 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Admissible Heuristics via Cost Partitioning
Jun 03, 2026Admissible heuristics are essential for optimal planning, yet learning them remains challenging due to the risk of overestimation. Cost partitioning combines multiple abstraction heuristics while preserving admissibility, but computing optimal partitions online is expensive. We propose a framework that learns to infer admissible cost partitions by leveraging the Lagrangian dual equivalence between cost partitioning and multiplier prediction. Planning states and patterns are encoded as labelled graphs, and an action-centric variant of the Weisfeiler-Leman algorithm extracts structural feature vectors. A deep architecture with axial self-attention and a softmax output layer maps these features to cost weights that satisfy the partition constraints by construction, ensuring admissibility. Experiments demonstrate reduced node expansions compared to suboptimal partitioning baselines while maintaining strict admissibility. To our knowledge, this is the first machine-learned heuristic guaranteed to be admissible.
Smooth Sensitivity for Learning Differentially-Private yet Accurate Rule Lists
Mar 18, 2024


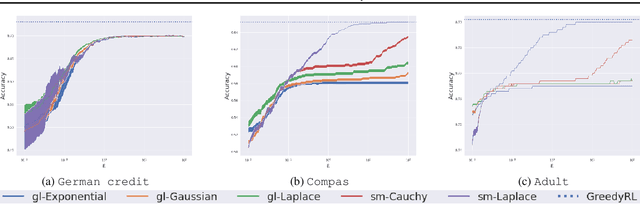
Differentially-private (DP) mechanisms can be embedded into the design of a machine learningalgorithm to protect the resulting model against privacy leakage, although this often comes with asignificant loss of accuracy. In this paper, we aim at improving this trade-off for rule lists modelsby establishing the smooth sensitivity of the Gini impurity and leveraging it to propose a DP greedyrule list algorithm. In particular, our theoretical analysis and experimental results demonstrate thatthe DP rule lists models integrating smooth sensitivity have higher accuracy that those using otherDP frameworks based on global sensitivity.
SoK: Taming the Triangle -- On the Interplays between Fairness, Interpretability and Privacy in Machine Learning
Dec 22, 2023

Machine learning techniques are increasingly used for high-stakes decision-making, such as college admissions, loan attribution or recidivism prediction. Thus, it is crucial to ensure that the models learnt can be audited or understood by human users, do not create or reproduce discrimination or bias, and do not leak sensitive information regarding their training data. Indeed, interpretability, fairness and privacy are key requirements for the development of responsible machine learning, and all three have been studied extensively during the last decade. However, they were mainly considered in isolation, while in practice they interplay with each other, either positively or negatively. In this Systematization of Knowledge (SoK) paper, we survey the literature on the interactions between these three desiderata. More precisely, for each pairwise interaction, we summarize the identified synergies and tensions. These findings highlight several fundamental theoretical and empirical conflicts, while also demonstrating that jointly considering these different requirements is challenging when one aims at preserving a high level of utility. To solve this issue, we also discuss possible conciliation mechanisms, showing that a careful design can enable to successfully handle these different concerns in practice.
