 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-Near-Optimal Agnostic Boosting with Improved Running Time
Jan 16, 2026Boosting is a powerful method that turns weak learners, which perform only slightly better than random guessing, into strong learners with high accuracy. While boosting is well understood in the classic setting, it is less so in the agnostic case, where no assumptions are made about the data. Indeed, only recently was the sample complexity of agnostic boosting nearly settled arXiv:2503.09384, but the known algorithm achieving this bound has exponential running time. In this work, we propose the first agnostic boosting algorithm with near-optimal sample complexity, running in time polynomial in the sample size when considering the other parameters of the problem fixed.
Uniform Mean Estimation for Heavy-Tailed Distributions via Median-of-Means
Jun 18, 2025The Median of Means (MoM) is a mean estimator that has gained popularity in the context of heavy-tailed data. In this work, we analyze its performance in the task of simultaneously estimating the mean of each function in a class $\mathcal{F}$ when the data distribution possesses only the first $p$ moments for $p \in (1,2]$. We prove a new sample complexity bound using a novel symmetrization technique that may be of independent interest. Additionally, we present applications of our result to $k$-means clustering with unbounded inputs and linear regression with general losses, improving upon existing works.
Revisiting Agnostic Boosting
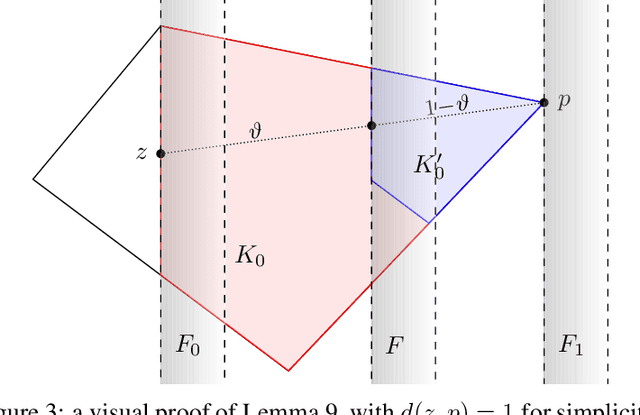
Mar 12, 2025Boosting is a key method in statistical learning, allowing for converting weak learners into strong ones. While well studied in the realizable case, the statistical properties of weak-to-strong learning remains less understood in the agnostic setting, where there are no assumptions on the distribution of the labels. In this work, we propose a new agnostic boosting algorithm with substantially improved sample complexity compared to prior works under very general assumptions. Our approach is based on a reduction to the realizable case, followed by a margin-based filtering step to select high-quality hypotheses. We conjecture that the error rate achieved by our proposed method is optimal up to logarithmic factors.
General Tail Bounds for Non-Smooth Stochastic Mirror Descent
Dec 12, 2023In this paper, we provide novel tail bounds on the optimization error of Stochastic Mirror Descent for convex and Lipschitz objectives. Our analysis extends the existing tail bounds from the classical light-tailed Sub-Gaussian noise case to heavier-tailed noise regimes. We study the optimization error of the last iterate as well as the average of the iterates. We instantiate our results in two important cases: a class of noise with exponential tails and one with polynomial tails. A remarkable feature of our results is that they do not require an upper bound on the diameter of the domain. Finally, we support our theory with illustrative experiments that compare the behavior of the average of the iterates with that of the last iterate in heavy-tailed noise regimes.
An Improved Uniform Convergence Bound with Fat-Shattering Dimension
Jul 13, 2023The fat-shattering dimension characterizes the uniform convergence property of real-valued functions. The state-of-the-art upper bounds feature a multiplicative squared logarithmic factor on the sample complexity, leaving an open gap with the existing lower bound. We provide an improved uniform convergence bound that closes this gap.
