 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistinguished In Uniform: Self Attention Vs. Virtual Nodes
May 20, 2024Graph Transformers (GTs) such as SAN and GPS are graph processing models that combine Message-Passing GNNs (MPGNNs) with global Self-Attention. They were shown to be universal function approximators, with two reservations: 1. The initial node features must be augmented with certain positional encodings. 2. The approximation is non-uniform: Graphs of different sizes may require a different approximating network. We first clarify that this form of universality is not unique to GTs: Using the same positional encodings, also pure MPGNNs and even 2-layer MLPs are non-uniform universal approximators. We then consider uniform expressivity: The target function is to be approximated by a single network for graphs of all sizes. There, we compare GTs to the more efficient MPGNN + Virtual Node architecture. The essential difference between the two model definitions is in their global computation method -- Self-Attention Vs Virtual Node. We prove that none of the models is a uniform-universal approximator, before proving our main result: Neither model's uniform expressivity subsumes the other's. We demonstrate the theory with experiments on synthetic data. We further augment our study with real-world datasets, observing mixed results which indicate no clear ranking in practice as well.
One Model, Any CSP: Graph Neural Networks as Fast Global Search Heuristics for Constraint Satisfaction
Aug 22, 2022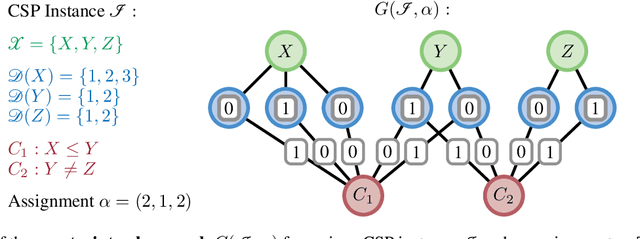
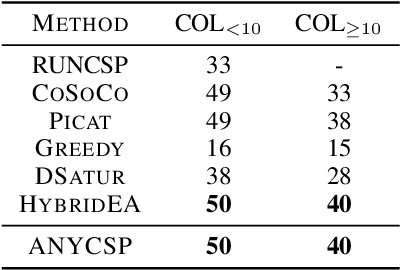

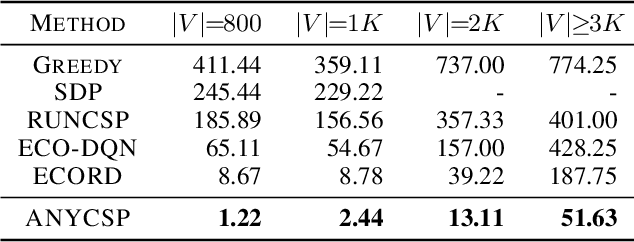
We propose a universal Graph Neural Network architecture which can be trained as an end-2-end search heuristic for any Constraint Satisfaction Problem (CSP). Our architecture can be trained unsupervised with policy gradient descent to generate problem specific heuristics for any CSP in a purely data driven manner. The approach is based on a novel graph representation for CSPs that is both generic and compact and enables us to process every possible CSP instance with one GNN, regardless of constraint arity, relations or domain size. Unlike previous RL-based methods, we operate on a global search action space and allow our GNN to modify any number of variables in every step of the stochastic search. This enables our method to properly leverage the inherent parallelism of GNNs. We perform a thorough empirical evaluation where we learn heuristics for well known and important CSPs from random data, including graph coloring, MaxCut, 3-SAT and MAX-k-SAT. Our approach outperforms prior approaches for neural combinatorial optimization by a substantial margin. It can compete with, and even improve upon, conventional search heuristics on test instances that are several orders of magnitude larger and structurally more complex than those seen during training.