 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Policy Projector: Grounding LLM Policy Design in Iterative Mapmaking
Sep 26, 2024Whether a large language model policy is an explicit constitution or an implicit reward model, it is challenging to assess coverage over the unbounded set of real-world situations that a policy must contend with. We introduce an AI policy design process inspired by mapmaking, which has developed tactics for visualizing and iterating on maps even when full coverage is not possible. With Policy Projector, policy designers can survey the landscape of model input-output pairs, define custom regions (e.g., "violence"), and navigate these regions with rules that can be applied to LLM outputs (e.g., if output contains "violence" and "graphic details," then rewrite without "graphic details"). Policy Projector supports interactive policy authoring using LLM classification and steering and a map visualization reflecting the policy designer's work. In an evaluation with 12 AI safety experts, our system helps policy designers to address problematic model behaviors extending beyond an existing, comprehensive harm taxonomy.
Model Compression in Practice: Lessons Learned from Practitioners Creating On-device Machine Learning Experiences
Oct 06, 2023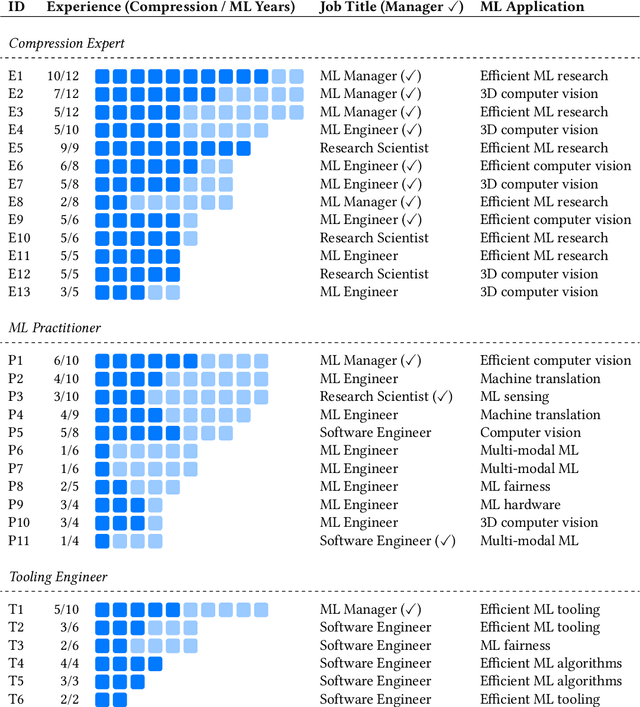



On-device machine learning (ML) promises to improve the privacy, responsiveness, and proliferation of new, intelligent user experiences by moving ML computation onto everyday personal devices. However, today's large ML models must be drastically compressed to run efficiently on-device, a hurtle that requires deep, yet currently niche expertise. To engage the broader human-centered ML community in on-device ML experiences, we present the results from an interview study with 30 experts at Apple that specialize in producing efficient models. We compile tacit knowledge that experts have developed through practical experience with model compression across different hardware platforms. Our findings offer pragmatic considerations missing from prior work, covering the design process, trade-offs, and technical strategies that go into creating efficient models. Finally, we distill design recommendations for tooling to help ease the difficulty of this work and bring on-device ML into to more widespread practice.
Angler: Helping Machine Translation Practitioners Prioritize Model Improvements
Apr 12, 2023



Machine learning (ML) models can fail in unexpected ways in the real world, but not all model failures are equal. With finite time and resources, ML practitioners are forced to prioritize their model debugging and improvement efforts. Through interviews with 13 ML practitioners at Apple, we found that practitioners construct small targeted test sets to estimate an error's nature, scope, and impact on users. We built on this insight in a case study with machine translation models, and developed Angler, an interactive visual analytics tool to help practitioners prioritize model improvements. In a user study with 7 machine translation experts, we used Angler to understand prioritization practices when the input space is infinite, and obtaining reliable signals of model quality is expensive. Our study revealed that participants could form more interesting and user-focused hypotheses for prioritization by analyzing quantitative summary statistics and qualitatively assessing data by reading sentences.
Collaborative Machine Learning Model Building with Families Using Co-ML
Apr 11, 2023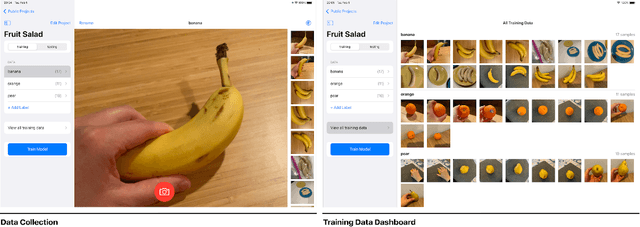
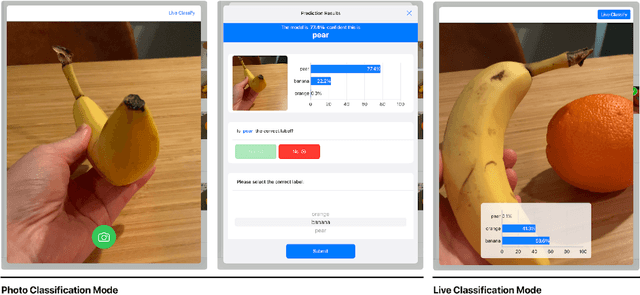
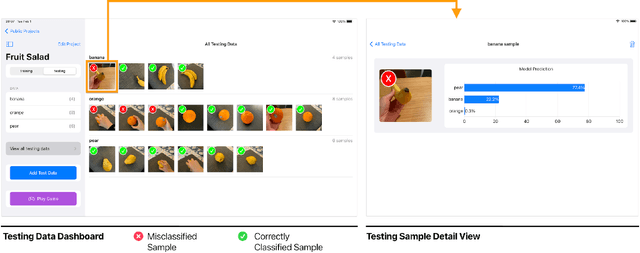
Existing novice-friendly machine learning (ML) modeling tools center around a solo user experience, where a single user collects only their own data to build a model. However, solo modeling experiences limit valuable opportunities for encountering alternative ideas and approaches that can arise when learners work together; consequently, it often precludes encountering critical issues in ML around data representation and diversity that can surface when different perspectives are manifested in a group-constructed data set. To address this issue, we created Co-ML -- a tablet-based app for learners to collaboratively build ML image classifiers through an end-to-end, iterative model-building process. In this paper, we illustrate the feasibility and potential richness of collaborative modeling by presenting an in-depth case study of a family (two children 11 and 14-years-old working with their parents) using Co-ML in a facilitated introductory ML activity at home. We share the Co-ML system design and contribute a discussion of how using Co-ML in a collaborative activity enabled beginners to collectively engage with dataset design considerations underrepresented in prior work such as data diversity, class imbalance, and data quality. We discuss how a distributed collaborative process, in which individuals can take on different model-building responsibilities, provides a rich context for children and adults to learn ML dataset design.