 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Collective Action: Proxy-Based Perturbations for Correcting Algorithmic Harms
May 26, 2026When machine learning systems under-perform for particular subgroups, affected users typically have no way to correct these disparities without relying on platform-level fixes. Existing approaches to algorithmic fairness rely on provider-centric approaches to correct these failures, leaving users with no external lever when faced with harm. Recent work in Algorithmic Collective Action shows that coordinated users can steer an algorithmic system toward a collective goal, but the existing mechanisms require the provider to retrain on the collective's modified data which users may not have control over. We propose Test-Time Collective Action (TTCA), a framework through which a group of users who share query access to the platform, can correct disparities affecting under-served subgroup without participating in the platform's training loop. We implement this through a proxy-based mechanism where the collective pools query access to a black-box API to extract a proxy of the platform, then optimizes a per-class universal perturbation against the proxy. Each member applies this perturbation to their own inputs at submission time, requiring no cooperation from the platform. We empirically evaluate the mechanism on CIFAR-10, CIFAR-100, and FairFace, showing that modestly-sized collectives close most of the subgroup accuracy gap, transfer across architectures (a small proxy can attack a larger platform), and improve worst-group accuracy, equal-opportunity gap, and disparate impact. A query-budget analysis comparing a per-user black-box attack baseline shows that pooling is cheaper than each subgroup member attacking alone. Test-time collective action thus offers corrective intervention to users when platform-side remediation is unavailable or delayed.
DriftXpress: Faster Drifting Models via Projected RKHS Fields
May 12, 2026Drifting Models have emerged as a new paradigm for one-step generative modeling, achieving strong image quality without iterative inference. The premise is to replace the iterative denoising process in diffusion models with a single evaluation of a generator. However, this creates a different trade-off: drifting reduces inference cost by moving much of the computation into training. We introduce DriftXpress, an accelerated formulation of drifting models based on projected RKHS fields. DriftXpress approximates the drifting kernel in a low-rank feature space. This preserves the attraction-repulsion structure of the original drifting field while reducing the cost of field evaluation. Across image-generation benchmarks, DriftXpress achieves comparable FID to standard drifting while reducing wall-clock training cost. These results show that the training-inference trade-off of drifting models can be pushed further without giving up their one-step inference advantage.
Reliable Quasi-Static Post-Fall Floor-Occupancy Detection Using Low-Cost Millimetre-Wave Radar
Jan 25, 2026As the population ages rapidly, long-term care (LTC) facilities across North America face growing pressure to monitor residents safely while keeping staff workload manageable. Falls are among the most critical events to monitor due to their timely response requirement, yet frequent false alarms or uncertain detections can overwhelm caregivers and contribute to alarm fatigue. This motivates the design of reliable, whole end-to-end ambient monitoring systems from occupancy and activity awareness to fall and post-fall detection. In this paper, we focus on robust post-fall floor-occupancy detection using an off-the-shelf 60 GHz FMCW radar and evaluate its deployment in a realistic, furnished indoor environment representative of LTC facilities. Post-fall detection is challenging since motion is minimal, and reflections from the floor and surrounding objects can dominate the radar signal return. We compare a vendor-provided digital beamforming (DBF) pipeline against a proposed preprocessing approach based on Capon or minimum variance distortionless response (MVDR) beamforming. A cell-averaging constant false alarm rate (CA-CFAR) detector is applied and evaluated on the resulting range-azimuth maps across 7 participants. The proposed method improves the mean frame-positive rate from 0.823 (DBF) to 0.916 (Proposed).
A Physics-Informed Digital Twin Framework for Calibrated Sim-to-Real FMCW Radar Occupancy Estimation
Jan 25, 2026Learning robust radar perception models directly from real measurements is costly due to the need for controlled experiments, repeated calibration, and extensive annotation. This paper proposes a lightweight simulation-to-real (sim2real) framework that enables reliable Frequency Modulated Continuous Wave (FMCW) radar occupancy detection and people counting using only a physics-informed geometric simulator and a small unlabeled real calibration set. We introduce calibrated domain randomization (CDR) to align the global noise-floor statistics of simulated range-Doppler (RD) maps with those observed in real environments while preserving discriminative micro-Doppler structure. Across real-world evaluations, ResNet18 models trained purely on CDR-adjusted simulation achieve 97 percent accuracy for occupancy detection and 72 percent accuracy for people counting, outperforming ray-tracing baseline simulation and conventional random domain randomization baselines.
