 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConscious Data Contribution via Community-Driven Chain-of-Thought Distillation
Dec 20, 2025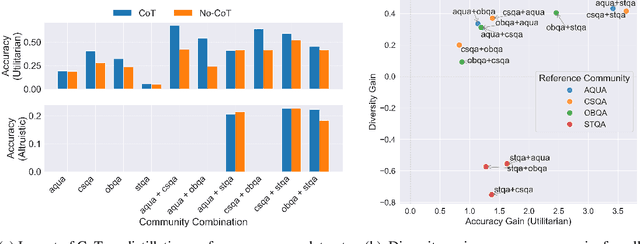
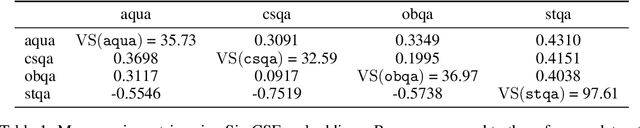
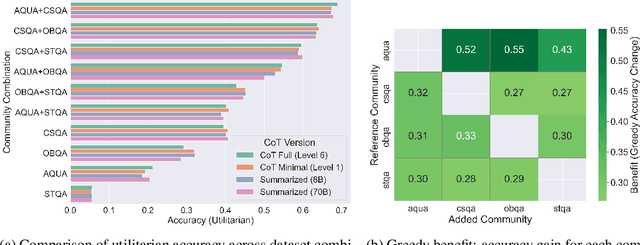
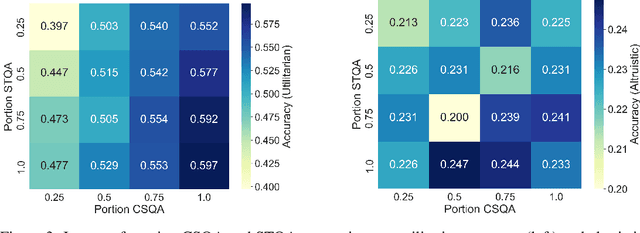
The current era of AI development places a heavy emphasis on training large models on increasingly scaled-up datasets. This paradigm has catalyzed entirely new product categories, such as LLM chatbots, while also raising concerns about data privacy and consumer choice. In this paper, we consider questions of data portability and user autonomy in the context of LLMs that "reason" using chain-of-thought (CoT) traces, computing intermediate text artifacts from user input before producing a final output. We first interpret recent data privacy and portability law to argue that these intermediate computations qualify as users' personal data. Then, building on the existing framework of Conscious Data Contribution, we show how communities who receive low utility from an available model can aggregate and distill their shared knowledge into an alternate model better aligned with their goals. We verify this approach empirically and investigate the effects of community diversity, reasoning granularity, and community size on distillation performance.
Towards Fair In-Context Learning with Tabular Foundation Models
May 15, 2025Tabular foundational models have exhibited strong in-context learning (ICL) capabilities on structured data, allowing them to make accurate predictions on test sets without parameter updates, using training examples as context. This emerging approach positions itself as a competitive alternative to traditional gradient-boosted tree methods. However, while biases in conventional machine learning models are well documented, it remains unclear how these biases manifest in tabular ICL. The paper investigates the fairness implications of tabular ICL and explores three preprocessing strategies--correlation removal, group-balanced demonstration selection, and uncertainty-based demonstration selection--to address bias. Comprehensive experiments indicate that uncertainty-based demonstration selection consistently enhances group fairness of in-context predictions. The source code for reproducing the results of this work can be found at https://github.com/patrikken/Fair-TabICL.
