 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Do Temporal Graph Learning Models Learn?
Oct 10, 2025
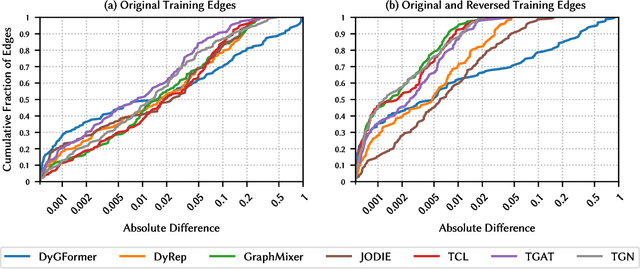
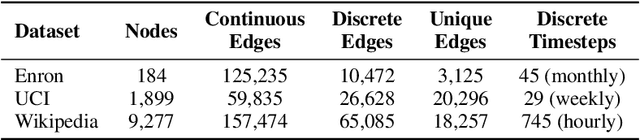
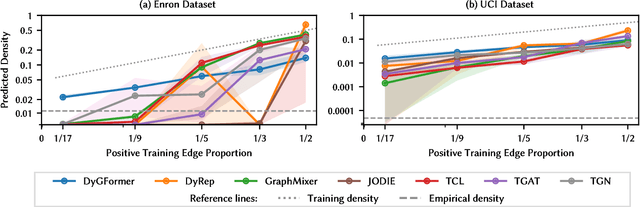
Learning on temporal graphs has become a central topic in graph representation learning, with numerous benchmarks indicating the strong performance of state-of-the-art models. However, recent work has raised concerns about the reliability of benchmark results, noting issues with commonly used evaluation protocols and the surprising competitiveness of simple heuristics. This contrast raises the question of which properties of the underlying graphs temporal graph learning models actually use to form their predictions. We address this by systematically evaluating seven models on their ability to capture eight fundamental attributes related to the link structure of temporal graphs. These include structural characteristics such as density, temporal patterns such as recency, and edge formation mechanisms such as homophily. Using both synthetic and real-world datasets, we analyze how well models learn these attributes. Our findings reveal a mixed picture: models capture some attributes well but fail to reproduce others. With this, we expose important limitations. Overall, we believe that our results provide practical insights for the application of temporal graph learning models, and motivate more interpretability-driven evaluations in temporal graph learning research.
ReSi: A Comprehensive Benchmark for Representational Similarity Measures
Aug 01, 2024



Measuring the similarity of different representations of neural architectures is a fundamental task and an open research challenge for the machine learning community. This paper presents the first comprehensive benchmark for evaluating representational similarity measures based on well-defined groundings of similarity. The representational similarity (ReSi) benchmark consists of (i) six carefully designed tests for similarity measures, (ii) 23 similarity measures, (iii) eleven neural network architectures, and (iv) six datasets, spanning over the graph, language, and vision domains. The benchmark opens up several important avenues of research on representational similarity that enable novel explorations and applications of neural architectures. We demonstrate the utility of the ReSi benchmark by conducting experiments on various neural network architectures, real world datasets and similarity measures. All components of the benchmark are publicly available and thereby facilitate systematic reproduction and production of research results. The benchmark is extensible, future research can build on and further expand it. We believe that the ReSi benchmark can serve as a sound platform catalyzing future research that aims to systematically evaluate existing and explore novel ways of comparing representations of neural architectures.
Similarity of Neural Network Models: A Survey of Functional and Representational Measures
May 10, 2023Measuring similarity of neural networks has become an issue of great importance and research interest to understand and utilize differences of neural networks. While there are several perspectives on how neural networks can be similar, we specifically focus on two complementing perspectives, i.e., (i) representational similarity, which considers how activations of intermediate neural layers differ, and (ii) functional similarity, which considers how models differ in their outputs. In this survey, we provide a comprehensive overview of these two families of similarity measures for neural network models. In addition to providing detailed descriptions of existing measures, we summarize and discuss results on the properties and relationships of these measures, and point to open research problems. Further, we provide practical recommendations that can guide researchers as well as practitioners in applying the measures. We hope our work lays a foundation for our community to engage in more systematic research on the properties, nature and applicability of similarity measures for neural network models.