Active Learning of Classifiers with Label and Seed Queries
Sep 08, 2022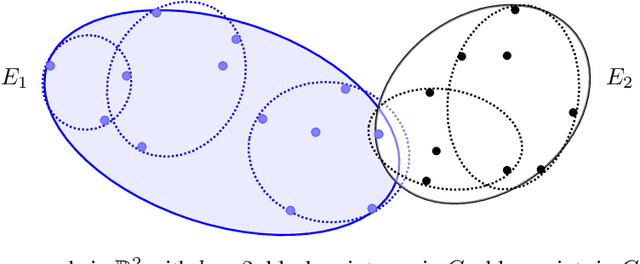
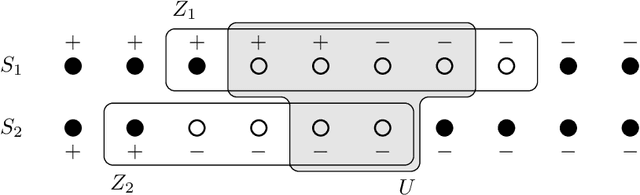
We study exact active learning of binary and multiclass classifiers with margin. Given an $n$-point set $X \subset \mathbb{R}^m$, we want to learn any unknown classifier on $X$ whose classes have finite strong convex hull margin, a new notion extending the SVM margin. In the standard active learning setting, where only label queries are allowed, learning a classifier with strong convex hull margin $\gamma$ requires in the worst case $\Omega\big(1+\frac{1}{\gamma}\big)^{(m-1)/2}$ queries. On the other hand, using the more powerful seed queries (a variant of equivalence queries), the target classifier could be learned in $O(m \log n)$ queries via Littlestone's Halving algorithm; however, Halving is computationally inefficient. In this work we show that, by carefully combining the two types of queries, a binary classifier can be learned in time $\operatorname{poly}(n+m)$ using only $O(m^2 \log n)$ label queries and $O\big(m \log \frac{m}{\gamma}\big)$ seed queries; the result extends to $k$-class classifiers at the price of a $k!k^2$ multiplicative overhead. Similar results hold when the input points have bounded bit complexity, or when only one class has strong convex hull margin against the rest. We complement the upper bounds by showing that in the worst case any algorithm needs $\Omega\big(k m \log \frac{1}{\gamma}\big)$ seed and label queries to learn a $k$-class classifier with strong convex hull margin $\gamma$.
Regret Analysis of Dyadic Search
Sep 02, 2022
We analyze the cumulative regret of the Dyadic Search algorithm of Bachoc et al. [2022].
High Probability Bounds for Stochastic Subgradient Schemes with Heavy Tailed Noise
Aug 17, 2022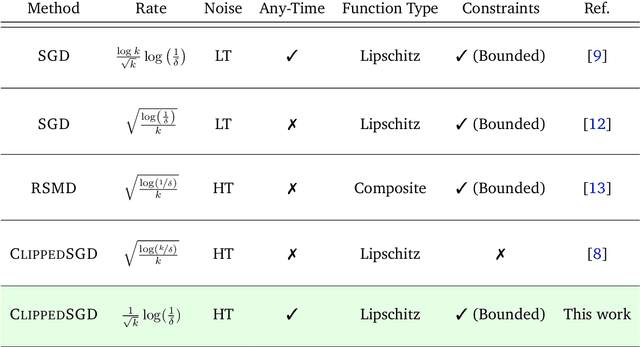
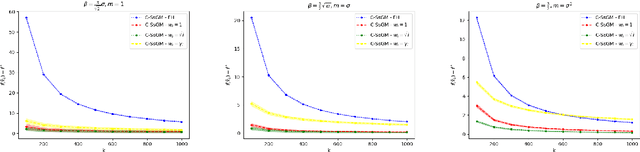
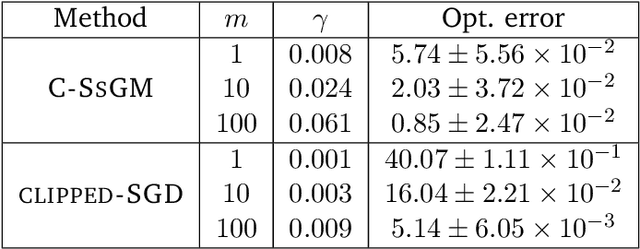
In this work we study high probability bounds for stochastic subgradient methods under heavy tailed noise. In this case the noise is only assumed to have finite variance as opposed to a sub-Gaussian distribution for which it is known that standard subgradient methods enjoys high probability bounds. We analyzed a clipped version of the projected stochastic subgradient method, where subgradient estimates are truncated whenever they have large norms. We show that this clipping strategy leads both to near optimal any-time and finite horizon bounds for many classical averaging schemes. Preliminary experiments are shown to support the validity of the method.
