 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Think of the White Bear: Ironic Negation in Transformer Models Under Cognitive Load
Nov 15, 2025Negation instructions such as 'do not mention $X$' can paradoxically increase the accessibility of $X$ in human thought, a phenomenon known as ironic rebound. Large language models (LLMs) face the same challenge: suppressing a concept requires internally activating it, which may prime rebound instead of avoidance. We investigated this tension with two experiments. \textbf{(1) Load \& content}: after a negation instruction, we vary distractor text (semantic, syntactic, repetition) and measure rebound strength. \textbf{(2) Polarity separation}: We test whether models distinguish neutral from negative framings of the same concept and whether this separation predicts rebound persistence. Results show that rebound consistently arises immediately after negation and intensifies with longer or semantic distractors, while repetition supports suppression. Stronger polarity separation correlates with more persistent rebound. Together, these findings, complemented by a circuit tracing analysis that identifies sparse middle-layer attention heads amplifying forbidden tokens while early layers suppress, link cognitive predictions of ironic rebound with mechanistic insights into long-context interference. To support future work, we release ReboundBench, a dataset of $5,000$ systematically varied negation prompts designed to probe rebound in LLMs.
Bridging the Data Provenance Gap Across Text, Speech and Video
Dec 19, 2024



Progress in AI is driven largely by the scale and quality of training data. Despite this, there is a deficit of empirical analysis examining the attributes of well-established datasets beyond text. In this work we conduct the largest and first-of-its-kind longitudinal audit across modalities--popular text, speech, and video datasets--from their detailed sourcing trends and use restrictions to their geographical and linguistic representation. Our manual analysis covers nearly 4000 public datasets between 1990-2024, spanning 608 languages, 798 sources, 659 organizations, and 67 countries. We find that multimodal machine learning applications have overwhelmingly turned to web-crawled, synthetic, and social media platforms, such as YouTube, for their training sets, eclipsing all other sources since 2019. Secondly, tracing the chain of dataset derivations we find that while less than 33% of datasets are restrictively licensed, over 80% of the source content in widely-used text, speech, and video datasets, carry non-commercial restrictions. Finally, counter to the rising number of languages and geographies represented in public AI training datasets, our audit demonstrates measures of relative geographical and multilingual representation have failed to significantly improve their coverage since 2013. We believe the breadth of our audit enables us to empirically examine trends in data sourcing, restrictions, and Western-centricity at an ecosystem-level, and that visibility into these questions are essential to progress in responsible AI. As a contribution to ongoing improvements in dataset transparency and responsible use, we release our entire multimodal audit, allowing practitioners to trace data provenance across text, speech, and video.
Consent in Crisis: The Rapid Decline of the AI Data Commons
Jul 24, 2024


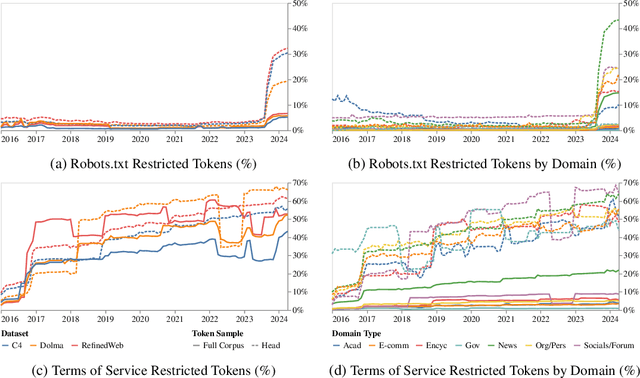
General-purpose artificial intelligence (AI) systems are built on massive swathes of public web data, assembled into corpora such as C4, RefinedWeb, and Dolma. To our knowledge, we conduct the first, large-scale, longitudinal audit of the consent protocols for the web domains underlying AI training corpora. Our audit of 14,000 web domains provides an expansive view of crawlable web data and how codified data use preferences are changing over time. We observe a proliferation of AI-specific clauses to limit use, acute differences in restrictions on AI developers, as well as general inconsistencies between websites' expressed intentions in their Terms of Service and their robots.txt. We diagnose these as symptoms of ineffective web protocols, not designed to cope with the widespread re-purposing of the internet for AI. Our longitudinal analyses show that in a single year (2023-2024) there has been a rapid crescendo of data restrictions from web sources, rendering ~5%+ of all tokens in C4, or 28%+ of the most actively maintained, critical sources in C4, fully restricted from use. For Terms of Service crawling restrictions, a full 45% of C4 is now restricted. If respected or enforced, these restrictions are rapidly biasing the diversity, freshness, and scaling laws for general-purpose AI systems. We hope to illustrate the emerging crises in data consent, for both developers and creators. The foreclosure of much of the open web will impact not only commercial AI, but also non-commercial AI and academic research.