Crowding Out The Noise: Algorithmic Collective Action Under Differential Privacy
May 09, 2025The integration of AI into daily life has generated considerable attention and excitement, while also raising concerns about automating algorithmic harms and re-entrenching existing social inequities. While the responsible deployment of trustworthy AI systems is a worthy goal, there are many possible ways to realize it, from policy and regulation to improved algorithm design and evaluation. In fact, since AI trains on social data, there is even a possibility for everyday users, citizens, or workers to directly steer its behavior through Algorithmic Collective Action, by deliberately modifying the data they share with a platform to drive its learning process in their favor. This paper considers how these grassroots efforts to influence AI interact with methods already used by AI firms and governments to improve model trustworthiness. In particular, we focus on the setting where the AI firm deploys a differentially private model, motivated by the growing regulatory focus on privacy and data protection. We investigate how the use of Differentially Private Stochastic Gradient Descent (DPSGD) affects the collective's ability to influence the learning process. Our findings show that while differential privacy contributes to the protection of individual data, it introduces challenges for effective algorithmic collective action. We characterize lower bounds on the success of algorithmic collective action under differential privacy as a function of the collective's size and the firm's privacy parameters, and verify these trends experimentally by simulating collective action during the training of deep neural network classifiers across several datasets.
Adaptive Group Robust Ensemble Knowledge Distillation
Nov 22, 2024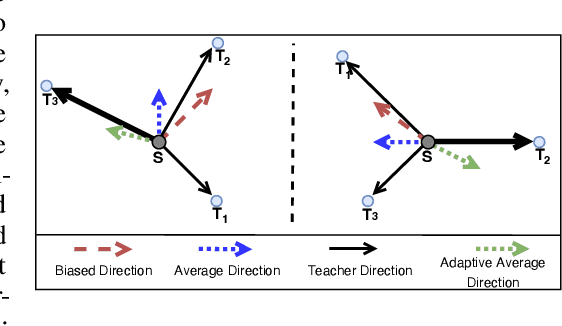
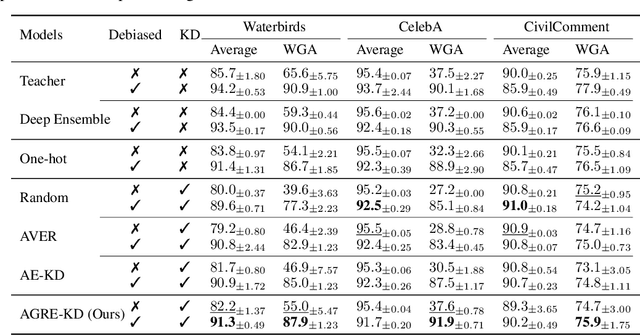
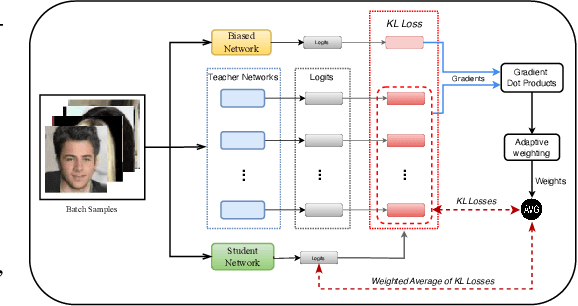
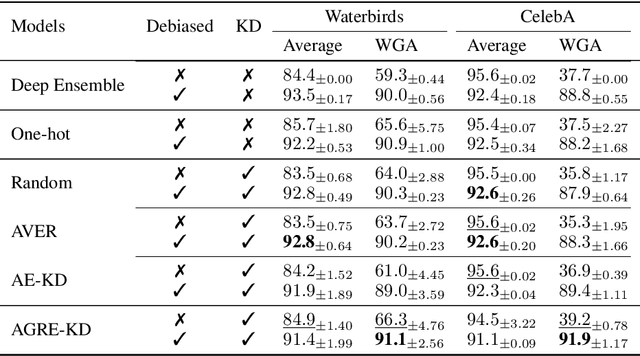
Neural networks can learn spurious correlations in the data, often leading to performance disparity for underrepresented subgroups. Studies have demonstrated that the disparity is amplified when knowledge is distilled from a complex teacher model to a relatively "simple" student model. Prior work has shown that ensemble deep learning methods can improve the performance of the worst-case subgroups; however, it is unclear if this advantage carries over when distilling knowledge from an ensemble of teachers, especially when the teacher models are debiased. This study demonstrates that traditional ensemble knowledge distillation can significantly drop the performance of the worst-case subgroups in the distilled student model even when the teacher models are debiased. To overcome this, we propose Adaptive Group Robust Ensemble Knowledge Distillation (AGRE-KD), a simple ensembling strategy to ensure that the student model receives knowledge beneficial for unknown underrepresented subgroups. Leveraging an additional biased model, our method selectively chooses teachers whose knowledge would better improve the worst-performing subgroups by upweighting the teachers with gradient directions deviating from the biased model. Our experiments on several datasets demonstrate the superiority of the proposed ensemble distillation technique and show that it can even outperform classic model ensembles based on majority voting.
