 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReSi: A Comprehensive Benchmark for Representational Similarity Measures
Aug 01, 2024



Measuring the similarity of different representations of neural architectures is a fundamental task and an open research challenge for the machine learning community. This paper presents the first comprehensive benchmark for evaluating representational similarity measures based on well-defined groundings of similarity. The representational similarity (ReSi) benchmark consists of (i) six carefully designed tests for similarity measures, (ii) 23 similarity measures, (iii) eleven neural network architectures, and (iv) six datasets, spanning over the graph, language, and vision domains. The benchmark opens up several important avenues of research on representational similarity that enable novel explorations and applications of neural architectures. We demonstrate the utility of the ReSi benchmark by conducting experiments on various neural network architectures, real world datasets and similarity measures. All components of the benchmark are publicly available and thereby facilitate systematic reproduction and production of research results. The benchmark is extensible, future research can build on and further expand it. We believe that the ReSi benchmark can serve as a sound platform catalyzing future research that aims to systematically evaluate existing and explore novel ways of comparing representations of neural architectures.
Towards Measuring Representational Similarity of Large Language Models
Dec 05, 2023Understanding the similarity of the numerous released large language models (LLMs) has many uses, e.g., simplifying model selection, detecting illegal model reuse, and advancing our understanding of what makes LLMs perform well. In this work, we measure the similarity of representations of a set of LLMs with 7B parameters. Our results suggest that some LLMs are substantially different from others. We identify challenges of using representational similarity measures that suggest the need of careful study of similarity scores to avoid false conclusions.
Similarity of Neural Network Models: A Survey of Functional and Representational Measures
May 10, 2023Measuring similarity of neural networks has become an issue of great importance and research interest to understand and utilize differences of neural networks. While there are several perspectives on how neural networks can be similar, we specifically focus on two complementing perspectives, i.e., (i) representational similarity, which considers how activations of intermediate neural layers differ, and (ii) functional similarity, which considers how models differ in their outputs. In this survey, we provide a comprehensive overview of these two families of similarity measures for neural network models. In addition to providing detailed descriptions of existing measures, we summarize and discuss results on the properties and relationships of these measures, and point to open research problems. Further, we provide practical recommendations that can guide researchers as well as practitioners in applying the measures. We hope our work lays a foundation for our community to engage in more systematic research on the properties, nature and applicability of similarity measures for neural network models.
On the Prediction Instability of Graph Neural Networks
May 20, 2022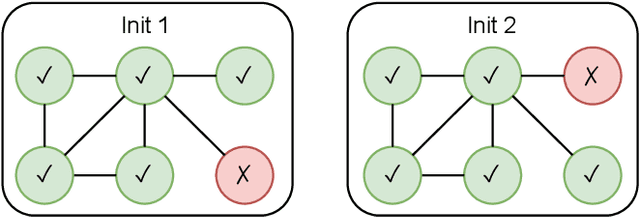
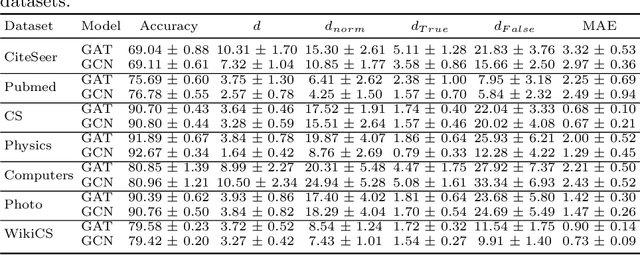
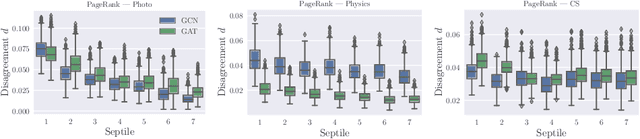
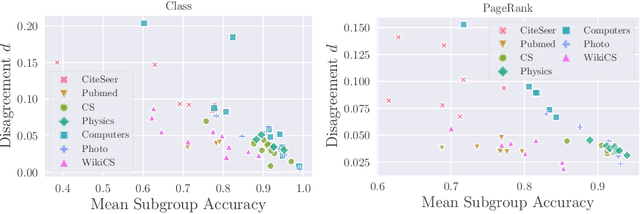
Instability of trained models, i.e., the dependence of individual node predictions on random factors, can affect reproducibility, reliability, and trust in machine learning systems. In this paper, we systematically assess the prediction instability of node classification with state-of-the-art Graph Neural Networks (GNNs). With our experiments, we establish that multiple instantiations of popular GNN models trained on the same data with the same model hyperparameters result in almost identical aggregated performance but display substantial disagreement in the predictions for individual nodes. We find that up to one third of the incorrectly classified nodes differ across algorithm runs. We identify correlations between hyperparameters, node properties, and the size of the training set with the stability of predictions. In general, maximizing model performance implicitly also reduces model instability.
The Effects of Randomness on the Stability of Node Embeddings
May 20, 2020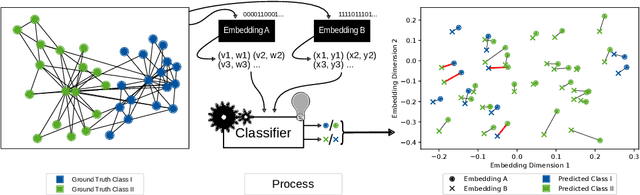
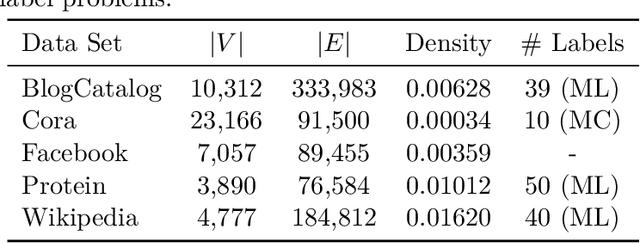
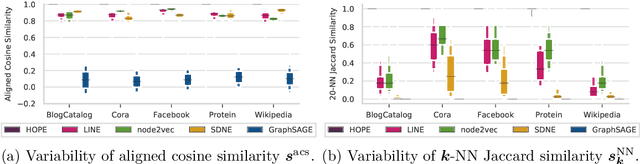
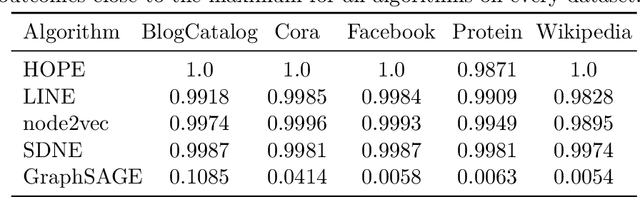
We systematically evaluate the (in-)stability of state-of-the-art node embedding algorithms due to randomness, i.e., the random variation of their outcomes given identical algorithms and graphs. We apply five node embeddings algorithms---HOPE, LINE, node2vec, SDNE, and GraphSAGE---to synthetic and empirical graphs and assess their stability under randomness with respect to (i) the geometry of embedding spaces as well as (ii) their performance in downstream tasks. We find significant instabilities in the geometry of embedding spaces independent of the centrality of a node. In the evaluation of downstream tasks, we find that the accuracy of node classification seems to be unaffected by random seeding while the actual classification of nodes can vary significantly. This suggests that instability effects need to be taken into account when working with node embeddings. Our work is relevant for researchers and engineers interested in the effectiveness, reliability, and reproducibility of node embedding approaches.