ToDo: Token Downsampling for Efficient Generation of High-Resolution Images
Feb 28, 2024
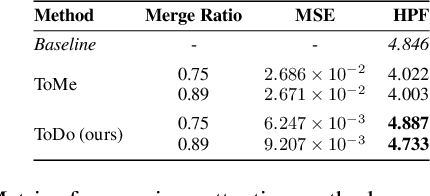

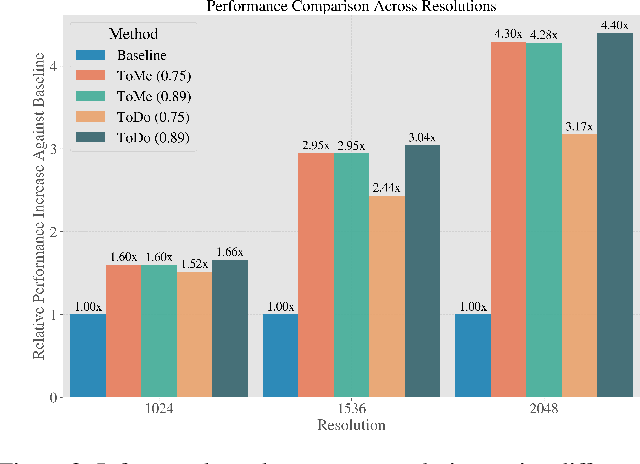
Attention mechanism has been crucial for image diffusion models, however, their quadratic computational complexity limits the sizes of images we can process within reasonable time and memory constraints. This paper investigates the importance of dense attention in generative image models, which often contain redundant features, making them suitable for sparser attention mechanisms. We propose a novel training-free method ToDo that relies on token downsampling of key and value tokens to accelerate Stable Diffusion inference by up to 2x for common sizes and up to 4.5x or more for high resolutions like 2048x2048. We demonstrate that our approach outperforms previous methods in balancing efficient throughput and fidelity.
Towards One Shot Search Space Poisoning in Neural Architecture Search
Nov 13, 2021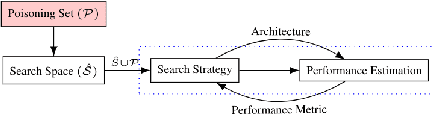

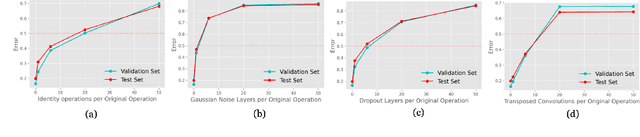
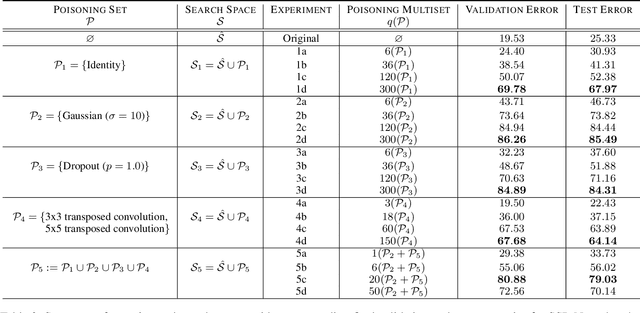
We evaluate the robustness of a Neural Architecture Search (NAS) algorithm known as Efficient NAS (ENAS) against data agnostic poisoning attacks on the original search space with carefully designed ineffective operations. We empirically demonstrate how our one shot search space poisoning approach exploits design flaws in the ENAS controller to degrade predictive performance on classification tasks. With just two poisoning operations injected into the search space, we inflate prediction error rates for child networks upto 90% on the CIFAR-10 dataset.