A Near-Optimal Algorithm for Univariate Zeroth-Order Budget Convex Optimization
Aug 13, 2022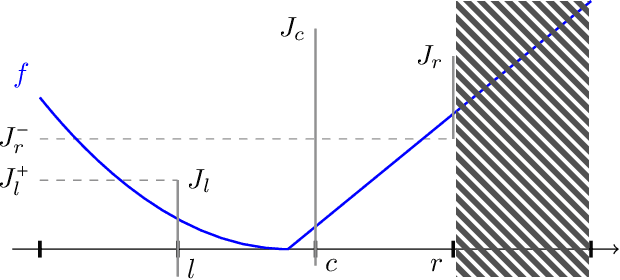
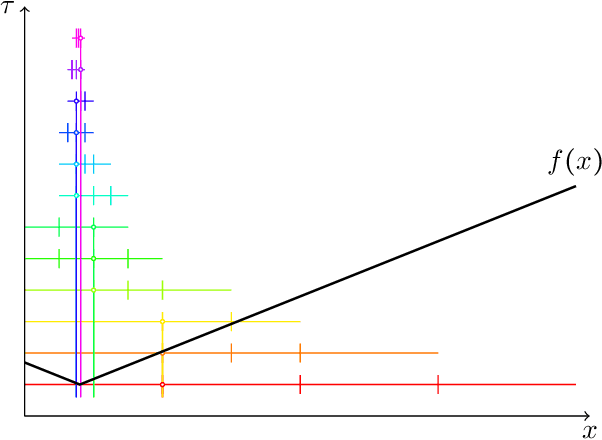
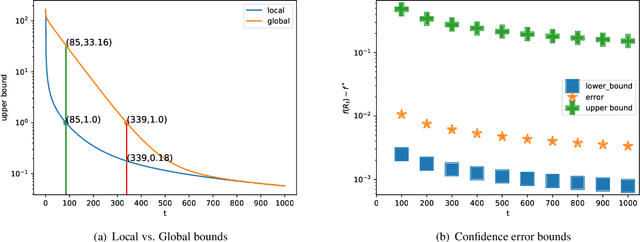
This paper studies a natural generalization of the problem of minimizing a univariate convex function $f$ by querying its values sequentially. At each time-step $t$, the optimizer can invest a budget $b_t$ in a query point $X_t$ of their choice to obtain a fuzzy evaluation of $f$ at $X_t$ whose accuracy depends on the amount of budget invested in $X_t$ across times. This setting is motivated by the minimization of objectives whose values can only be determined approximately through lengthy or expensive computations. We design an any-time parameter-free algorithm called Dyadic Search, for which we prove near-optimal optimization error guarantees. As a byproduct of our analysis, we show that the classical dependence on the global Lipschitz constant in the error bounds is an artifact of the granularity of the budget. Finally, we illustrate our theoretical findings with numerical simulations.
On Margin-Based Cluster Recovery with Oracle Queries
Jun 09, 2021
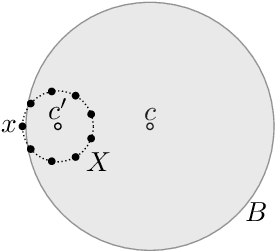
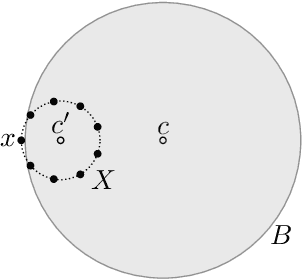
We study an active cluster recovery problem where, given a set of $n$ points and an oracle answering queries like "are these two points in the same cluster?", the task is to recover exactly all clusters using as few queries as possible. We begin by introducing a simple but general notion of margin between clusters that captures, as special cases, the margins used in previous work, the classic SVM margin, and standard notions of stability for center-based clusterings. Then, under our margin assumptions we design algorithms that, in a variety of settings, recover all clusters exactly using only $O(\log n)$ queries. For the Euclidean case, $\mathbb{R}^m$, we give an algorithm that recovers arbitrary convex clusters, in polynomial time, and with a number of queries that is lower than the best existing algorithm by $\Theta(m^m)$ factors. For general pseudometric spaces, where clusters might not be convex or might not have any notion of shape, we give an algorithm that achieves the $O(\log n)$ query bound, and is provably near-optimal as a function of the packing number of the space. Finally, for clusterings realized by binary concept classes, we give a combinatorial characterization of recoverability with $O(\log n)$ queries, and we show that, for many concept classes in Euclidean spaces, this characterization is equivalent to our margin condition. Our results show a deep connection between cluster margins and active cluster recoverability.