SoK: Taming the Triangle -- On the Interplays between Fairness, Interpretability and Privacy in Machine Learning
Dec 22, 2023

Machine learning techniques are increasingly used for high-stakes decision-making, such as college admissions, loan attribution or recidivism prediction. Thus, it is crucial to ensure that the models learnt can be audited or understood by human users, do not create or reproduce discrimination or bias, and do not leak sensitive information regarding their training data. Indeed, interpretability, fairness and privacy are key requirements for the development of responsible machine learning, and all three have been studied extensively during the last decade. However, they were mainly considered in isolation, while in practice they interplay with each other, either positively or negatively. In this Systematization of Knowledge (SoK) paper, we survey the literature on the interactions between these three desiderata. More precisely, for each pairwise interaction, we summarize the identified synergies and tensions. These findings highlight several fundamental theoretical and empirical conflicts, while also demonstrating that jointly considering these different requirements is challenging when one aims at preserving a high level of utility. To solve this issue, we also discuss possible conciliation mechanisms, showing that a careful design can enable to successfully handle these different concerns in practice.
Probabilistic Dataset Reconstruction from Interpretable Models
Aug 29, 2023
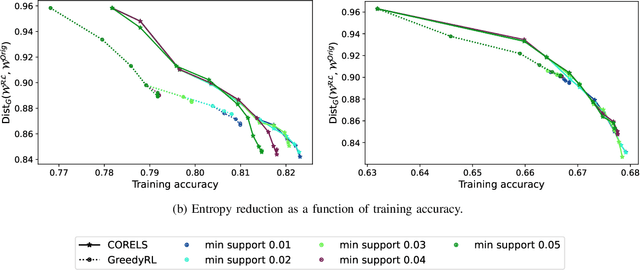
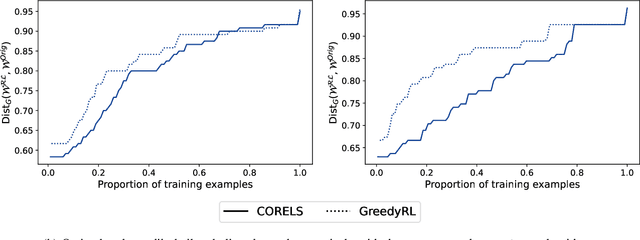
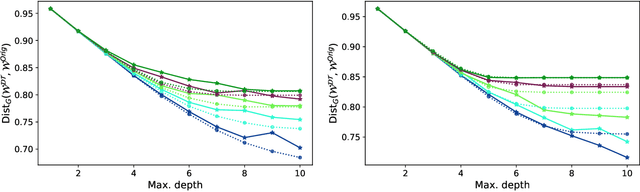
Interpretability is often pointed out as a key requirement for trustworthy machine learning. However, learning and releasing models that are inherently interpretable leaks information regarding the underlying training data. As such disclosure may directly conflict with privacy, a precise quantification of the privacy impact of such breach is a fundamental problem. For instance, previous work have shown that the structure of a decision tree can be leveraged to build a probabilistic reconstruction of its training dataset, with the uncertainty of the reconstruction being a relevant metric for the information leak. In this paper, we propose of a novel framework generalizing these probabilistic reconstructions in the sense that it can handle other forms of interpretable models and more generic types of knowledge. In addition, we demonstrate that under realistic assumptions regarding the interpretable models' structure, the uncertainty of the reconstruction can be computed efficiently. Finally, we illustrate the applicability of our approach on both decision trees and rule lists, by comparing the theoretical information leak associated to either exact or heuristic learning algorithms. Our results suggest that optimal interpretable models are often more compact and leak less information regarding their training data than greedily-built ones, for a given accuracy level.