Doppler-Domain Respiratory Amplification for Semi-Static Human Occupancy Detection Using Low-Resolution SIMO FMCW Radar
Jan 25, 2026Radar-based sensing is a promising privacy-preserving alternative to cameras and wearables in settings such as long-term care. Yet detecting quasi-static presence (lying, sitting, or standing with only subtle micro-motions) is difficult for low-resolution SIMO FMCW radar because near-zero Doppler energy is often buried under static clutter. We present Respiratory-Amplification Semi-Static Occupancy (RASSO), an invertible Doppler-domain non-linear remapping that densifies the slow-time FFT (Doppler) grid around 0 m/s before adaptive Capon beamforming. The resulting range-azimuth (RA) maps exhibit higher effective SNR, sharper target peaks, and lower background variance, making thresholding and learning more reliable. On a real nursing-home dataset collected with a short-range 1Tx-3Rx radar, RASSO-RA improves classical detection performance, achieving AUC = 0.981 and recall = 0.920/0.947 at FAR = 1%/5%, outperforming conventional Capon processing and a recent baseline. RASSO-RA also benefits data-driven models: a frame-based CNN reaches 95-99% accuracy and a sequence-based CNN-LSTM reaches 99.4-99.6% accuracy across subjects. A paired session-level bootstrap test confirms statistically significant macro-F1 gains of 2.6-3.6 points (95% confidence intervals above zero) over the non-warped pipeline. These results show that simple Doppler-domain warping before spatial processing can materially improve semi-static occupancy detection with low-resolution radar in real clinical environments.
Conscious Data Contribution via Community-Driven Chain-of-Thought Distillation
Dec 20, 2025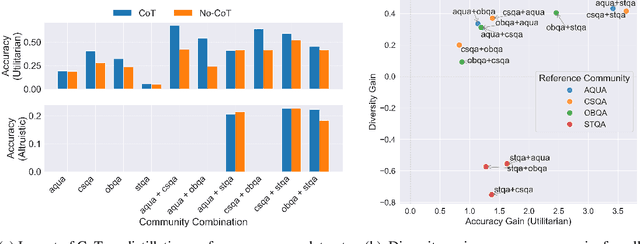
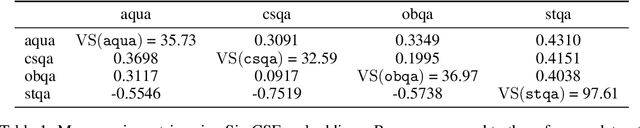
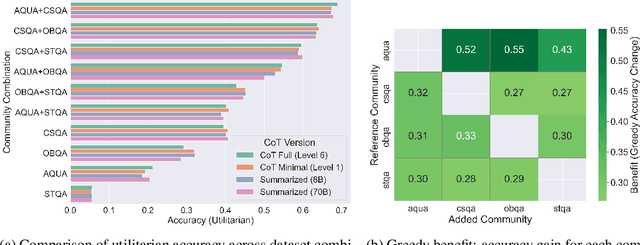
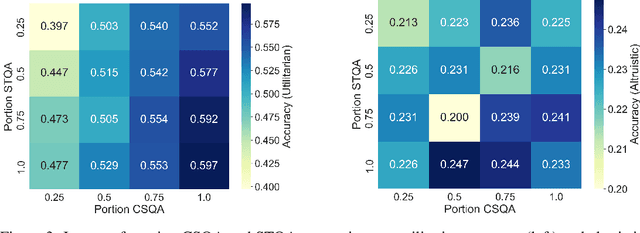
The current era of AI development places a heavy emphasis on training large models on increasingly scaled-up datasets. This paradigm has catalyzed entirely new product categories, such as LLM chatbots, while also raising concerns about data privacy and consumer choice. In this paper, we consider questions of data portability and user autonomy in the context of LLMs that "reason" using chain-of-thought (CoT) traces, computing intermediate text artifacts from user input before producing a final output. We first interpret recent data privacy and portability law to argue that these intermediate computations qualify as users' personal data. Then, building on the existing framework of Conscious Data Contribution, we show how communities who receive low utility from an available model can aggregate and distill their shared knowledge into an alternate model better aligned with their goals. We verify this approach empirically and investigate the effects of community diversity, reasoning granularity, and community size on distillation performance.