Probabilistic Dataset Reconstruction from Interpretable Models
Aug 29, 2023
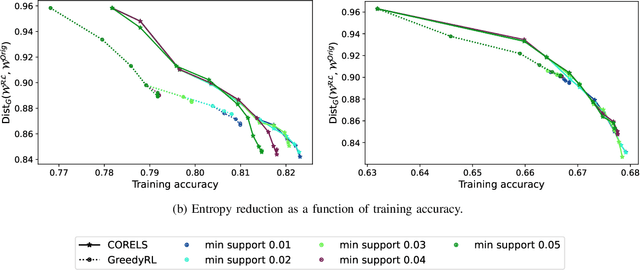
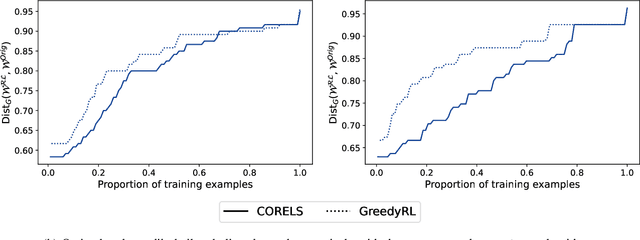
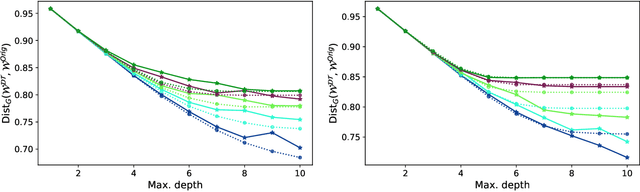
Interpretability is often pointed out as a key requirement for trustworthy machine learning. However, learning and releasing models that are inherently interpretable leaks information regarding the underlying training data. As such disclosure may directly conflict with privacy, a precise quantification of the privacy impact of such breach is a fundamental problem. For instance, previous work have shown that the structure of a decision tree can be leveraged to build a probabilistic reconstruction of its training dataset, with the uncertainty of the reconstruction being a relevant metric for the information leak. In this paper, we propose of a novel framework generalizing these probabilistic reconstructions in the sense that it can handle other forms of interpretable models and more generic types of knowledge. In addition, we demonstrate that under realistic assumptions regarding the interpretable models' structure, the uncertainty of the reconstruction can be computed efficiently. Finally, we illustrate the applicability of our approach on both decision trees and rule lists, by comparing the theoretical information leak associated to either exact or heuristic learning algorithms. Our results suggest that optimal interpretable models are often more compact and leak less information regarding their training data than greedily-built ones, for a given accuracy level.
Learning Optimal Fair Scoring Systems for Multi-Class Classification
Apr 11, 2023

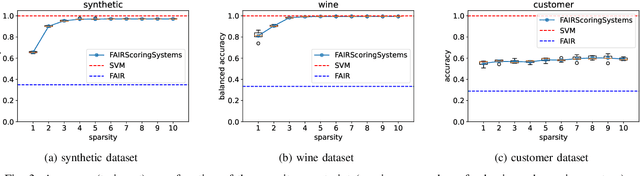

Machine Learning models are increasingly used for decision making, in particular in high-stakes applications such as credit scoring, medicine or recidivism prediction. However, there are growing concerns about these models with respect to their lack of interpretability and the undesirable biases they can generate or reproduce. While the concepts of interpretability and fairness have been extensively studied by the scientific community in recent years, few works have tackled the general multi-class classification problem under fairness constraints, and none of them proposes to generate fair and interpretable models for multi-class classification. In this paper, we use Mixed-Integer Linear Programming (MILP) techniques to produce inherently interpretable scoring systems under sparsity and fairness constraints, for the general multi-class classification setup. Our work generalizes the SLIM (Supersparse Linear Integer Models) framework that was proposed by Rudin and Ustun to learn optimal scoring systems for binary classification. The use of MILP techniques allows for an easy integration of diverse operational constraints (such as, but not restricted to, fairness or sparsity), but also for the building of certifiably optimal models (or sub-optimal models with bounded optimality gap).