NeuralArTS: Structuring Neural Architecture Search with Type Theory
Nov 05, 2021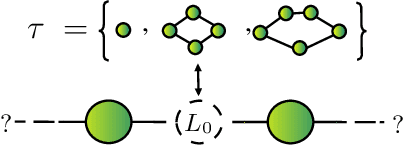

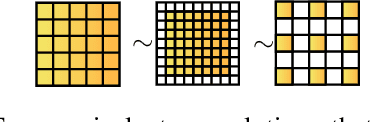
Neural Architecture Search (NAS) algorithms automate the task of finding optimal deep learning architectures given an initial search space of possible operations. Developing these search spaces is usually a manual affair with pre-optimized search spaces being more efficient, rather than searching from scratch. In this paper we present a new framework called Neural Architecture Type System (NeuralArTS) that categorizes the infinite set of network operations in a structured type system. We further demonstrate how NeuralArTS can be applied to convolutional layers and propose several future directions.
Sign-to-Speech Model for Sign Language Understanding: A Case Study of Nigerian Sign Language
Nov 02, 2021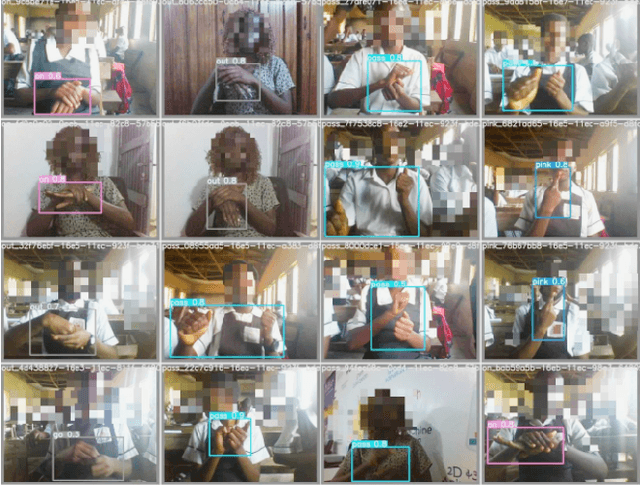
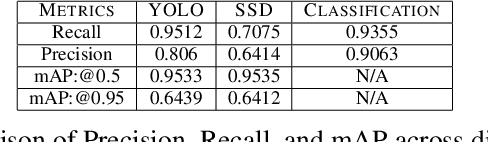
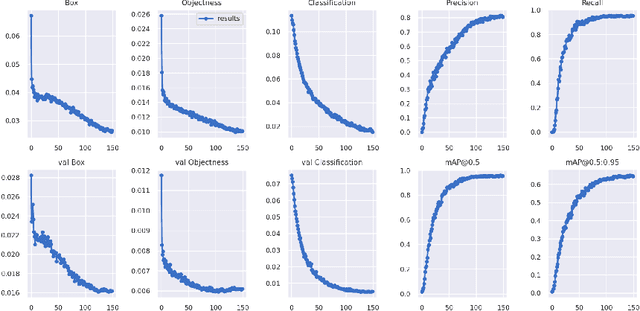
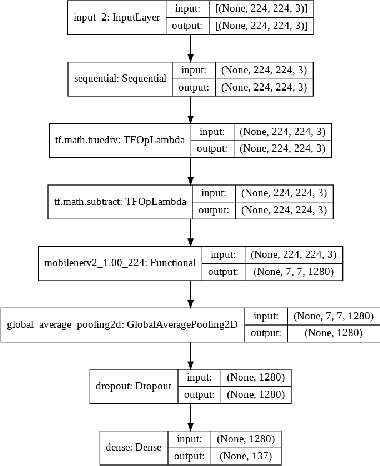
Through this paper, we seek to reduce the communication barrier between the hearing-impaired community and the larger society who are usually not familiar with sign language in the sub-Saharan region of Africa with the largest occurrences of hearing disability cases, while using Nigeria as a case study. The dataset is a pioneer dataset for the Nigerian Sign Language and was created in collaboration with relevant stakeholders. We pre-processed the data in readiness for two different object detection models and a classification model and employed diverse evaluation metrics to gauge model performance on sign-language to text conversion tasks. Finally, we convert the predicted sign texts to speech and deploy the best performing model in a lightweight application that works in real-time and achieves impressive results converting sign words/phrases to text and subsequently, into speech.