Crowding Out The Noise: Algorithmic Collective Action Under Differential Privacy
May 09, 2025The integration of AI into daily life has generated considerable attention and excitement, while also raising concerns about automating algorithmic harms and re-entrenching existing social inequities. While the responsible deployment of trustworthy AI systems is a worthy goal, there are many possible ways to realize it, from policy and regulation to improved algorithm design and evaluation. In fact, since AI trains on social data, there is even a possibility for everyday users, citizens, or workers to directly steer its behavior through Algorithmic Collective Action, by deliberately modifying the data they share with a platform to drive its learning process in their favor. This paper considers how these grassroots efforts to influence AI interact with methods already used by AI firms and governments to improve model trustworthiness. In particular, we focus on the setting where the AI firm deploys a differentially private model, motivated by the growing regulatory focus on privacy and data protection. We investigate how the use of Differentially Private Stochastic Gradient Descent (DPSGD) affects the collective's ability to influence the learning process. Our findings show that while differential privacy contributes to the protection of individual data, it introduces challenges for effective algorithmic collective action. We characterize lower bounds on the success of algorithmic collective action under differential privacy as a function of the collective's size and the firm's privacy parameters, and verify these trends experimentally by simulating collective action during the training of deep neural network classifiers across several datasets.
Say It Another Way: A Framework for User-Grounded Paraphrasing
May 06, 2025Small changes in how a prompt is worded can lead to meaningful differences in the behavior of large language models (LLMs), raising concerns about the stability and reliability of their evaluations. While prior work has explored simple formatting changes, these rarely capture the kinds of natural variation seen in real-world language use. We propose a controlled paraphrasing framework based on a taxonomy of minimal linguistic transformations to systematically generate natural prompt variations. Using the BBQ dataset, we validate our method with both human annotations and automated checks, then use it to study how LLMs respond to paraphrased prompts in stereotype evaluation tasks. Our analysis shows that even subtle prompt modifications can lead to substantial changes in model behavior. These results highlight the need for robust, paraphrase-aware evaluation protocols.
Show, Don't Tell: Uncovering Implicit Character Portrayal using LLMs
Dec 05, 2024



Tools for analyzing character portrayal in fiction are valuable for writers and literary scholars in developing and interpreting compelling stories. Existing tools, such as visualization tools for analyzing fictional characters, primarily rely on explicit textual indicators of character attributes. However, portrayal is often implicit, revealed through actions and behaviors rather than explicit statements. We address this gap by leveraging large language models (LLMs) to uncover implicit character portrayals. We start by generating a dataset for this task with greater cross-topic similarity, lexical diversity, and narrative lengths than existing narrative text corpora such as TinyStories and WritingPrompts. We then introduce LIIPA (LLMs for Inferring Implicit Portrayal for Character Analysis), a framework for prompting LLMs to uncover character portrayals. LIIPA can be configured to use various types of intermediate computation (character attribute word lists, chain-of-thought) to infer how fictional characters are portrayed in the source text. We find that LIIPA outperforms existing approaches, and is more robust to increasing character counts (number of unique persons depicted) due to its ability to utilize full narrative context. Lastly, we investigate the sensitivity of portrayal estimates to character demographics, identifying a fairness-accuracy tradeoff among methods in our LIIPA framework -- a phenomenon familiar within the algorithmic fairness literature. Despite this tradeoff, all LIIPA variants consistently outperform non-LLM baselines in both fairness and accuracy. Our work demonstrates the potential benefits of using LLMs to analyze complex characters and to better understand how implicit portrayal biases may manifest in narrative texts.
Promoting User Data Autonomy During the Dissolution of a Monopolistic Firm
Nov 20, 2024



The deployment of AI in consumer products is currently focused on the use of so-called foundation models, large neural networks pre-trained on massive corpora of digital records. This emphasis on scaling up datasets and pre-training computation raises the risk of further consolidating the industry, and enabling monopolistic (or oligopolistic) behavior. Judges and regulators seeking to improve market competition may employ various remedies. This paper explores dissolution -- the breaking up of a monopolistic entity into smaller firms -- as one such remedy, focusing in particular on the technical challenges and opportunities involved in the breaking up of large models and datasets. We show how the framework of Conscious Data Contribution can enable user autonomy during under dissolution. Through a simulation study, we explore how fine-tuning and the phenomenon of "catastrophic forgetting" could actually prove beneficial as a type of machine unlearning that allows users to specify which data they want used for what purposes.