Properties of Group Fairness Metrics for Rankings
Dec 29, 2022In recent years, several metrics have been developed for evaluating group fairness of rankings. Given that these metrics were developed with different application contexts and ranking algorithms in mind, it is not straightforward which metric to choose for a given scenario. In this paper, we perform a comprehensive comparative analysis of existing group fairness metrics developed in the context of fair ranking. By virtue of their diverse application contexts, we argue that such a comparative analysis is not straightforward. Hence, we take an axiomatic approach whereby we design a set of thirteen properties for group fairness metrics that consider different ranking settings. A metric can then be selected depending on whether it satisfies all or a subset of these properties. We apply these properties on eleven existing group fairness metrics, and through both empirical and theoretical results we demonstrate that most of these metrics only satisfy a small subset of the proposed properties. These findings highlight limitations of existing metrics, and provide insights into how to evaluate and interpret different fairness metrics in practical deployment. The proposed properties can also assist practitioners in selecting appropriate metrics for evaluating fairness in a specific application.
A Comparative Evaluation of Quantification Methods
Mar 04, 2021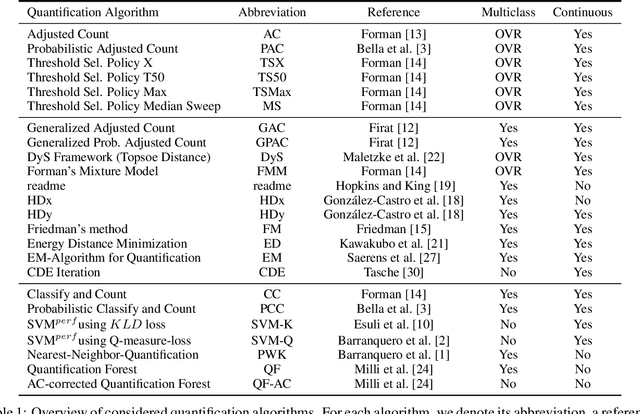
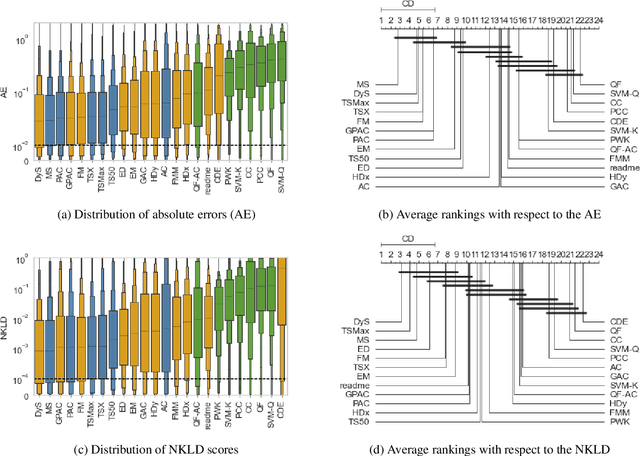
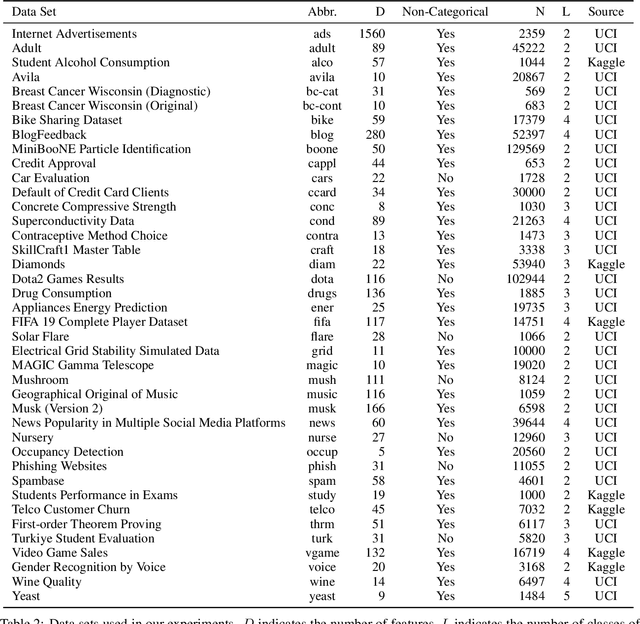
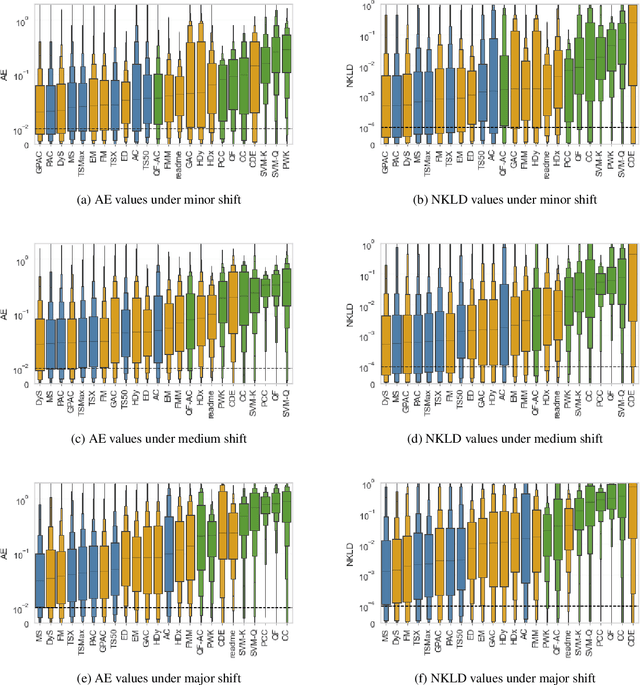
Quantification represents the problem of predicting class distributions in a given target set. It also represents a growing research field in supervised machine learning, for which a large variety of different algorithms has been proposed in recent years. However, a comprehensive empirical comparison of quantification methods that supports algorithm selection is not available yet. In this work, we close this research gap by conducting a thorough empirical performance comparison of 24 different quantification methods. To consider a broad range of different scenarios