 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-agent cooperation through in-context co-player inference
Feb 18, 2026Achieving cooperation among self-interested agents remains a fundamental challenge in multi-agent reinforcement learning. Recent work showed that mutual cooperation can be induced between "learning-aware" agents that account for and shape the learning dynamics of their co-players. However, existing approaches typically rely on hardcoded, often inconsistent, assumptions about co-player learning rules or enforce a strict separation between "naive learners" updating on fast timescales and "meta-learners" observing these updates. Here, we demonstrate that the in-context learning capabilities of sequence models allow for co-player learning awareness without requiring hardcoded assumptions or explicit timescale separation. We show that training sequence model agents against a diverse distribution of co-players naturally induces in-context best-response strategies, effectively functioning as learning algorithms on the fast intra-episode timescale. We find that the cooperative mechanism identified in prior work-where vulnerability to extortion drives mutual shaping-emerges naturally in this setting: in-context adaptation renders agents vulnerable to extortion, and the resulting mutual pressure to shape the opponent's in-context learning dynamics resolves into the learning of cooperative behavior. Our results suggest that standard decentralized reinforcement learning on sequence models combined with co-player diversity provides a scalable path to learning cooperative behaviors.
MNIST-Nd: a set of naturalistic datasets to benchmark clustering across dimensions
Oct 21, 2024Driven by advances in recording technology, large-scale high-dimensional datasets have emerged across many scientific disciplines. Especially in biology, clustering is often used to gain insights into the structure of such datasets, for instance to understand the organization of different cell types. However, clustering is known to scale poorly to high dimensions, even though the exact impact of dimensionality is unclear as current benchmark datasets are mostly two-dimensional. Here we propose MNIST-Nd, a set of synthetic datasets that share a key property of real-world datasets, namely that individual samples are noisy and clusters do not perfectly separate. MNIST-Nd is obtained by training mixture variational autoencoders with 2 to 64 latent dimensions on MNIST, resulting in six datasets with comparable structure but varying dimensionality. It thus offers the chance to disentangle the impact of dimensionality on clustering. Preliminary common clustering algorithm benchmarks on MNIST-Nd suggest that Leiden is the most robust for growing dimensions.
Self-supervised Representation Learning of Neuronal Morphologies
Jan 18, 2022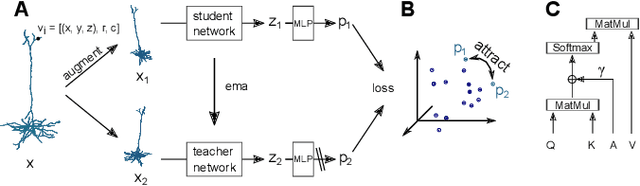
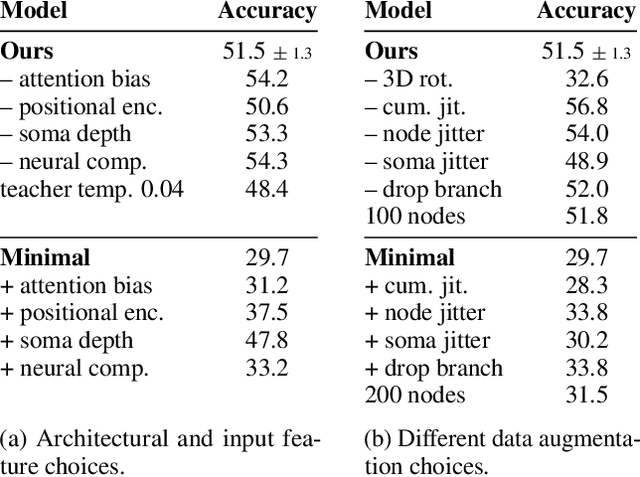
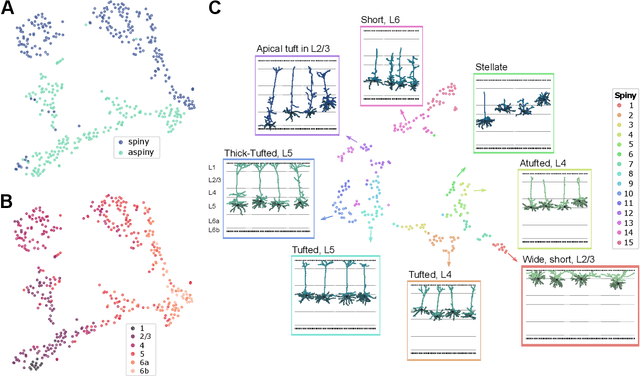
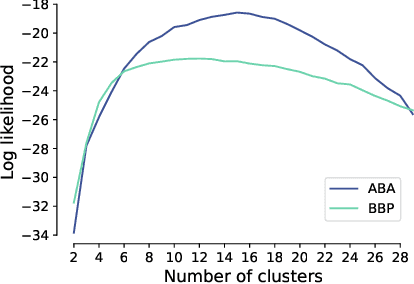
Understanding the diversity of cell types and their function in the brain is one of the key challenges in neuroscience. The advent of large-scale datasets has given rise to the need of unbiased and quantitative approaches to cell type classification. We present GraphDINO, a purely data-driven approach to learning a low dimensional representation of the 3D morphology of neurons. GraphDINO is a novel graph representation learning method for spatial graphs utilizing self-supervised learning on transformer models. It combines attention-based global interaction between nodes and classic graph convolutional processing. We show, in two different species and cortical areas, that this method is able to yield morphological cell type clustering that is comparable to manual feature-based classification and shows a good correspondence to expert-labeled cell types. Our method is applicable beyond neuroscience in settings where samples in a dataset are graphs and graph-level embeddings are desired.
