 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing the risk of fairwashing
Paper and Code

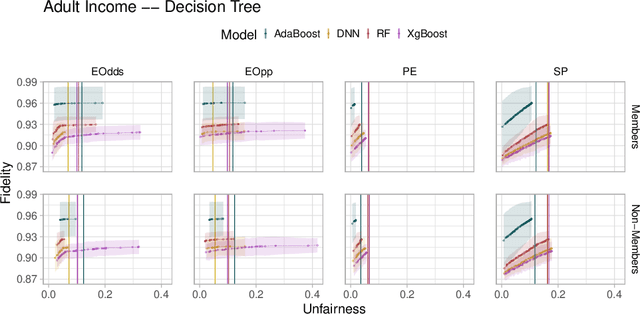
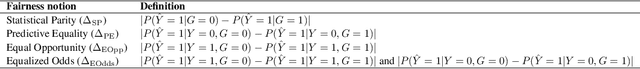

Fairwashing refers to the risk that an unfair black-box model can be explained by a fairer model through post-hoc explanations' manipulation. However, to realize this, the post-hoc explanation model must produce different predictions than the original black-box on some inputs, leading to a decrease in the fidelity imposed by the difference in unfairness. In this paper, our main objective is to characterize the risk of fairwashing attacks, in particular by investigating the fidelity-unfairness trade-off. First, we demonstrate through an in-depth empirical study on black-box models trained on several real-world datasets and for several statistical notions of fairness that it is possible to build high-fidelity explanation models with low unfairness. For instance, we find that fairwashed explanation models can exhibit up to $99.20\%$ fidelity to the black-box models they explain while being $50\%$ less unfair. These results suggest that fidelity alone should not be used as a proxy for the quality of black-box explanations. Second, we show that fairwashed explanation models can generalize beyond the suing group (\emph{i.e.}, data points that are being explained), which will only worsen as more stable fairness methods get developed. Finally, we demonstrate that fairwashing attacks can transfer across black-box models, meaning that other black-box models can perform fairwashing without explicitly using their predictions.