Fairness Under Demographic Scarce Regime
Jul 24, 2023

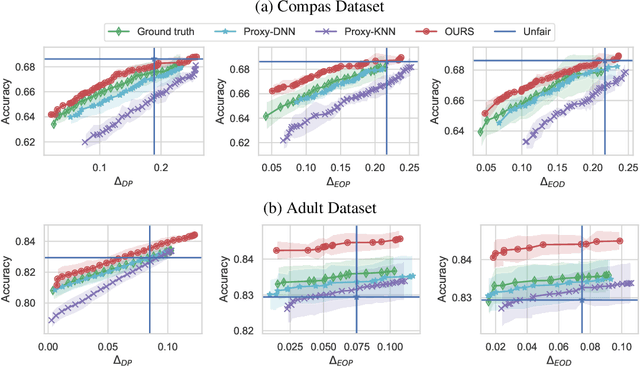

Most existing works on fairness assume the model has full access to demographic information. However, there exist scenarios where demographic information is partially available because a record was not maintained throughout data collection or due to privacy reasons. This setting is known as demographic scarce regime. Prior research have shown that training an attribute classifier to replace the missing sensitive attributes (proxy) can still improve fairness. However, the use of proxy-sensitive attributes worsens fairness-accuracy trade-offs compared to true sensitive attributes. To address this limitation, we propose a framework to build attribute classifiers that achieve better fairness-accuracy trade-offs. Our method introduces uncertainty awareness in the attribute classifier and enforces fairness on samples with demographic information inferred with the lowest uncertainty. We show empirically that enforcing fairness constraints on samples with uncertain sensitive attributes is detrimental to fairness and accuracy. Our experiments on two datasets showed that the proposed framework yields models with significantly better fairness-accuracy trade-offs compared to classic attribute classifiers. Surprisingly, our framework outperforms models trained with constraints on the true sensitive attributes.
Learning Hybrid Interpretable Models: Theory, Taxonomy, and Methods
Mar 08, 2023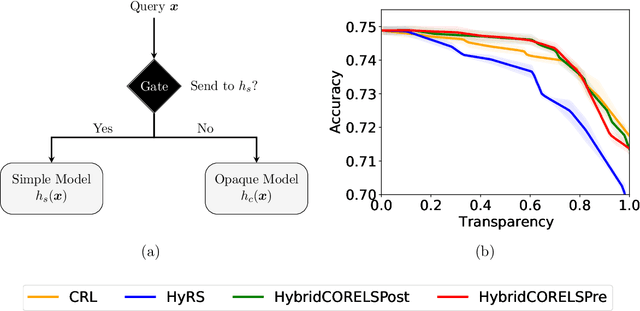
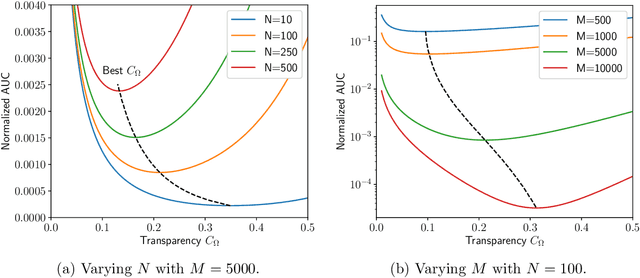
A hybrid model involves the cooperation of an interpretable model and a complex black box. At inference, any input of the hybrid model is assigned to either its interpretable or complex component based on a gating mechanism. The advantages of such models over classical ones are two-fold: 1) They grant users precise control over the level of transparency of the system and 2) They can potentially perform better than a standalone black box since redirecting some of the inputs to an interpretable