 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical clustering with maximum density paths and mixture models
Mar 19, 2025Hierarchical clustering is an effective and interpretable technique for analyzing structure in data, offering a nuanced understanding by revealing insights at multiple scales and resolutions. It is particularly helpful in settings where the exact number of clusters is unknown, and provides a robust framework for exploring complex datasets. Additionally, hierarchical clustering can uncover inner structures within clusters, capturing subtle relationships and nested patterns that may be obscured by traditional flat clustering methods. However, existing hierarchical clustering methods struggle with high-dimensional data, especially when there are no clear density gaps between modes. Our method addresses this limitation by leveraging a two-stage approach, first employing a Gaussian or Student's t mixture model to overcluster the data, and then hierarchically merging clusters based on the induced density landscape. This approach yields state-of-the-art clustering performance while also providing a meaningful hierarchy, making it a valuable tool for exploratory data analysis. Code is available at https://github.com/ecker-lab/tneb clustering.
MNIST-Nd: a set of naturalistic datasets to benchmark clustering across dimensions
Oct 21, 2024Driven by advances in recording technology, large-scale high-dimensional datasets have emerged across many scientific disciplines. Especially in biology, clustering is often used to gain insights into the structure of such datasets, for instance to understand the organization of different cell types. However, clustering is known to scale poorly to high dimensions, even though the exact impact of dimensionality is unclear as current benchmark datasets are mostly two-dimensional. Here we propose MNIST-Nd, a set of synthetic datasets that share a key property of real-world datasets, namely that individual samples are noisy and clusters do not perfectly separate. MNIST-Nd is obtained by training mixture variational autoencoders with 2 to 64 latent dimensions on MNIST, resulting in six datasets with comparable structure but varying dimensionality. It thus offers the chance to disentangle the impact of dimensionality on clustering. Preliminary common clustering algorithm benchmarks on MNIST-Nd suggest that Leiden is the most robust for growing dimensions.
Distinguished In Uniform: Self Attention Vs. Virtual Nodes
May 20, 2024Graph Transformers (GTs) such as SAN and GPS are graph processing models that combine Message-Passing GNNs (MPGNNs) with global Self-Attention. They were shown to be universal function approximators, with two reservations: 1. The initial node features must be augmented with certain positional encodings. 2. The approximation is non-uniform: Graphs of different sizes may require a different approximating network. We first clarify that this form of universality is not unique to GTs: Using the same positional encodings, also pure MPGNNs and even 2-layer MLPs are non-uniform universal approximators. We then consider uniform expressivity: The target function is to be approximated by a single network for graphs of all sizes. There, we compare GTs to the more efficient MPGNN + Virtual Node architecture. The essential difference between the two model definitions is in their global computation method -- Self-Attention Vs Virtual Node. We prove that none of the models is a uniform-universal approximator, before proving our main result: Neither model's uniform expressivity subsumes the other's. We demonstrate the theory with experiments on synthetic data. We further augment our study with real-world datasets, observing mixed results which indicate no clear ranking in practice as well.
Boosting, Voting Classifiers and Randomized Sample Compression Schemes
Feb 05, 2024In boosting, we aim to leverage multiple weak learners to produce a strong learner. At the center of this paradigm lies the concept of building the strong learner as a voting classifier, which outputs a weighted majority vote of the weak learners. While many successful boosting algorithms, such as the iconic AdaBoost, produce voting classifiers, their theoretical performance has long remained sub-optimal: the best known bounds on the number of training examples necessary for a voting classifier to obtain a given accuracy has so far always contained at least two logarithmic factors above what is known to be achievable by general weak-to-strong learners. In this work, we break this barrier by proposing a randomized boosting algorithm that outputs voting classifiers whose generalization error contains a single logarithmic dependency on the sample size. We obtain this result by building a general framework that extends sample compression methods to support randomized learning algorithms based on sub-sampling.
Where Did the Gap Go? Reassessing the Long-Range Graph Benchmark
Sep 05, 2023



The recent Long-Range Graph Benchmark (LRGB, Dwivedi et al. 2022) introduced a set of graph learning tasks strongly dependent on long-range interaction between vertices. Empirical evidence suggests that on these tasks Graph Transformers significantly outperform Message Passing GNNs (MPGNNs). In this paper, we carefully reevaluate multiple MPGNN baselines as well as the Graph Transformer GPS (Ramp\'a\v{s}ek et al. 2022) on LRGB. Through a rigorous empirical analysis, we demonstrate that the reported performance gap is overestimated due to suboptimal hyperparameter choices. It is noteworthy that across multiple datasets the performance gap completely vanishes after basic hyperparameter optimization. In addition, we discuss the impact of lacking feature normalization for LRGB's vision datasets and highlight a spurious implementation of LRGB's link prediction metric. The principal aim of our paper is to establish a higher standard of empirical rigor within the graph machine learning community.
