 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenHAIV: A Framework Towards Practical Open-World Learning
Aug 10, 2025Substantial progress has been made in various techniques for open-world recognition. Out-of-distribution (OOD) detection methods can effectively distinguish between known and unknown classes in the data, while incremental learning enables continuous model knowledge updates. However, in open-world scenarios, these approaches still face limitations. Relying solely on OOD detection does not facilitate knowledge updates in the model, and incremental fine-tuning typically requires supervised conditions, which significantly deviate from open-world settings. To address these challenges, this paper proposes OpenHAIV, a novel framework that integrates OOD detection, new class discovery, and incremental continual fine-tuning into a unified pipeline. This framework allows models to autonomously acquire and update knowledge in open-world environments. The proposed framework is available at https://haiv-lab.github.io/openhaiv .
A Systematic Review of NeurIPS Dataset Management Practices
Oct 31, 2024
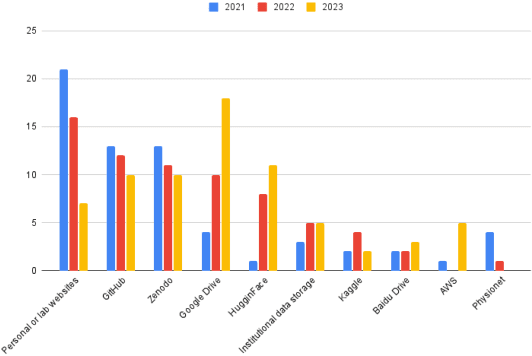


As new machine learning methods demand larger training datasets, researchers and developers face significant challenges in dataset management. Although ethics reviews, documentation, and checklists have been established, it remains uncertain whether consistent dataset management practices exist across the community. This lack of a comprehensive overview hinders our ability to diagnose and address fundamental tensions and ethical issues related to managing large datasets. We present a systematic review of datasets published at the NeurIPS Datasets and Benchmarks track, focusing on four key aspects: provenance, distribution, ethical disclosure, and licensing. Our findings reveal that dataset provenance is often unclear due to ambiguous filtering and curation processes. Additionally, a variety of sites are used for dataset hosting, but only a few offer structured metadata and version control. These inconsistencies underscore the urgent need for standardized data infrastructures for the publication and management of datasets.
Consent in Crisis: The Rapid Decline of the AI Data Commons
Jul 24, 2024


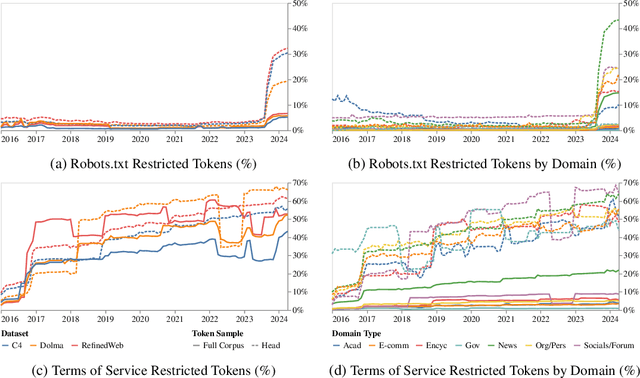
General-purpose artificial intelligence (AI) systems are built on massive swathes of public web data, assembled into corpora such as C4, RefinedWeb, and Dolma. To our knowledge, we conduct the first, large-scale, longitudinal audit of the consent protocols for the web domains underlying AI training corpora. Our audit of 14,000 web domains provides an expansive view of crawlable web data and how codified data use preferences are changing over time. We observe a proliferation of AI-specific clauses to limit use, acute differences in restrictions on AI developers, as well as general inconsistencies between websites' expressed intentions in their Terms of Service and their robots.txt. We diagnose these as symptoms of ineffective web protocols, not designed to cope with the widespread re-purposing of the internet for AI. Our longitudinal analyses show that in a single year (2023-2024) there has been a rapid crescendo of data restrictions from web sources, rendering ~5%+ of all tokens in C4, or 28%+ of the most actively maintained, critical sources in C4, fully restricted from use. For Terms of Service crawling restrictions, a full 45% of C4 is now restricted. If respected or enforced, these restrictions are rapidly biasing the diversity, freshness, and scaling laws for general-purpose AI systems. We hope to illustrate the emerging crises in data consent, for both developers and creators. The foreclosure of much of the open web will impact not only commercial AI, but also non-commercial AI and academic research.