model implicitly acts as regularization. Still, despite their high potential, hybrid models remain under-studied in the interpretability/explainability literature. In this paper, we remedy this fact by presenting a thorough investigation of such models from three perspectives: Theory, Taxonomy, and Methods. First, we explore the theory behind the generalization of hybrid models from the Probably-Approximately-Correct (PAC) perspective. A consequence of our PAC guarantee is the existence of a sweet spot for the optimal transparency of the system. When such a sweet spot is attained, a hybrid model can potentially perform better than a standalone black box. Secondly, we provide a general taxonomy for the different ways of training hybrid models: the Post-Black-Box and Pre-Black-Box paradigms. These approaches differ in the order in which the interpretable and complex components are trained. We show where the state-of-the-art hybrid models Hybrid-Rule-Set and Companion-Rule-List fall in this taxonomy. Thirdly, we implement the two paradigms in a single method: HybridCORELS, which extends the CORELS algorithm to hybrid modeling. By leveraging CORELS, HybridCORELS provides a certificate of optimality of its interpretable component and precise control over transparency. We finally show empirically that HybridCORELS is competitive with existing hybrid models, and performs just as well as a standalone black box (or even better) while being partly transparent.
Exploiting Fairness to Enhance Sensitive Attributes Reconstruction
Sep 02, 2022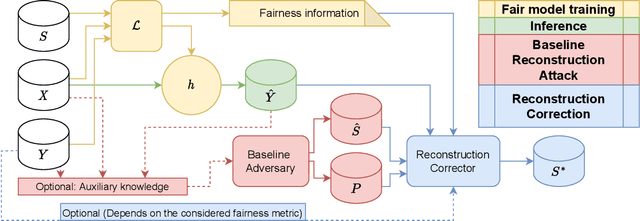
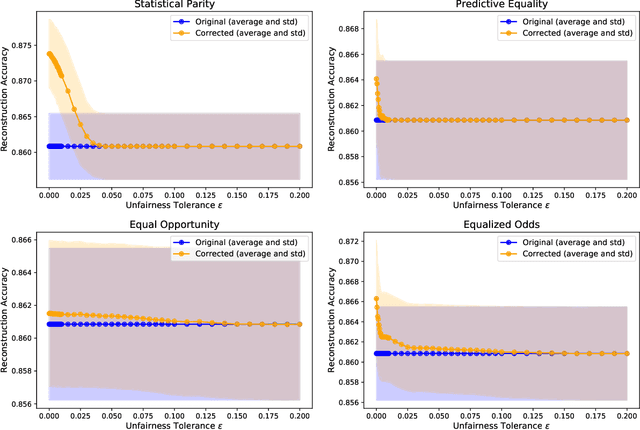
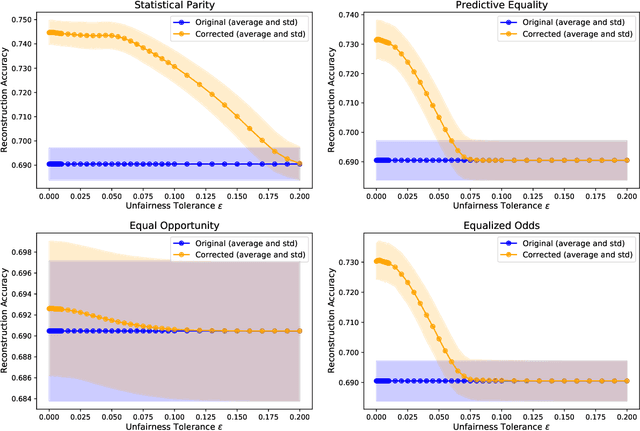
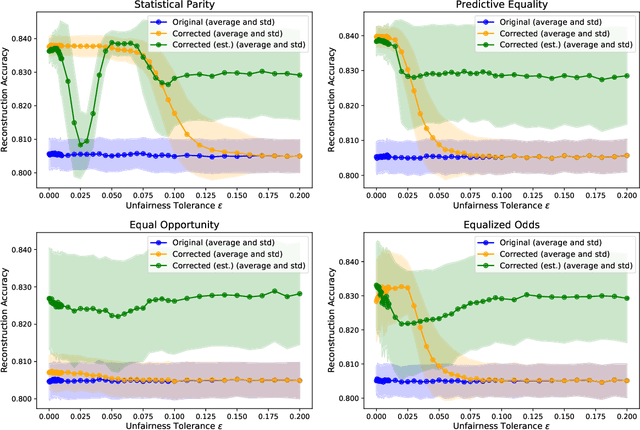
In recent years, a growing body of work has emerged on how to learn machine learning models under fairness constraints, often expressed with respect to some sensitive attributes. In this work, we consider the setting in which an adversary has black-box access to a target model and show that information about this model's fairness can be exploited by the