for binary as well as multiclass quantification settings, we carried out almost 3 million experimental runs on 40 data sets. We observe that no single algorithm generally outperforms all competitors, but identify a group of methods including the Median Sweep and the DyS framework that perform significantly better in binary settings. For the multiclass setting, we observe that a different, broad group of algorithms yields good performance, including the Generalized Probabilistic Adjusted Count, the readme method, the energy distance minimization method, the EM algorithm for quantification, and Friedman's method. More generally, we find that the performance on multiclass quantification is inferior to the results obtained in the binary setting. Our results can guide practitioners who intend to apply quantification algorithms and help researchers to identify opportunities for future research.
The Effects of Randomness on the Stability of Node Embeddings
May 20, 2020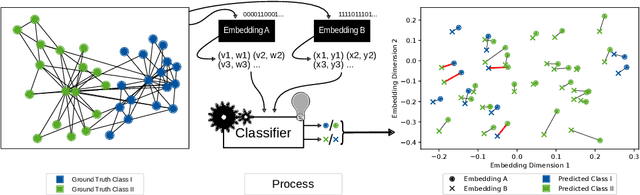
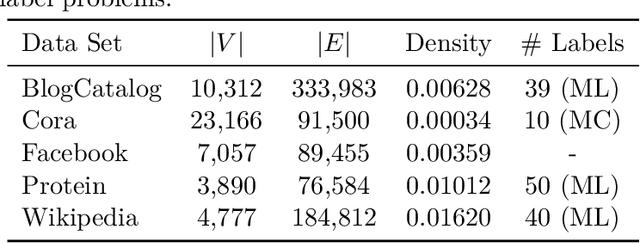
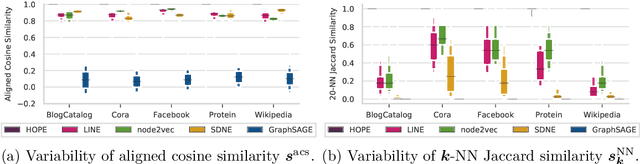
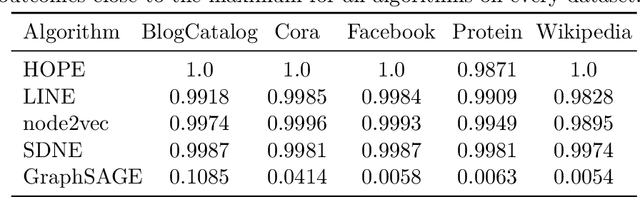
We systematically evaluate the (in-)stability of state-of-the-art node embedding algorithms due to randomness, i.e., the random variation of their outcomes given identical algorithms and graphs. We apply five node embeddings algorithms---HOPE, LINE, node2vec, SDNE, and GraphSAGE---to synthetic and empirical graphs and assess their stability under randomness with respect to (i) the geometry of embedding spaces as well as (ii) their performance in downstream tasks. We find significant instabilities in the geometry of embedding spaces independent of the centrality of a node. In the evaluation of downstream tasks, we find that the accuracy of node classification seems to be unaffected by random seeding while the actual classification of nodes can vary significantly. This suggests that instability effects need to be taken into account when working with node embeddings. Our work is relevant for researchers and engineers interested in the effectiveness, reliability, and reproducibility of node embedding approaches.
