 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLNX: Bridging Code and Natural Language for C/C++ Vulnerability-Contributing Commits Identification
Sep 11, 2024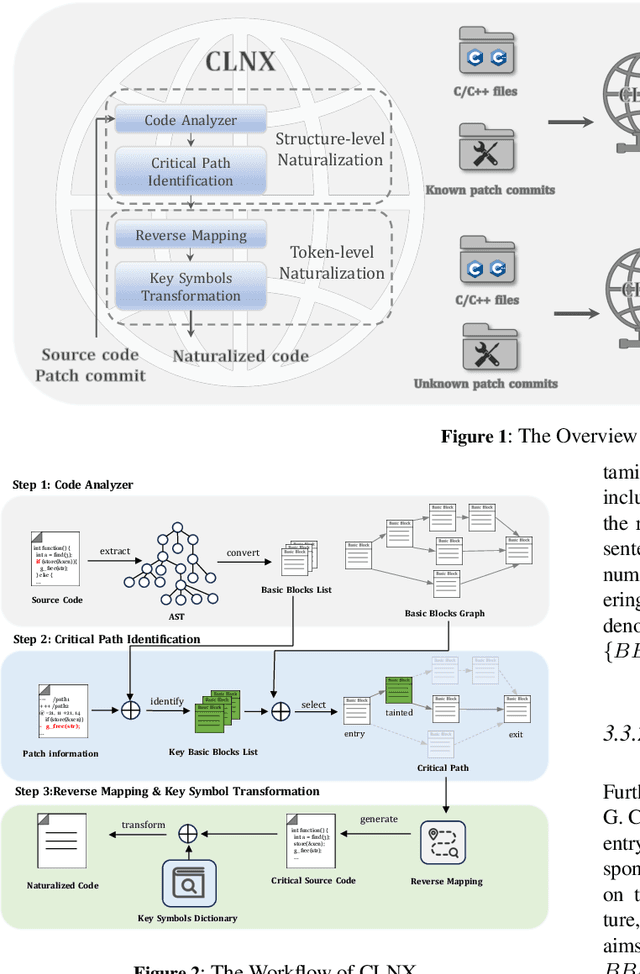
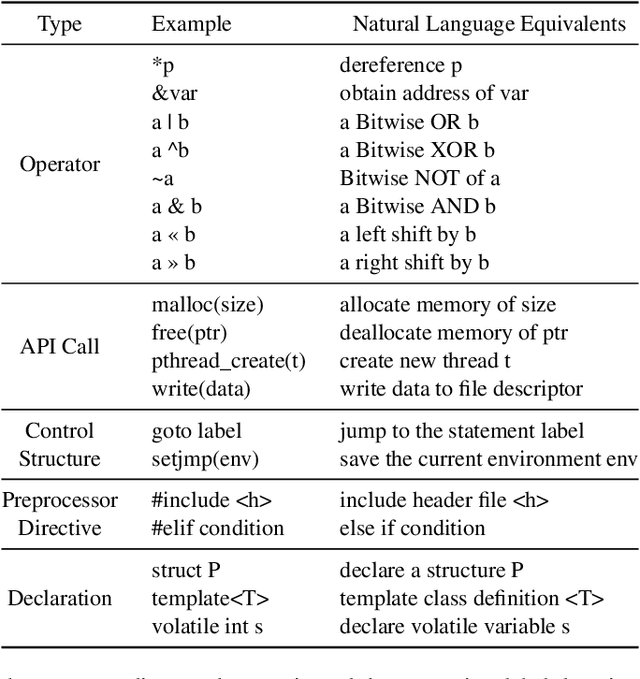
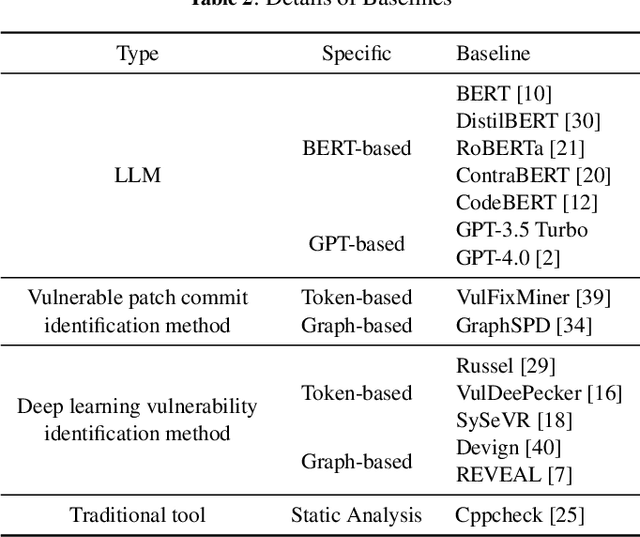
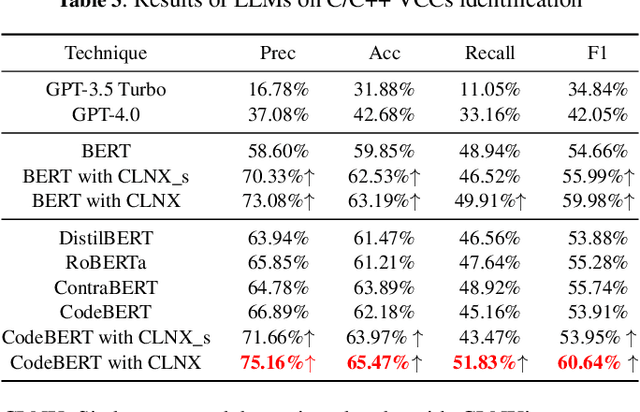
Large Language Models (LLMs) have shown great promise in vulnerability identification. As C/C++ comprises half of the Open-Source Software (OSS) vulnerabilities over the past decade and updates in OSS mainly occur through commits, enhancing LLMs' ability to identify C/C++ Vulnerability-Contributing Commits (VCCs) is essential. However, current studies primarily focus on further pre-training LLMs on massive code datasets, which is resource-intensive and poses efficiency challenges. In this paper, we enhance the ability of BERT-based LLMs to identify C/C++ VCCs in a lightweight manner. We propose CodeLinguaNexus (CLNX) as a bridge facilitating communication between C/C++ programs and LLMs. Based on commits, CLNX efficiently converts the source code into a more natural representation while preserving key details. Specifically, CLNX first applies structure-level naturalization to decompose complex programs, followed by token-level naturalization to interpret complex symbols. We evaluate CLNX on public datasets of 25,872 C/C++ functions with their commits. The results show that CLNX significantly enhances the performance of LLMs on identifying C/C++ VCCs. Moreover, CLNX-equipped CodeBERT achieves new state-of-the-art and identifies 38 OSS vulnerabilities in the real world.