adversary to enhance his reconstruction of the sensitive attributes of the training data. More precisely, we propose a generic reconstruction correction method, which takes as input an initial guess made by the adversary and corrects it to comply with some user-defined constraints (such as the fairness information) while minimizing the changes in the adversary's guess. The proposed method is agnostic to the type of target model, the fairness-aware learning method as well as the auxiliary knowledge of the adversary. To assess the applicability of our approach, we have conducted a thorough experimental evaluation on two state-of-the-art fair learning methods, using four different fairness metrics with a wide range of tolerances and with three datasets of diverse sizes and sensitive attributes. The experimental results demonstrate the effectiveness of the proposed approach to improve the reconstruction of the sensitive attributes of the training set.
Fooling SHAP with Stealthily Biased Sampling
May 30, 2022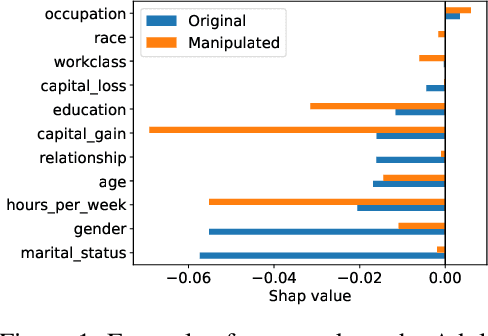
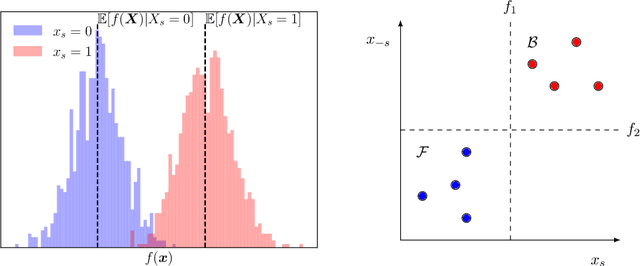

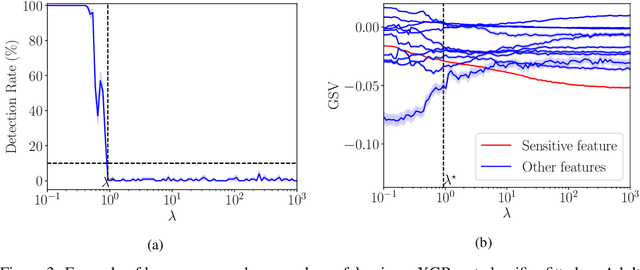
SHAP explanations aim at identifying which features contribute the most to the difference in model prediction at a specific input versus a background distribution. Recent studies have shown that they can be manipulated by malicious adversaries to produce arbitrary desired explanations. However, existing attacks focus solely on altering the black-box model itself. In this paper, we propose a complementary family of attacks that leave the model intact and manipulate SHAP explanations using stealthily biased sampling of the data points used to approximate expectations w.r.t the background distribution. In the context of fairness audit, we show that our attack can reduce the importance of a sensitive feature when explaining the difference in outcomes between groups, while remaining undetected. These results highlight the manipulability of SHAP explanations and encourage auditors to treat post-hoc explanations with skepticism.