 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do Transformers Learn Variable Binding in Symbolic Programs?
May 27, 2025Variable binding -- the ability to associate variables with values -- is fundamental to symbolic computation and cognition. Although classical architectures typically implement variable binding via addressable memory, it is not well understood how modern neural networks lacking built-in binding operations may acquire this capacity. We investigate this by training a Transformer to dereference queried variables in symbolic programs where variables are assigned either numerical constants or other variables. Each program requires following chains of variable assignments up to four steps deep to find the queried value, and also contains irrelevant chains of assignments acting as distractors. Our analysis reveals a developmental trajectory with three distinct phases during training: (1) random prediction of numerical constants, (2) a shallow heuristic prioritizing early variable assignments, and (3) the emergence of a systematic mechanism for dereferencing assignment chains. Using causal interventions, we find that the model learns to exploit the residual stream as an addressable memory space, with specialized attention heads routing information across token positions. This mechanism allows the model to dynamically track variable bindings across layers, resulting in accurate dereferencing. Our results show how Transformer models can learn to implement systematic variable binding without explicit architectural support, bridging connectionist and symbolic approaches.
A Systematic Review of NeurIPS Dataset Management Practices
Oct 31, 2024
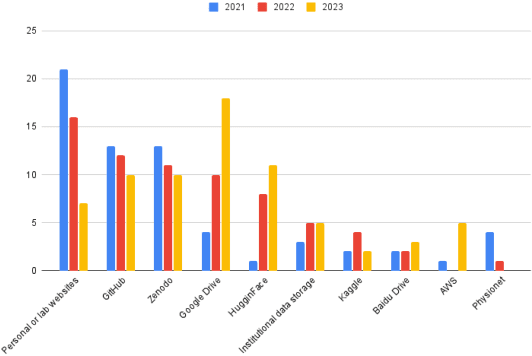


As new machine learning methods demand larger training datasets, researchers and developers face significant challenges in dataset management. Although ethics reviews, documentation, and checklists have been established, it remains uncertain whether consistent dataset management practices exist across the community. This lack of a comprehensive overview hinders our ability to diagnose and address fundamental tensions and ethical issues related to managing large datasets. We present a systematic review of datasets published at the NeurIPS Datasets and Benchmarks track, focusing on four key aspects: provenance, distribution, ethical disclosure, and licensing. Our findings reveal that dataset provenance is often unclear due to ambiguous filtering and curation processes. Additionally, a variety of sites are used for dataset hosting, but only a few offer structured metadata and version control. These inconsistencies underscore the urgent need for standardized data infrastructures for the publication and management of datasets.
CLNX: Bridging Code and Natural Language for C/C++ Vulnerability-Contributing Commits Identification