Exploiting Fairness to Enhance Sensitive Attributes Reconstruction
Sep 02, 2022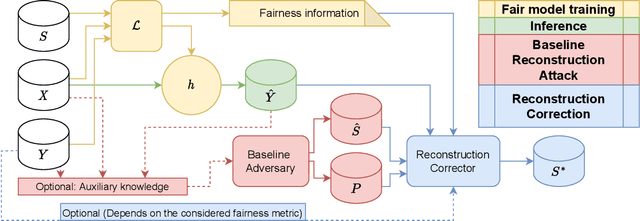
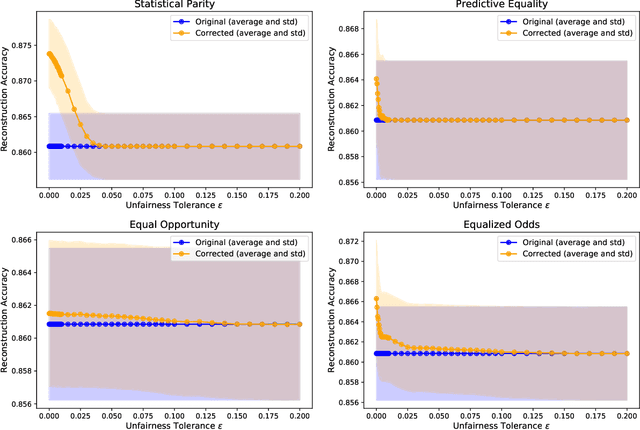
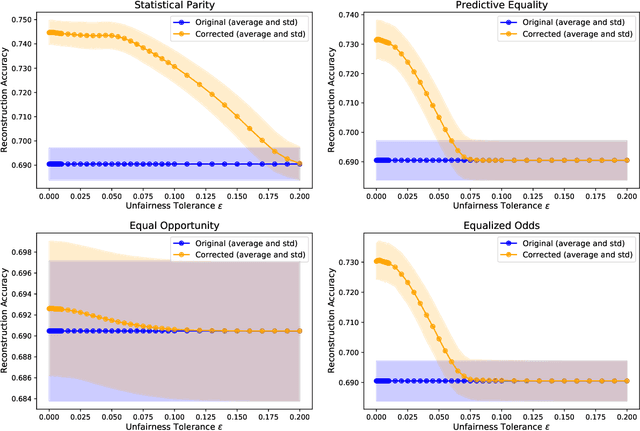
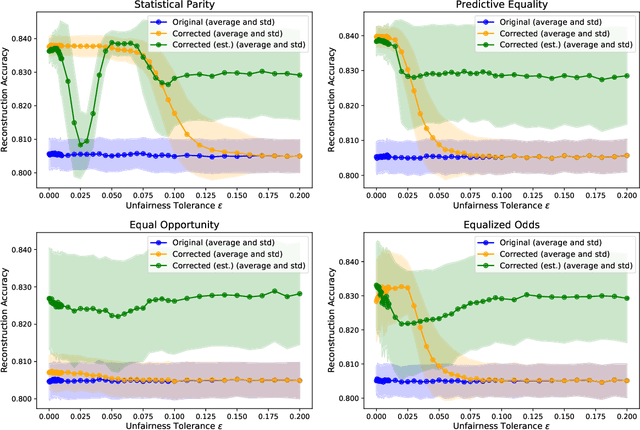
In recent years, a growing body of work has emerged on how to learn machine learning models under fairness constraints, often expressed with respect to some sensitive attributes. In this work, we consider the setting in which an adversary has black-box access to a target model and show that information about this model's fairness can be exploited by the adversary to enhance his reconstruction of the sensitive attributes of the training data. More precisely, we propose a generic reconstruction correction method, which takes as input an initial guess made by the adversary and corrects it to comply with some user-defined constraints (such as the fairness information) while minimizing the changes in the adversary's guess. The proposed method is agnostic to the type of target model, the fairness-aware learning method as well as the auxiliary knowledge of the adversary. To assess the applicability of our approach, we have conducted a thorough experimental evaluation on two state-of-the-art fair learning methods, using four different fairness metrics with a wide range of tolerances and with three datasets of diverse sizes and sensitive attributes. The experimental results demonstrate the effectiveness of the proposed approach to improve the reconstruction of the sensitive attributes of the training set.
