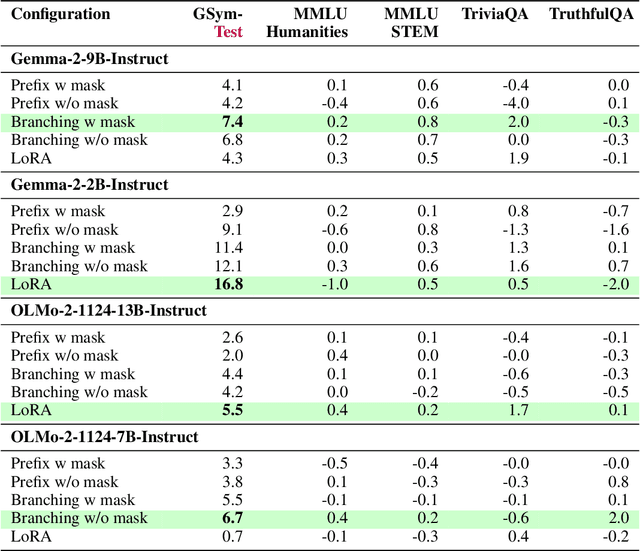
Prior studies investigating the internal workings of LLMs have uncovered sparse subnetworks, often referred to as circuits, that are responsible for performing specific tasks. Additionally, it has been shown that model performance improvement through fine-tuning often results from the strengthening of existing circuits in the model. Taken together, these findings suggest the possibility of intervening directly on such circuits to make precise, task-targeted updates. Motivated by these findings, we propose a novel method called Constructive Circuit Amplification which identifies pivotal tokens from model reasoning traces as well as model components responsible for the desired task, and updates only those components. Applied to mathematical reasoning, it improves accuracy by up to +11.4% across multiple models while modifying as little as 1.59% of model components, with minimal impact on other abilities as measured by MMLU, TriviaQA, and TruthfulQA. These results demonstrate that targeted capabilities can be reliably enhanced by selectively updating a sparse set of model components.
EncQA: Benchmarking Vision-Language Models on Visual Encodings for Charts
Aug 06, 2025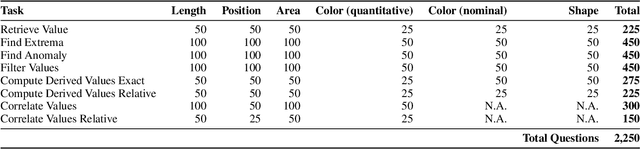


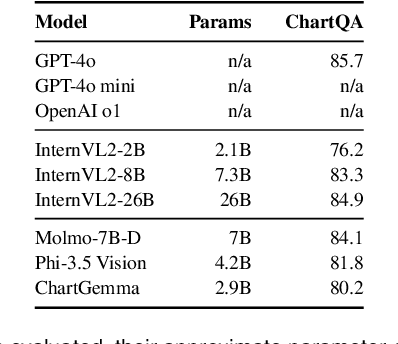
Multimodal vision-language models (VLMs) continue to achieve ever-improving scores on chart understanding benchmarks. Yet, we find that this progress does not fully capture the breadth of visual reasoning capabilities essential for interpreting charts. We introduce EncQA, a novel benchmark informed by the visualization literature, designed to provide systematic coverage of visual encodings and analytic tasks that are crucial for chart understanding. EncQA provides 2,076 synthetic question-answer pairs, enabling balanced coverage of six visual encoding channels (position, length, area, color quantitative, color nominal, and shape) and eight tasks (find extrema, retrieve value, find anomaly, filter values, compute derived value exact, compute derived value relative, correlate values, and correlate values relative). Our evaluation of 9 state-of-the-art VLMs reveals that performance varies significantly across encodings within the same task, as well as across tasks. Contrary to expectations, we observe that performance does not improve with model size for many task-encoding pairs. Our results suggest that advancing chart understanding requires targeted strategies addressing specific visual reasoning gaps, rather than solely scaling up model or dataset size.
Embedding Atlas: Low-Friction, Interactive Embedding Visualization
May 09, 2025



Embedding projections are popular for visualizing large datasets and models. However, people often encounter "friction" when using embedding visualization tools: (1) barriers to adoption, e.g., tedious data wrangling and loading, scalability limits, no integration of results into existing workflows, and (2) limitations in possible analyses, without integration with external tools to additionally show coordinated views of metadata. In this paper, we present Embedding Atlas, a scalable, interactive visualization tool designed to make interacting with large embeddings as easy as possible. Embedding Atlas uses modern web technologies and advanced algorithms -- including density-based clustering, and automated labeling -- to provide a fast and rich data analysis experience at scale. We evaluate Embedding Atlas with a competitive analysis against other popular embedding tools, showing that Embedding Atlas's feature set specifically helps reduce friction, and report a benchmark on its real-time rendering performance with millions of points. Embedding Atlas is available as open source to support future work in embedding-based analysis.