AdaBoost is not an Optimal Weak to Strong Learner
Jan 27, 2023

AdaBoost is a classic boosting algorithm for combining multiple inaccurate classifiers produced by a weak learner, to produce a strong learner with arbitrarily high accuracy when given enough training data. Determining the optimal number of samples necessary to obtain a given accuracy of the strong learner, is a basic learning theoretic question. Larsen and Ritzert (NeurIPS'22) recently presented the first provably optimal weak-to-strong learner. However, their algorithm is somewhat complicated and it remains an intriguing question whether the prototypical boosting algorithm AdaBoost also makes optimal use of training samples. In this work, we answer this question in the negative. Concretely, we show that the sample complexity of AdaBoost, and other classic variations thereof, are sub-optimal by at least one logarithmic factor in the desired accuracy of the strong learner.
Optimal Weak to Strong Learning
Jun 08, 2022The classic algorithm AdaBoost allows to convert a weak learner, that is an algorithm that produces a hypothesis which is slightly better than chance, into a strong learner, achieving arbitrarily high accuracy when given enough training data. We present a new algorithm that constructs a strong learner from a weak learner but uses less training data than AdaBoost and all other weak to strong learners to achieve the same generalization bounds. A sample complexity lower bound shows that our new algorithm uses the minimum possible amount of training data and is thus optimal. Hence, this work settles the sample complexity of the classic problem of constructing a strong learner from a weak learner.
Graph Machine Learning for Design of High-Octane Fuels
Jun 01, 2022



Fuels with high-knock resistance enable modern spark-ignition engines to achieve high efficiency and thus low CO2 emissions. Identification of molecules with desired autoignition properties indicated by a high research octane number and a high octane sensitivity is therefore of great practical relevance and can be supported by computer-aided molecular design (CAMD). Recent developments in the field of graph machine learning (graph-ML) provide novel, promising tools for CAMD. We propose a modular graph-ML CAMD framework that integrates generative graph-ML models with graph neural networks and optimization, enabling the design of molecules with desired ignition properties in a continuous molecular space. In particular, we explore the potential of Bayesian optimization and genetic algorithms in combination with generative graph-ML models. The graph-ML CAMD framework successfully identifies well-established high-octane components. It also suggests new candidates, one of which we experimentally investigate and use to illustrate the need for further auto-ignition training data.