Unmasking the Inductive Biases of Unsupervised Object Representations for Video Sequences
Jun 12, 2020
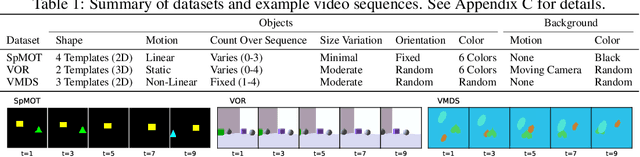
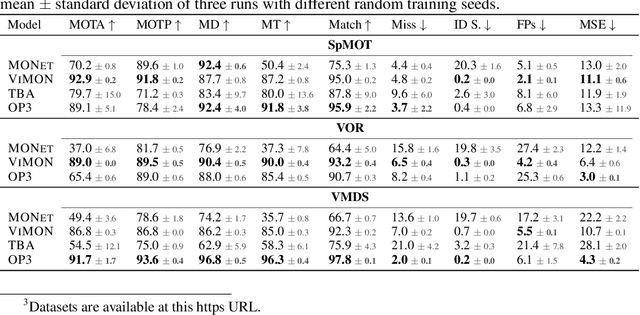

Perceiving the world in terms of objects is a crucial prerequisite for reasoning and scene understanding. Recently, several methods have been proposed for unsupervised learning of object-centric representations. However, since these models have been evaluated with respect to different downstream tasks, it remains unclear how they compare in terms of basic perceptual abilities such as detection, figure-ground segmentation and tracking of individual objects. In this paper, we argue that the established evaluation protocol of multi-object tracking tests precisely these perceptual qualities and we propose a new benchmark dataset based on procedurally generated video sequences. Using this benchmark, we compare the perceptual abilities of three state-of-the-art unsupervised object-centric learning approaches. Towards this goal, we propose a video-extension of MONet, a seminal object-centric model for static scenes, and compare it to two recent video models: OP3, which exploits clustering via spatial mixture models, and TBA, which uses an explicit factorization via spatial transformers. Our results indicate that architectures which employ unconstrained latent representations based on per-object variational autoencoders and full-image object masks are able to learn more powerful representations in terms of object detection, segmentation and tracking than the explicitly parameterized spatial transformer based architecture. We also observe that none of the methods are able to gracefully handle the most challenging tracking scenarios, suggesting that our synthetic video benchmark may provide fruitful guidance towards learning more robust object-centric video representations.
Flexibly Fair Representation Learning by Disentanglement
Jun 06, 2019



We consider the problem of learning representations that achieve group and subgroup fairness with respect to multiple sensitive attributes. Taking inspiration from the disentangled representation learning literature, we propose an algorithm for learning compact representations of datasets that are useful for reconstruction and prediction, but are also \emph{flexibly fair}, meaning they can be easily modified at test time to achieve subgroup demographic parity with respect to multiple sensitive attributes and their conjunctions. We show empirically that the resulting encoder---which does not require the sensitive attributes for inference---enables the adaptation of a single representation to a variety of fair classification tasks with new target labels and subgroup definitions.
Diverse feature visualizations reveal invariances in early layers of deep neural networks
Jul 27, 2018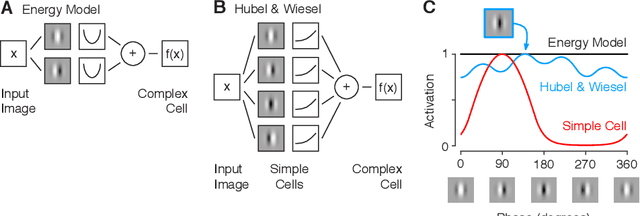
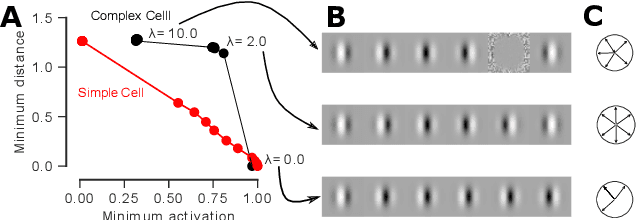
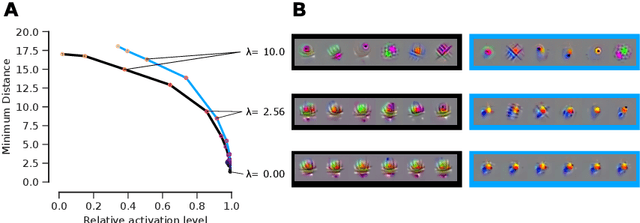
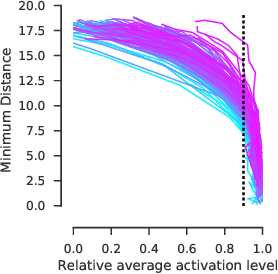
Visualizing features in deep neural networks (DNNs) can help understanding their computations. Many previous studies aimed to visualize the selectivity of individual units by finding meaningful images that maximize their activation. However, comparably little attention has been paid to visualizing to what image transformations units in DNNs are invariant. Here we propose a method to discover invariances in the responses of hidden layer units of deep neural networks. Our approach is based on simultaneously searching for a batch of images that strongly activate a unit while at the same time being as distinct from each other as possible. We find that even early convolutional layers in VGG-19 exhibit various forms of response invariance: near-perfect phase invariance in some units and invariance to local diffeomorphic transformations in others. At the same time, we uncover representational differences with ResNet-50 in its corresponding layers. We conclude that invariance transformations are a major computational component learned by DNNs and we provide a systematic method to study them.