A Scalable Approach to Clustering Embedding Projections
Apr 09, 2025Interactive visualization of embedding projections is a useful technique for understanding data and evaluating machine learning models. Labeling data within these visualizations is critical for interpretation, as labels provide an overview of the projection and guide user navigation. However, most methods for producing labels require clustering the points, which can be computationally expensive as the number of points grows. In this paper, we describe an efficient clustering approach using kernel density estimation in the projected 2D space instead of points. This algorithm can produce high-quality cluster regions from a 2D density map in a few hundred milliseconds, orders of magnitude faster than current approaches. We contribute the design of the algorithm, benchmarks, and applications that demonstrate the utility of the algorithm, including labeling and summarization.
Exploring Empty Spaces: Human-in-the-Loop Data Augmentation
Oct 01, 2024


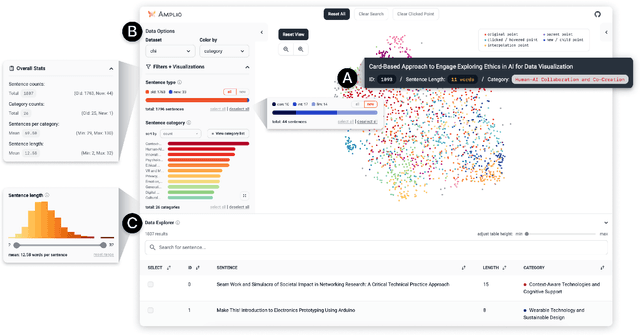
Data augmentation is crucial to make machine learning models more robust and safe. However, augmenting data can be challenging as it requires generating diverse data points to rigorously evaluate model behavior on edge cases and mitigate potential harms. Creating high-quality augmentations that cover these "unknown unknowns" is a time- and creativity-intensive task. In this work, we introduce Amplio, an interactive tool to help practitioners navigate "unknown unknowns" in unstructured text datasets and improve data diversity by systematically identifying empty data spaces to explore. Amplio includes three human-in-the-loop data augmentation techniques: Augment With Concepts, Augment by Interpolation, and Augment with Large Language Model. In a user study with 18 professional red teamers, we demonstrate the utility of our augmentation methods in helping generate high-quality, diverse, and relevant model safety prompts. We find that Amplio enabled red teamers to augment data quickly and creatively, highlighting the transformative potential of interactive augmentation workflows.
AI Policy Projector: Grounding LLM Policy Design in Iterative Mapmaking
Sep 26, 2024Whether a large language model policy is an explicit constitution or an implicit reward model, it is challenging to assess coverage over the unbounded set of real-world situations that a policy must contend with. We introduce an AI policy design process inspired by mapmaking, which has developed tactics for visualizing and iterating on maps even when full coverage is not possible. With Policy Projector, policy designers can survey the landscape of model input-output pairs, define custom regions (e.g., "violence"), and navigate these regions with rules that can be applied to LLM outputs (e.g., if output contains "violence" and "graphic details," then rewrite without "graphic details"). Policy Projector supports interactive policy authoring using LLM classification and steering and a map visualization reflecting the policy designer's work. In an evaluation with 12 AI safety experts, our system helps policy designers to address problematic model behaviors extending beyond an existing, comprehensive harm taxonomy.
Opening the Black Box of 3D Reconstruction Error Analysis with VECTOR
Aug 07, 2024


Reconstruction of 3D scenes from 2D images is a technical challenge that impacts domains from Earth and planetary sciences and space exploration to augmented and virtual reality. Typically, reconstruction algorithms first identify common features across images and then minimize reconstruction errors after estimating the shape of the terrain. This bundle adjustment (BA) step optimizes around a single, simplifying scalar value that obfuscates many possible causes of reconstruction errors (e.g., initial estimate of the position and orientation of the camera, lighting conditions, ease of feature detection in the terrain). Reconstruction errors can lead to inaccurate scientific inferences or endanger a spacecraft exploring a remote environment. To address this challenge, we present VECTOR, a visual analysis tool that improves error inspection for stereo reconstruction BA. VECTOR provides analysts with previously unavailable visibility into feature locations, camera pose, and computed 3D points. VECTOR was developed in partnership with the Perseverance Mars Rover and Ingenuity Mars Helicopter terrain reconstruction team at the NASA Jet Propulsion Laboratory. We report on how this tool was used to debug and improve terrain reconstruction for the Mars 2020 mission.
