 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization Measures for Zero-Shot Cross-Lingual Transfer
Apr 24, 2024



A model's capacity to generalize its knowledge to interpret unseen inputs with different characteristics is crucial to build robust and reliable machine learning systems. Language model evaluation tasks lack information metrics about model generalization and their applicability in a new setting is measured using task and language-specific downstream performance, which is often lacking in many languages and tasks. In this paper, we explore a set of efficient and reliable measures that could aid in computing more information related to the generalization capability of language models in cross-lingual zero-shot settings. In addition to traditional measures such as variance in parameters after training and distance from initialization, we also measure the effectiveness of sharpness in loss landscape in capturing the success in cross-lingual transfer and propose a novel and stable algorithm to reliably compute the sharpness of a model optimum that correlates to generalization.
End-to-End Speech Recognition and Disfluency Removal with Acoustic Language Model Pretraining
Sep 08, 2023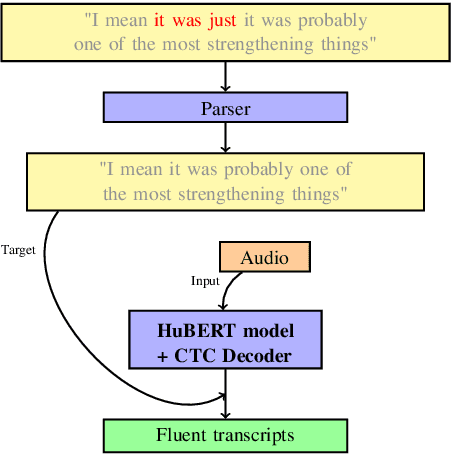
The SOTA in transcription of disfluent and conversational speech has in recent years favored two-stage models, with separate transcription and cleaning stages. We believe that previous attempts at end-to-end disfluency removal have fallen short because of the representational advantage that large-scale language model pretraining has given to lexical models. Until recently, the high dimensionality and limited availability of large audio datasets inhibited the development of large-scale self-supervised pretraining objectives for learning effective audio representations, giving a relative advantage to the two-stage approach, which utilises pretrained representations for lexical tokens. In light of recent successes in large scale audio pretraining, we revisit the performance comparison between two-stage and end-to-end model and find that audio based language models pretrained using weak self-supervised objectives match or exceed the performance of similarly trained two-stage models, and further, that the choice of pretraining objective substantially effects a model's ability to be adapted to the disfluency removal task.
Learning high-dimensional causal effect
Mar 01, 2023



The scarcity of high-dimensional causal inference datasets restricts the exploration of complex deep models. In this work, we propose a method to generate a synthetic causal dataset that is high-dimensional. The synthetic data simulates a causal effect using the MNIST dataset with Bernoulli treatment values. This provides an opportunity to study varieties of models for causal effect estimation. We experiment on this dataset using Dragonnet architecture (Shi et al. (2019)) and modified architectures. We use the modified architectures to explore different types of initial Neural Network layers and observe that the modified architectures perform better in estimations. We observe that residual and transformer models estimate treatment effect very closely without the need for targeted regularization, introduced by Shi et al. (2019).