Sep 11, 2024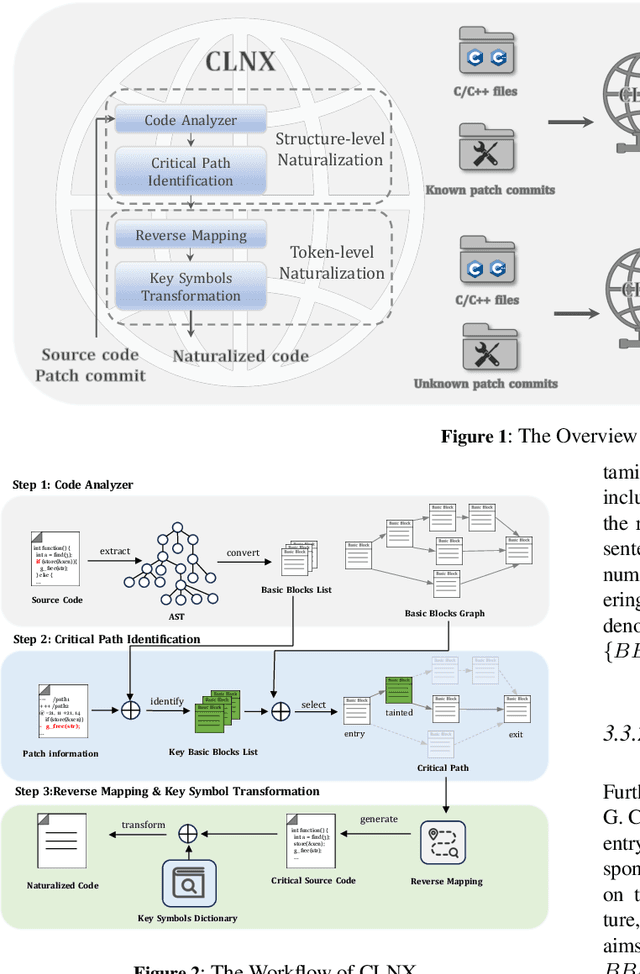
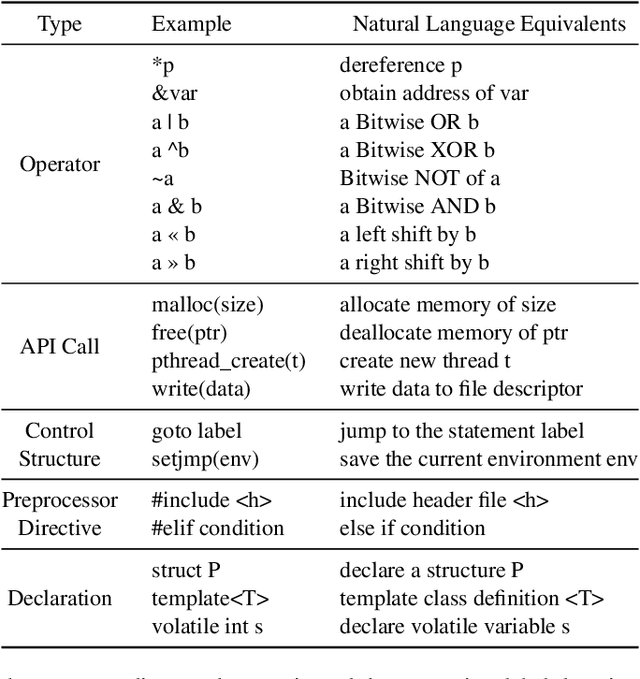
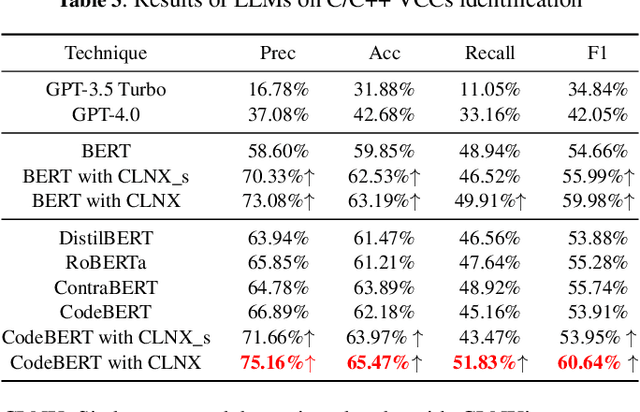
Large Language Models (LLMs) have shown great promise in vulnerability identification. As C/C++ comprises half of the Open-Source Software (OSS) vulnerabilities over the past decade and updates in OSS mainly occur through commits, enhancing LLMs' ability to identify C/C++ Vulnerability-Contributing Commits (VCCs) is essential. However, current studies primarily focus on further pre-training LLMs on massive code datasets, which is resource-intensive and poses efficiency challenges. In this paper, we enhance the ability of BERT-based LLMs to identify C/C++ VCCs in a lightweight manner. We propose CodeLinguaNexus (CLNX) as a bridge facilitating communication between C/C++ programs and LLMs. Based on commits, CLNX efficiently converts the source code into a more natural representation while preserving key details. Specifically, CLNX first applies structure-level naturalization to decompose complex programs, followed by token-level naturalization to interpret complex symbols. We evaluate CLNX on public datasets of 25,872 C/C++ functions with their commits. The results show that CLNX significantly enhances the performance of LLMs on identifying C/C++ VCCs. Moreover, CLNX-equipped CodeBERT achieves new state-of-the-art and identifies 38 OSS vulnerabilities in the real world.
Emblaze: Illuminating Machine Learning Representations through Interactive Comparison of Embedding Spaces
Feb 16, 2022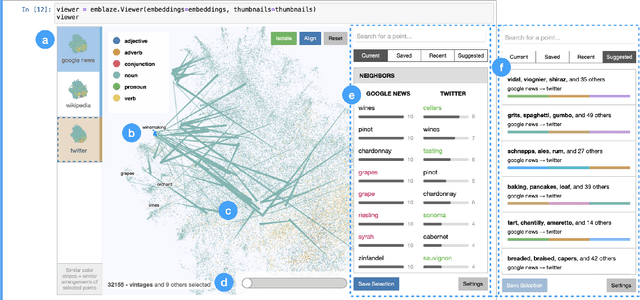


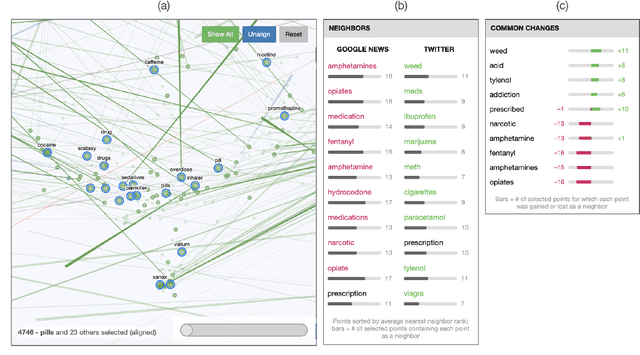
Modern machine learning techniques commonly rely on complex, high-dimensional embedding representations to capture underlying structure in the data and improve performance. In order to characterize model flaws and choose a desirable representation, model builders often need to compare across multiple embedding spaces, a challenging analytical task supported by few existing tools. We first interviewed nine embedding experts in a variety of fields to characterize the diverse challenges they face and techniques they use when analyzing embedding spaces. Informed by these perspectives, we developed a novel system called Emblaze that integrates embedding space comparison within a computational notebook environment. Emblaze uses an animated, interactive scatter plot with a novel Star Trail augmentation to enable visual comparison. It also employs novel neighborhood analysis and clustering procedures to dynamically suggest groups of points with interesting changes between spaces. Through a series of case studies with ML experts, we demonstrate how interactive comparison with Emblaze can help gain new insights into embedding space structure.