Privacy Attacks on Network Embeddings
Dec 23, 2019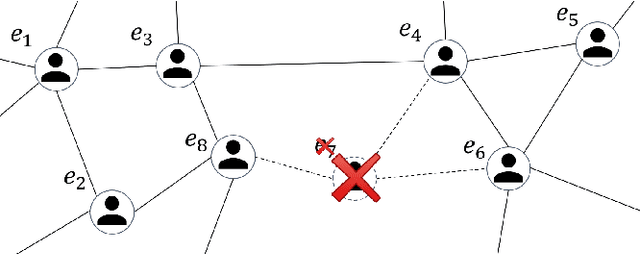
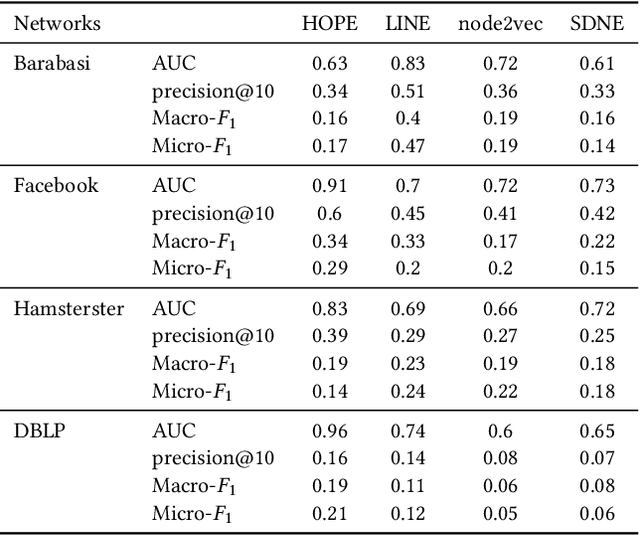
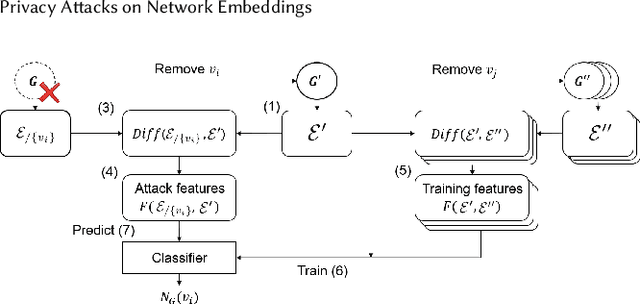
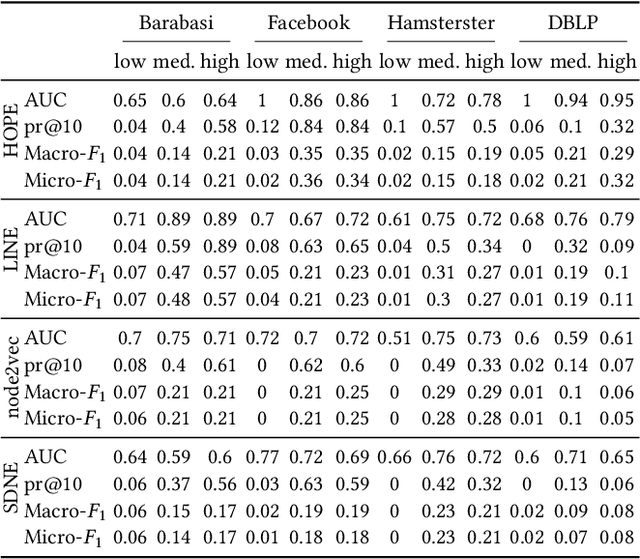
Data ownership and data protection are increasingly important topics with ethical and legal implications, e.g., with the right to erasure established in the European General Data Protection Regulation (GDPR). In this light, we investigate network embeddings, i.e., the representation of network nodes as low-dimensional vectors. We consider a typical social network scenario with nodes representing users and edges relationships between them. We assume that a network embedding of the nodes has been trained. After that, a user demands the removal of his data, requiring the full deletion of the corresponding network information, in particular the corresponding node and incident edges. In that setting, we analyze whether after the removal of the node from the network and the deletion of the vector representation of the respective node in the embedding significant information about the link structure of the removed node is still encoded in the embedding vectors of the remaining nodes. This would require a (potentially computationally expensive) retraining of the embedding. For that purpose, we deploy an attack that leverages information from the remaining network and embedding to recover information about the neighbors of the removed node. The attack is based on (i) measuring distance changes in network embeddings and (ii) a machine learning classifier that is trained on networks that are constructed by removing additional nodes. Our experiments demonstrate that substantial information about the edges of a removed node/user can be retrieved across many different datasets. This implies that to fully protect the privacy of users, node deletion requires complete retraining - or at least a significant modification - of original network embeddings. Our results suggest that deleting the corresponding vector representation from network embeddings alone is not sufficient from a privacy perspective.