Optimizing Binary Decision Diagrams with MaxSAT for classification
Mar 21, 2022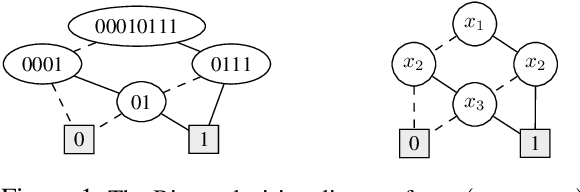
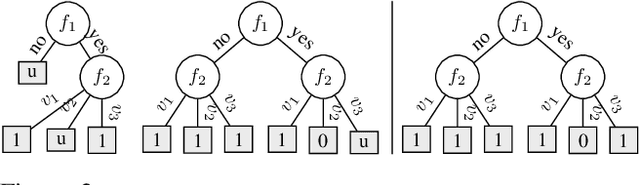

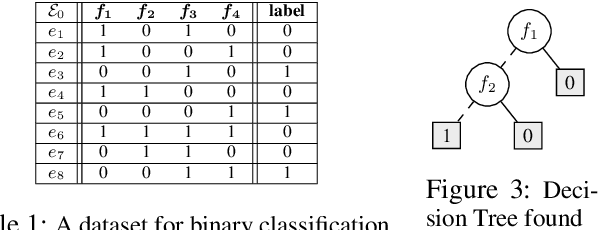
The growing interest in explainable artificial intelligence (XAI) for critical decision making motivates the need for interpretable machine learning (ML) models. In fact, due to their structure (especially with small sizes), these models are inherently understandable by humans. Recently, several exact methods for computing such models are proposed to overcome weaknesses of traditional heuristic methods by providing more compact models or better prediction quality. Despite their compressed representation of Boolean functions, Binary decision diagrams (BDDs) did not gain enough interest as other interpretable ML models. In this paper, we first propose SAT-based models for learning optimal BDDs (in terms of the number of features) that classify all input examples. Then, we lift the encoding to a MaxSAT model to learn optimal BDDs in limited depths, that maximize the number of examples correctly classified. Finally, we tackle the fragmentation problem by introducing a method to merge compatible subtrees for the BDDs found via the MaxSAT model. Our empirical study shows clear benefits of the proposed approach in terms of prediction quality and intrepretability (i.e., lighter size) compared to the state-of-the-art approaches.
Learning Fair Rule Lists
Sep 09, 2019
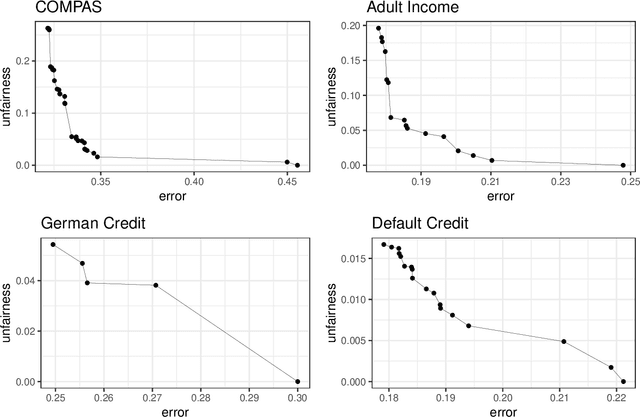

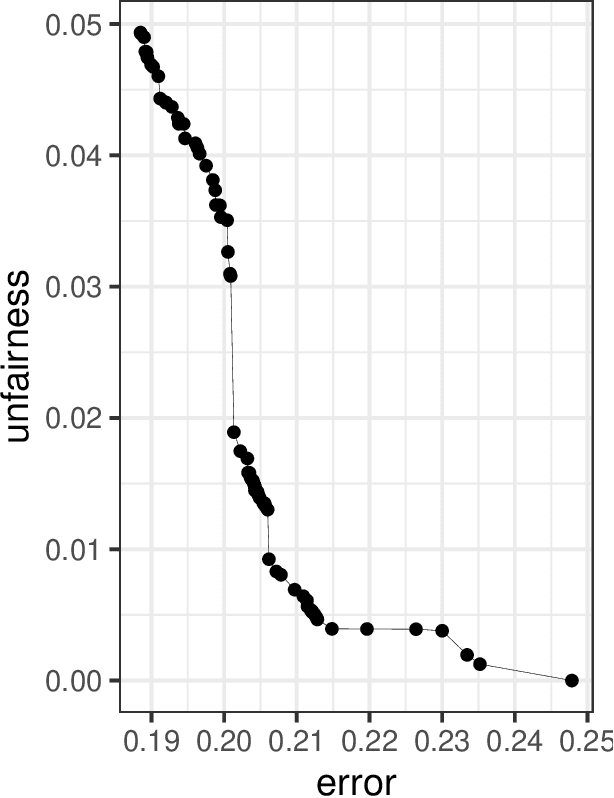
The widespread use of machine learning models, especially within the context of decision-making systems impacting individuals, raises many ethical issues with respect to fairness and interpretability of these models. While the research in these domains is booming, very few works have addressed these two issues simultaneously. To solve this shortcoming, we propose FairCORELS, a supervised learning algorithm whose objective is to learn at the same time fair and interpretable models. FairCORELS is a multi-objective variant of CORELS, a branch-and-bound algorithm, designed to compute accurate and interpretable rule lists. By jointly addressing fairness and interpretability, FairCORELS can achieve better fairness/accuracy tradeoffs compared to existing methods, as demonstrated by the empirical evaluation performed on real datasets. Our paper also contains additional contributions regarding the search strategies for optimizing the multi-objective function integrating both fairness, accuracy and interpretability.
