 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextIQ: A Multimodal Expert-Based Video Retrieval System for Contextual Advertising
Oct 29, 2024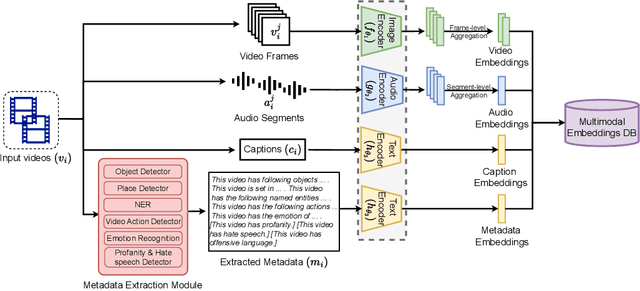
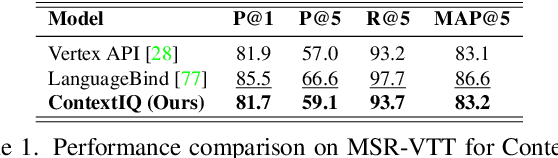
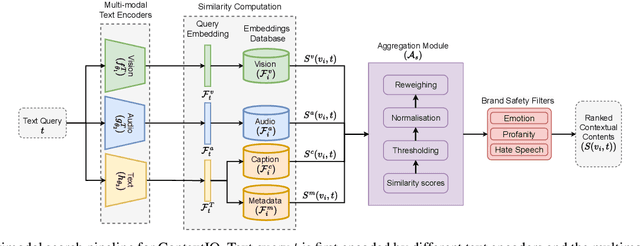
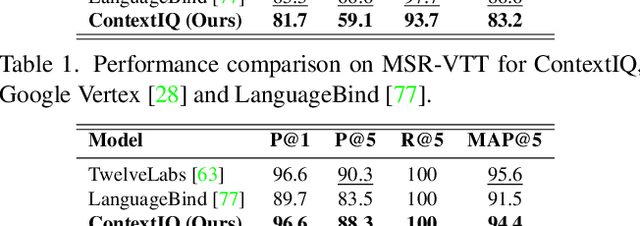
Contextual advertising serves ads that are aligned to the content that the user is viewing. The rapid growth of video content on social platforms and streaming services, along with privacy concerns, has increased the need for contextual advertising. Placing the right ad in the right context creates a seamless and pleasant ad viewing experience, resulting in higher audience engagement and, ultimately, better ad monetization. From a technology standpoint, effective contextual advertising requires a video retrieval system capable of understanding complex video content at a very granular level. Current text-to-video retrieval models based on joint multimodal training demand large datasets and computational resources, limiting their practicality and lacking the key functionalities required for ad ecosystem integration. We introduce ContextIQ, a multimodal expert-based video retrieval system designed specifically for contextual advertising. ContextIQ utilizes modality-specific experts-video, audio, transcript (captions), and metadata such as objects, actions, emotion, etc.-to create semantically rich video representations. We show that our system, without joint training, achieves better or comparable results to state-of-the-art models and commercial solutions on multiple text-to-video retrieval benchmarks. Our ablation studies highlight the benefits of leveraging multiple modalities for enhanced video retrieval accuracy instead of using a vision-language model alone. Furthermore, we show how video retrieval systems such as ContextIQ can be used for contextual advertising in an ad ecosystem while also addressing concerns related to brand safety and filtering inappropriate content.
Learning high-dimensional causal effect
Mar 01, 2023



The scarcity of high-dimensional causal inference datasets restricts the exploration of complex deep models. In this work, we propose a method to generate a synthetic causal dataset that is high-dimensional. The synthetic data simulates a causal effect using the MNIST dataset with Bernoulli treatment values. This provides an opportunity to study varieties of models for causal effect estimation. We experiment on this dataset using Dragonnet architecture (Shi et al. (2019)) and modified architectures. We use the modified architectures to explore different types of initial Neural Network layers and observe that the modified architectures perform better in estimations. We observe that residual and transformer models estimate treatment effect very closely without the need for targeted regularization, introduced by Shi et al. (2019).