 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-Near-Optimal Agnostic Boosting with Improved Running Time
Jan 16, 2026Boosting is a powerful method that turns weak learners, which perform only slightly better than random guessing, into strong learners with high accuracy. While boosting is well understood in the classic setting, it is less so in the agnostic case, where no assumptions are made about the data. Indeed, only recently was the sample complexity of agnostic boosting nearly settled arXiv:2503.09384, but the known algorithm achieving this bound has exponential running time. In this work, we propose the first agnostic boosting algorithm with near-optimal sample complexity, running in time polynomial in the sample size when considering the other parameters of the problem fixed.
Revisiting Agnostic Boosting
Mar 12, 2025Boosting is a key method in statistical learning, allowing for converting weak learners into strong ones. While well studied in the realizable case, the statistical properties of weak-to-strong learning remains less understood in the agnostic setting, where there are no assumptions on the distribution of the labels. In this work, we propose a new agnostic boosting algorithm with substantially improved sample complexity compared to prior works under very general assumptions. Our approach is based on a reduction to the realizable case, followed by a margin-based filtering step to select high-quality hypotheses. We conjecture that the error rate achieved by our proposed method is optimal up to logarithmic factors.
Optimal Parallelization of Boosting
Aug 29, 2024Recent works on the parallel complexity of Boosting have established strong lower bounds on the tradeoff between the number of training rounds $p$ and the total parallel work per round $t$. These works have also presented highly non-trivial parallel algorithms that shed light on different regions of this tradeoff. Despite these advancements, a significant gap persists between the theoretical lower bounds and the performance of these algorithms across much of the tradeoff space. In this work, we essentially close this gap by providing both improved lower bounds on the parallel complexity of weak-to-strong learners, and a parallel Boosting algorithm whose performance matches these bounds across the entire $p$ vs.~$t$ compromise spectrum, up to logarithmic factors. Ultimately, this work settles the true parallel complexity of Boosting algorithms that are nearly sample-optimal.
Boosting, Voting Classifiers and Randomized Sample Compression Schemes
Feb 05, 2024In boosting, we aim to leverage multiple weak learners to produce a strong learner. At the center of this paradigm lies the concept of building the strong learner as a voting classifier, which outputs a weighted majority vote of the weak learners. While many successful boosting algorithms, such as the iconic AdaBoost, produce voting classifiers, their theoretical performance has long remained sub-optimal: the best known bounds on the number of training examples necessary for a voting classifier to obtain a given accuracy has so far always contained at least two logarithmic factors above what is known to be achievable by general weak-to-strong learners. In this work, we break this barrier by proposing a randomized boosting algorithm that outputs voting classifiers whose generalization error contains a single logarithmic dependency on the sample size. We obtain this result by building a general framework that extends sample compression methods to support randomized learning algorithms based on sub-sampling.
Polynomially Over-Parameterized Convolutional Neural Networks Contain Structured Strong Winning Lottery Tickets
Nov 16, 2023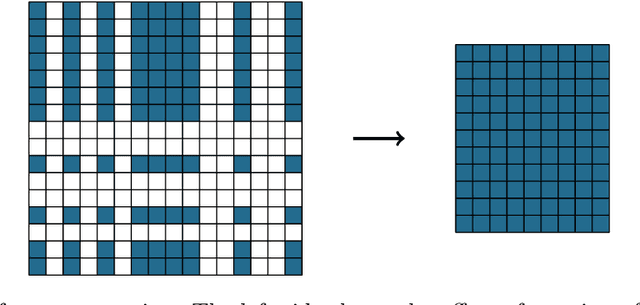
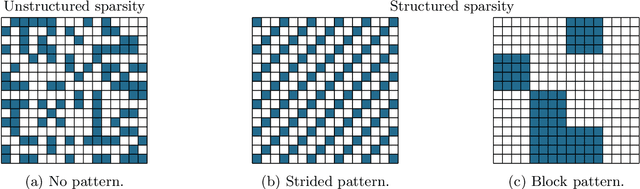
The Strong Lottery Ticket Hypothesis (SLTH) states that randomly-initialised neural networks likely contain subnetworks that perform well without any training. Although unstructured pruning has been extensively studied in this context, its structured counterpart, which can deliver significant computational and memory efficiency gains, has been largely unexplored. One of the main reasons for this gap is the limitations of the underlying mathematical tools used in formal analyses of the SLTH. In this paper, we overcome these limitations: we leverage recent advances in the multidimensional generalisation of the Random Subset-Sum Problem and obtain a variant that admits the stochastic dependencies that arise when addressing structured pruning in the SLTH. We apply this result to prove, for a wide class of random Convolutional Neural Networks, the existence of structured subnetworks that can approximate any sufficiently smaller network. This result provides the first sub-exponential bound around the SLTH for structured pruning, opening up new avenues for further research on the hypothesis and contributing to the understanding of the role of over-parameterization in deep learning.