Compress and Compare: Interactively Evaluating Efficiency and Behavior Across ML Model Compression Experiments
Aug 06, 2024To deploy machine learning models on-device, practitioners use compression algorithms to shrink and speed up models while maintaining their high-quality output. A critical aspect of compression in practice is model comparison, including tracking many compression experiments, identifying subtle changes in model behavior, and negotiating complex accuracy-efficiency trade-offs. However, existing compression tools poorly support comparison, leading to tedious and, sometimes, incomplete analyses spread across disjoint tools. To support real-world comparative workflows, we develop an interactive visual system called Compress and Compare. Within a single interface, Compress and Compare surfaces promising compression strategies by visualizing provenance relationships between compressed models and reveals compression-induced behavior changes by comparing models' predictions, weights, and activations. We demonstrate how Compress and Compare supports common compression analysis tasks through two case studies, debugging failed compression on generative language models and identifying compression artifacts in image classification models. We further evaluate Compress and Compare in a user study with eight compression experts, illustrating its potential to provide structure to compression workflows, help practitioners build intuition about compression, and encourage thorough analysis of compression's effect on model behavior. Through these evaluations, we identify compression-specific challenges that future visual analytics tools should consider and Compress and Compare visualizations that may generalize to broader model comparison tasks.
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
Talaria: Interactively Optimizing Machine Learning Models for Efficient Inference
Apr 03, 2024
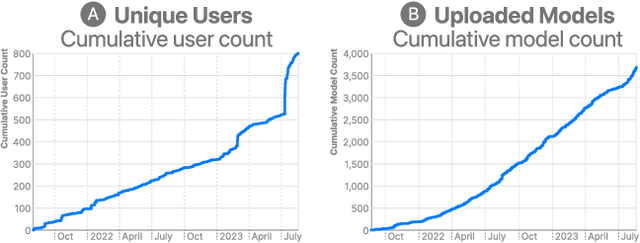
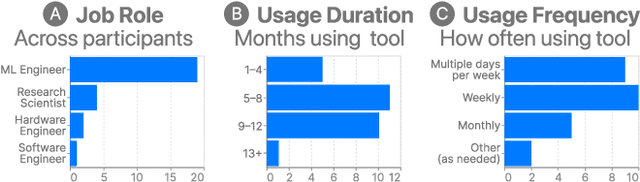
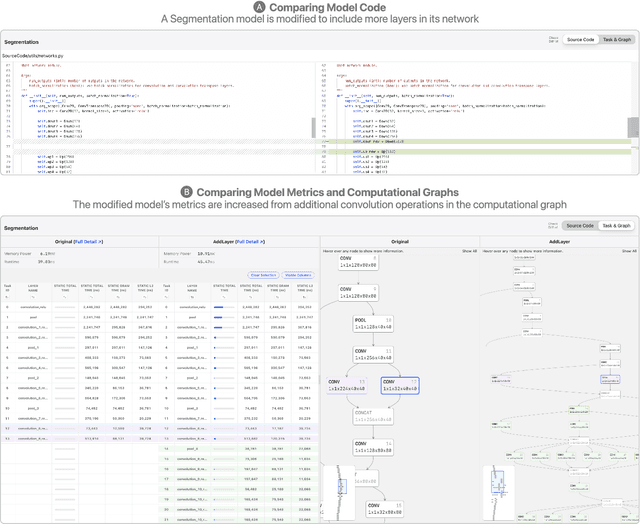
On-device machine learning (ML) moves computation from the cloud to personal devices, protecting user privacy and enabling intelligent user experiences. However, fitting models on devices with limited resources presents a major technical challenge: practitioners need to optimize models and balance hardware metrics such as model size, latency, and power. To help practitioners create efficient ML models, we designed and developed Talaria: a model visualization and optimization system. Talaria enables practitioners to compile models to hardware, interactively visualize model statistics, and simulate optimizations to test the impact on inference metrics. Since its internal deployment two years ago, we have evaluated Talaria using three methodologies: (1) a log analysis highlighting its growth of 800+ practitioners submitting 3,600+ models; (2) a usability survey with 26 users assessing the utility of 20 Talaria features; and (3) a qualitative interview with the 7 most active users about their experience using Talaria.