Statistical Consequences of Dueling Bandits
Oct 16, 2021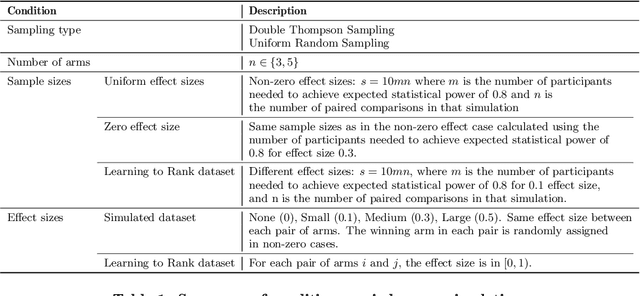
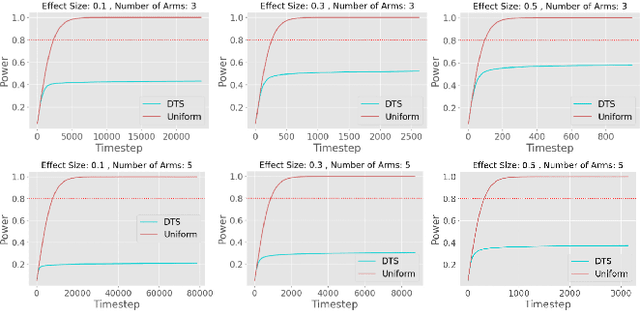
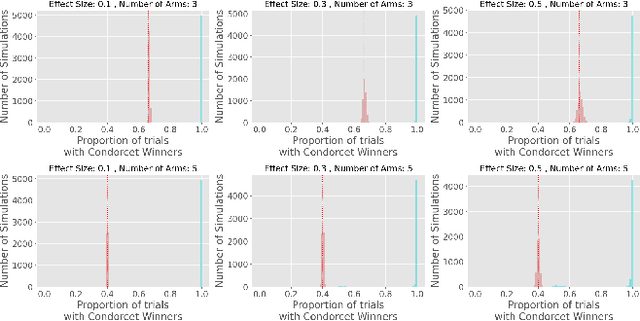
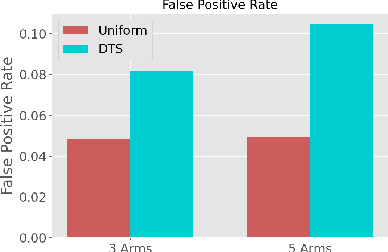
Multi-Armed-Bandit frameworks have often been used by researchers to assess educational interventions, however, recent work has shown that it is more beneficial for a student to provide qualitative feedback through preference elicitation between different alternatives, making a dueling bandits framework more appropriate. In this paper, we explore the statistical quality of data under this framework by comparing traditional uniform sampling to a dueling bandit algorithm and find that dueling bandit algorithms perform well at cumulative regret minimisation, but lead to inflated Type-I error rates and reduced power under certain circumstances. Through these results we provide insight into the challenges and opportunities in using dueling bandit algorithms to run adaptive experiments.
Poisoning the Search Space in Neural Architecture Search
Jun 28, 2021
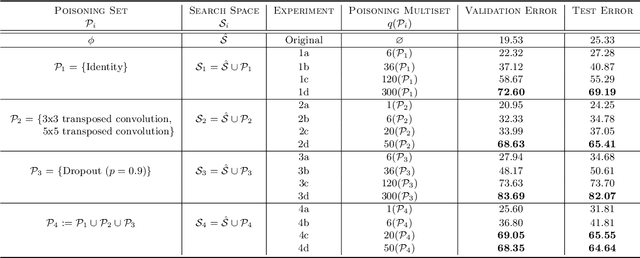

Deep learning has proven to be a highly effective problem-solving tool for object detection and image segmentation across various domains such as healthcare and autonomous driving. At the heart of this performance lies neural architecture design which relies heavily on domain knowledge and prior experience on the researchers' behalf. More recently, this process of finding the most optimal architectures, given an initial search space of possible operations, was automated by Neural Architecture Search (NAS). In this paper, we evaluate the robustness of one such algorithm known as Efficient NAS (ENAS) against data agnostic poisoning attacks on the original search space with carefully designed ineffective operations. By evaluating algorithm performance on the CIFAR-10 dataset, we empirically demonstrate how our novel search space poisoning (SSP) approach and multiple-instance poisoning attacks exploit design flaws in the ENAS controller to result in inflated prediction error rates for child networks. Our results provide insights into the challenges to surmount in using NAS for more adversarially robust architecture search.