 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Play Cup-and-Ball with Noisy Camera Observations
Jul 19, 2020

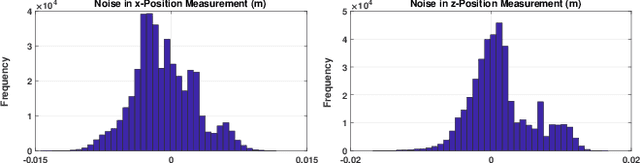

Playing the cup-and-ball game is an intriguing task for robotics research since it abstracts important problem characteristics including system nonlinearity, contact forces and precise positioning as terminal goal. In this paper, we present a learning model based control strategy for the cup-and-ball game, where a Universal Robots UR5e manipulator arm learns to catch a ball in one of the cups on a Kendama. Our control problem is divided into two sub-tasks, namely $(i)$ swinging the ball up in a constrained motion, and $(ii)$ catching the free-falling ball. The swing-up trajectory is computed offline, and applied in open-loop to the arm. Subsequently, a convex optimization problem is solved online during the ball's free-fall to control the manipulator and catch the ball. The controller utilizes noisy position feedback of the ball from an Intel RealSense D435 depth camera. We propose a novel iterative framework, where data is used to learn the support of the camera noise distribution iteratively in order to update the control policy. The probability of a catch with a fixed policy is computed empirically with a user specified number of roll-outs. Our design guarantees that probability of the catch increases in the limit, as the learned support nears the true support of the camera noise distribution. High-fidelity Mujoco simulations and preliminary experimental results support our theoretical analysis.
Safety Challenges for Autonomous Vehicles in the Absence of Connectivity
Jun 06, 2020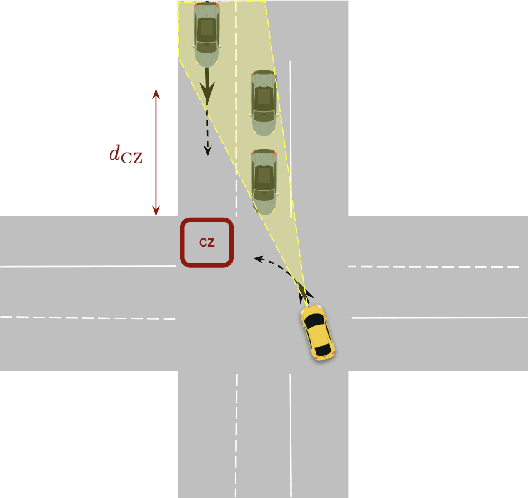

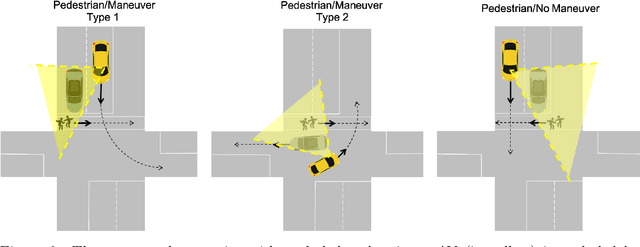
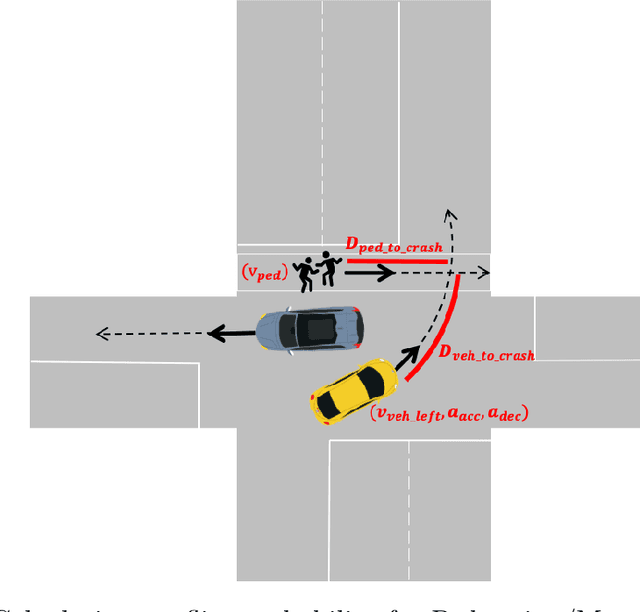
Autonomous vehicles (AVs) are promoted as a technology that will create a future with effortless driving and virtually no traffic accidents. AV companies claim that, when fully developed, the technology will eliminate 94\% of all accidents that are caused by human error. These AVs will likely avoid the large number of crashes caused by impaired, distracted or reckless drivers. But there remains a significant proportion of crashes for which no driver is directly responsible. In particular, the absence of connectivity of an AV with its neighboring vehicles (V2V) and the infrastructure (I2V) leads to a lack of information that can induce such crashes. Since AV designs today do not require such connectivity, these crashes would persist in the future. Using prototypical examples motivated by the NHTSA pre-crash scenario typology, we show that fully autonomous vehicles cannot guarantee safety in the absence of connectivity. Combining theoretical models and empirical data, we also argue that such hazardous scenarios will occur with a significantly high probability. This suggests that incorporating connectivity is an essential step on the path towards safe AV technology.
Show and Recall: Learning What Makes Videos Memorable
Aug 28, 2017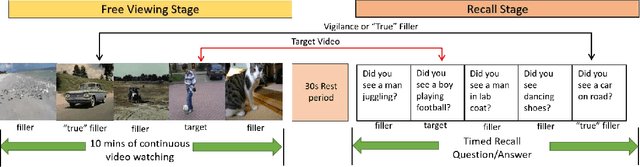
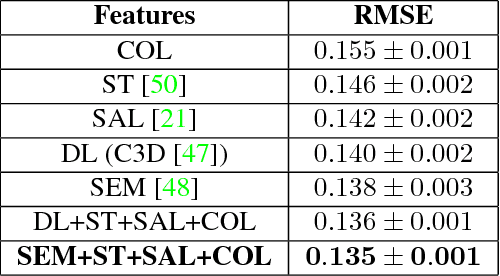
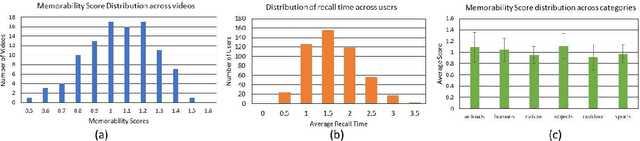

With the explosion of video content on the Internet, there is a need for research on methods for video analysis which take human cognition into account. One such cognitive measure is memorability, or the ability to recall visual content after watching it. Prior research has looked into image memorability and shown that it is intrinsic to visual content, but the problem of modeling video memorability has not been addressed sufficiently. In this work, we develop a prediction model for video memorability, including complexities of video content in it. Detailed feature analysis reveals that the proposed method correlates well with existing findings on memorability. We also describe a novel experiment of predicting video sub-shot memorability and show that our approach improves over current memorability methods in this task. Experiments on standard datasets demonstrate that the proposed metric can achieve results on par or better than the state-of-the art methods for video summarization.