 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePass@K Policy Optimization: Solving Harder Reinforcement Learning Problems
May 21, 2025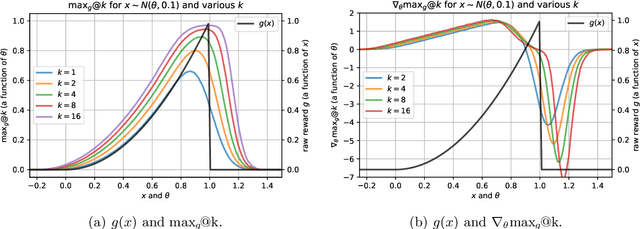
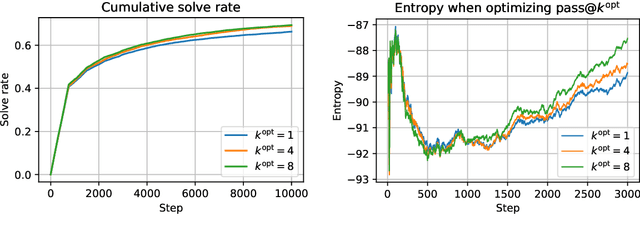
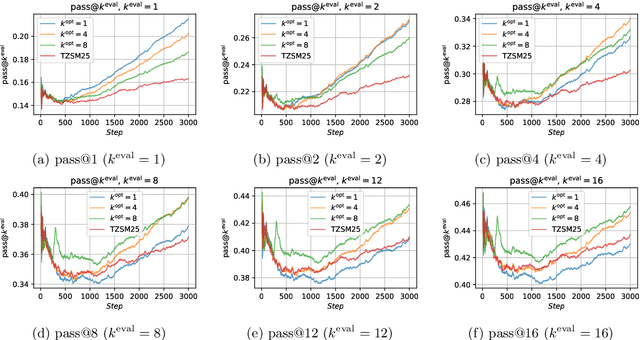
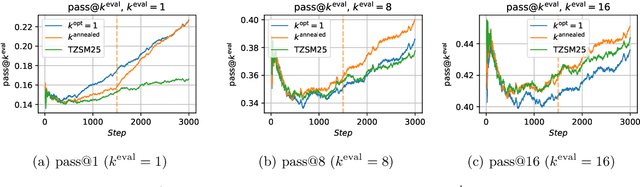
Reinforcement Learning (RL) algorithms sample multiple n>1 solution attempts for each problem and reward them independently. This optimizes for pass@1 performance and prioritizes the strength of isolated samples at the expense of the diversity and collective utility of sets of samples. This under-utilizes the sampling capacity, limiting exploration and eventual improvement on harder examples. As a fix, we propose Pass-at-k Policy Optimization (PKPO), a transformation on the final rewards which leads to direct optimization of pass@k performance, thus optimizing for sets of samples that maximize reward when considered jointly. Our contribution is to derive novel low variance unbiased estimators for pass@k and its gradient, in both the binary and continuous reward settings. We show optimization with our estimators reduces to standard RL with rewards that have been jointly transformed by a stable and efficient transformation function. While previous efforts are restricted to k=n, ours is the first to enable robust optimization of pass@k for any arbitrary k <= n. Moreover, instead of trading off pass@1 performance for pass@k gains, our method allows annealing k during training, optimizing both metrics and often achieving strong pass@1 numbers alongside significant pass@k gains. We validate our reward transformations on toy experiments, which reveal the variance reducing properties of our formulations. We also include real-world examples using the open-source LLM, GEMMA-2. We find that our transformation effectively optimizes for the target k. Furthermore, higher k values enable solving more and harder problems, while annealing k boosts both the pass@1 and pass@k . Crucially, for challenging task sets where conventional pass@1 optimization stalls, our pass@k approach unblocks learning, likely due to better exploration by prioritizing joint utility over the utility of individual samples.
Smaug: Fixing Failure Modes of Preference Optimisation with DPO-Positive
Feb 20, 2024



Direct Preference Optimisation (DPO) is effective at significantly improving the performance of large language models (LLMs) on downstream tasks such as reasoning, summarisation, and alignment. Using pairs of preferred and dispreferred data, DPO models the \textit{relative} probability of picking one response over another. In this work, first we show theoretically that the standard DPO loss can lead to a \textit{reduction} of the model's likelihood of the preferred examples, as long as the relative probability between the preferred and dispreferred classes increases. We then show empirically that this phenomenon occurs when fine-tuning LLMs on common datasets, especially datasets in which the edit distance between pairs of completions is low. Using these insights, we design DPO-Positive (DPOP), a new loss function and training procedure which avoids this failure mode. Surprisingly, we also find that DPOP significantly outperforms DPO across a wide variety of datasets and downstream tasks, including datasets with high edit distances between completions. By fine-tuning with DPOP, we create and release Smaug-34B and Smaug-72B, which achieve state-of-the-art open-source performance. Notably, Smaug-72B is nearly 2\% better than any other open-source model on the HuggingFace Open LLM Leaderboard and becomes the first open-source LLM to surpass an average accuracy of 80\%.
Giraffe: Adventures in Expanding Context Lengths in LLMs
Aug 21, 2023



Modern large language models (LLMs) that rely on attention mechanisms are typically trained with fixed context lengths which enforce upper limits on the length of input sequences that they can handle at evaluation time. To use these models on sequences longer than the train-time context length, one might employ techniques from the growing family of context length extrapolation methods -- most of which focus on modifying the system of positional encodings used in the attention mechanism to indicate where tokens or activations are located in the input sequence. We conduct a wide survey of existing methods of context length extrapolation on a base LLaMA or LLaMA 2 model, and introduce some of our own design as well -- in particular, a new truncation strategy for modifying the basis for the position encoding. We test these methods using three new evaluation tasks (FreeFormQA, AlteredNumericQA, and LongChat-Lines) as well as perplexity, which we find to be less fine-grained as a measure of long context performance of LLMs. We release the three tasks publicly as datasets on HuggingFace. We discover that linear scaling is the best method for extending context length, and show that further gains can be achieved by using longer scales at evaluation time. We also discover promising extrapolation capabilities in the truncated basis. To support further research in this area, we release three new 13B parameter long-context models which we call Giraffe: 4k and 16k context models trained from base LLaMA-13B, and a 32k context model trained from base LLaMA2-13B. We also release the code to replicate our results.
Sentiment Analysis: Predicting Yelp Scores
Jan 20, 2022In this work, we predict the sentiment of restaurant reviews based on a subset of the Yelp Open Dataset. We utilize the meta features and text available in the dataset and evaluate several machine learning and state-of-the-art deep learning approaches for the prediction task. Through several qualitative experiments, we show the success of the deep models with attention mechanism in learning a balanced model for reviews across different restaurants. Finally, we propose a novel Multi-tasked joint BERT model that improves the overall classification performance.