 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-based Planning with World Models
Dec 28, 2023The enduring challenge in the field of artificial intelligence has been the control of systems to achieve desired behaviours. While for systems governed by straightforward dynamics equations, methods like Linear Quadratic Regulation (LQR) have historically proven highly effective, most real-world tasks, which require a general problem-solver, demand world models with dynamics that cannot be easily described by simple equations. Consequently, these models must be learned from data using neural networks. Most model predictive control (MPC) algorithms designed for visual world models have traditionally explored gradient-free population-based optimisation methods, such as Cross Entropy and Model Predictive Path Integral (MPPI) for planning. However, we present an exploration of a gradient-based alternative that fully leverages the differentiability of the world model. In our study, we conduct a comparative analysis between our method and other MPC-based alternatives, as well as policy-based algorithms. In a sample-efficient setting, our method achieves on par or superior performance compared to the alternative approaches in most tasks. Additionally, we introduce a hybrid model that combines policy networks and gradient-based MPC, which outperforms pure policy based methods thereby holding promise for Gradient-based planning with world models in complex real-world tasks.
End-to-End Speech Recognition and Disfluency Removal with Acoustic Language Model Pretraining
Sep 08, 2023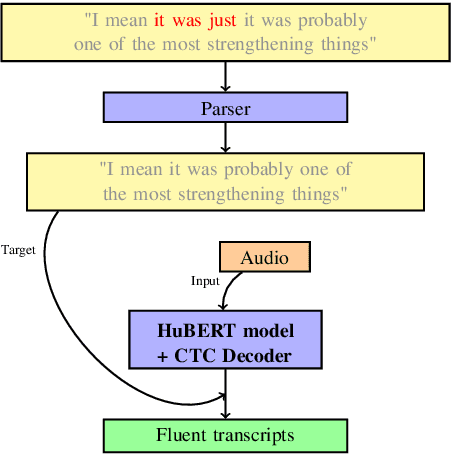
The SOTA in transcription of disfluent and conversational speech has in recent years favored two-stage models, with separate transcription and cleaning stages. We believe that previous attempts at end-to-end disfluency removal have fallen short because of the representational advantage that large-scale language model pretraining has given to lexical models. Until recently, the high dimensionality and limited availability of large audio datasets inhibited the development of large-scale self-supervised pretraining objectives for learning effective audio representations, giving a relative advantage to the two-stage approach, which utilises pretrained representations for lexical tokens. In light of recent successes in large scale audio pretraining, we revisit the performance comparison between two-stage and end-to-end model and find that audio based language models pretrained using weak self-supervised objectives match or exceed the performance of similarly trained two-stage models, and further, that the choice of pretraining objective substantially effects a model's ability to be adapted to the disfluency removal task.
Joint Embedding Predictive Architectures Focus on Slow Features
Nov 20, 2022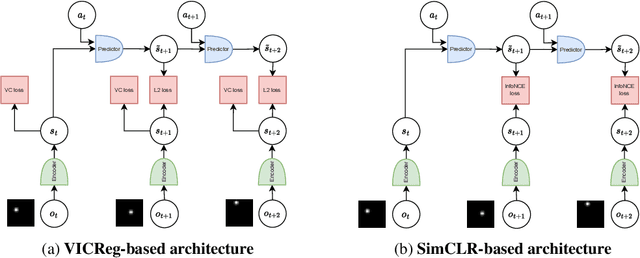
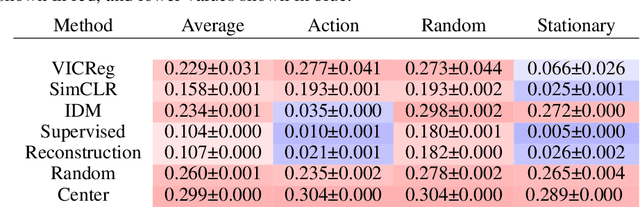

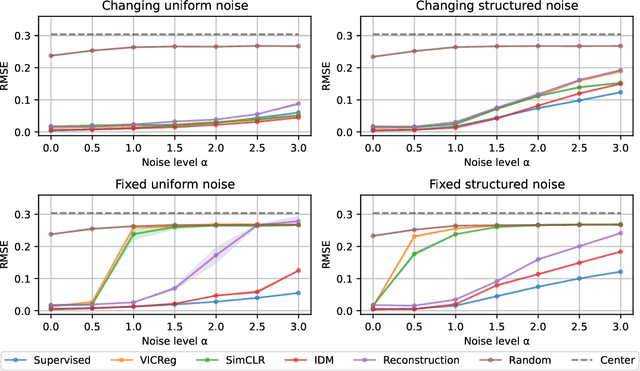
Many common methods for learning a world model for pixel-based environments use generative architectures trained with pixel-level reconstruction objectives. Recently proposed Joint Embedding Predictive Architectures (JEPA) offer a reconstruction-free alternative. In this work, we analyze performance of JEPA trained with VICReg and SimCLR objectives in the fully offline setting without access to rewards, and compare the results to the performance of the generative architecture. We test the methods in a simple environment with a moving dot with various background distractors, and probe learned representations for the dot's location. We find that JEPA methods perform on par or better than reconstruction when distractor noise changes every time step, but fail when the noise is fixed. Furthermore, we provide a theoretical explanation for the poor performance of JEPA-based methods with fixed noise, highlighting an important limitation.