Graph Learning with 1D Convolutions on Random Walks
Feb 17, 2021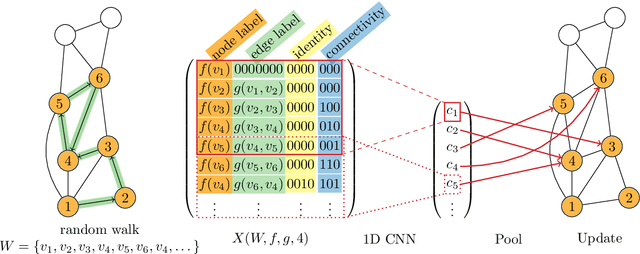
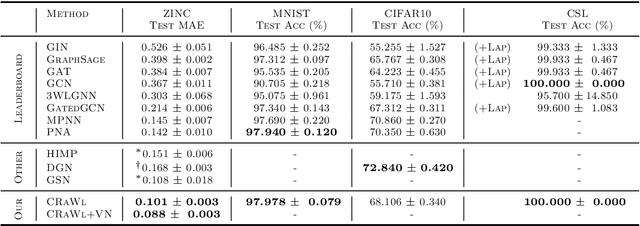
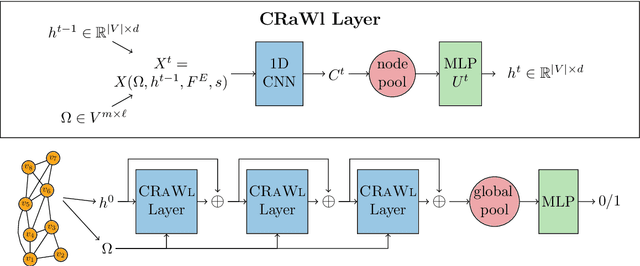
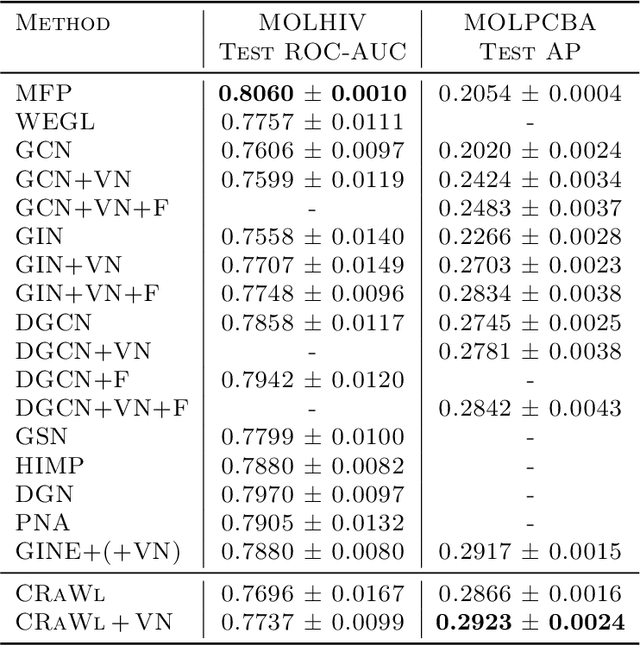
We propose CRaWl (CNNs for Random Walks), a novel neural network architecture for graph learning. It is based on processing sequences of small subgraphs induced by random walks with standard 1D CNNs. Thus, CRaWl is fundamentally different from typical message passing graph neural network architectures. It is inspired by techniques counting small subgraphs, such as the graphlet kernel and motif counting, and combines them with random walk based techniques in a highly efficient and scalable neural architecture. We demonstrate empirically that CRaWl matches or outperforms state-of-the-art GNN architectures across a multitude of benchmark datasets for graph learning.
The Effects of Randomness on the Stability of Node Embeddings
May 20, 2020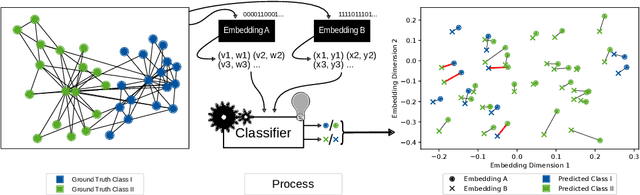
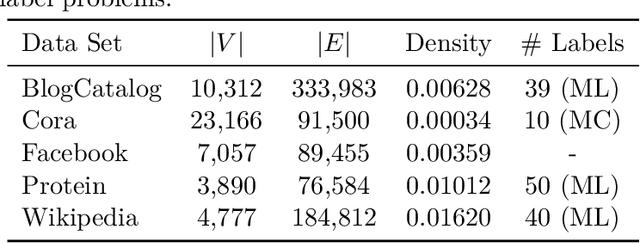
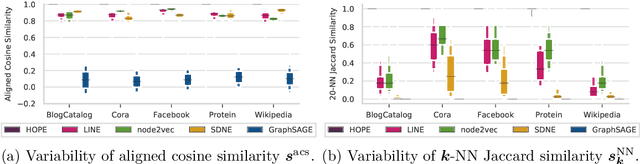
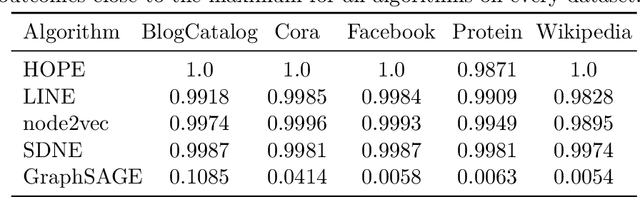
We systematically evaluate the (in-)stability of state-of-the-art node embedding algorithms due to randomness, i.e., the random variation of their outcomes given identical algorithms and graphs. We apply five node embeddings algorithms---HOPE, LINE, node2vec, SDNE, and GraphSAGE---to synthetic and empirical graphs and assess their stability under randomness with respect to (i) the geometry of embedding spaces as well as (ii) their performance in downstream tasks. We find significant instabilities in the geometry of embedding spaces independent of the centrality of a node. In the evaluation of downstream tasks, we find that the accuracy of node classification seems to be unaffected by random seeding while the actual classification of nodes can vary significantly. This suggests that instability effects need to be taken into account when working with node embeddings. Our work is relevant for researchers and engineers interested in the effectiveness, reliability, and reproducibility of node embedding approaches.