Constraint programming for planning test campaigns of communications satellites
Jan 23, 2017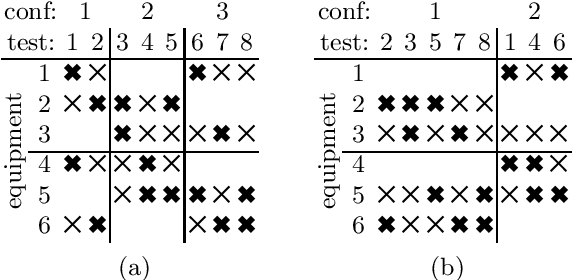
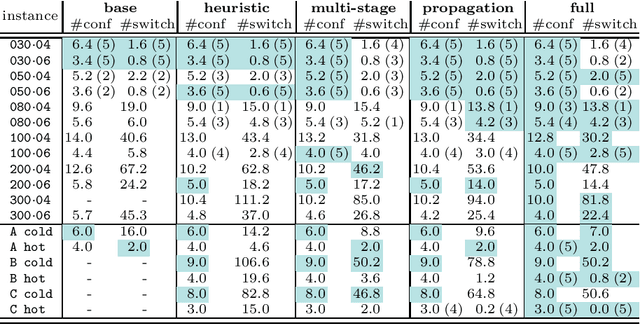
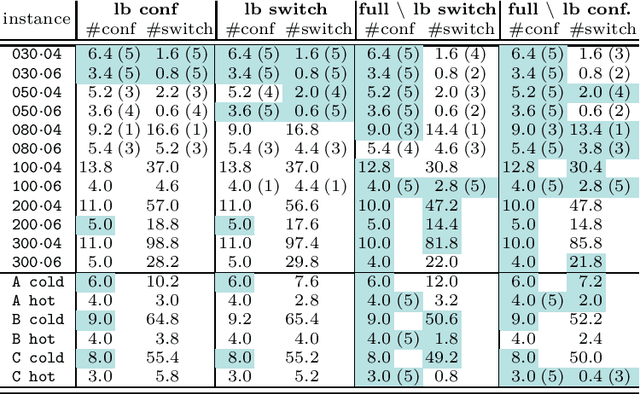
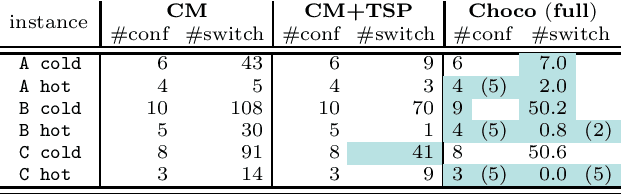
The payload of communications satellites must go through a series of tests to assert their ability to survive in space. Each test involves some equipment of the payload to be active, which has an impact on the temperature of the payload. Sequencing these tests in a way that ensures the thermal stability of the payload and minimizes the overall duration of the test campaign is a very important objective for satellite manufacturers. The problem can be decomposed in two sub-problems corresponding to two objectives: First, the number of distinct configurations necessary to run the tests must be minimized. This can be modeled as packing the tests into configurations, and we introduce a set of implied constraints to improve the lower bound of the model. Second, tests must be sequenced so that the number of times an equipment unit has to be switched on or off is minimized. We model this aspect using the constraint Switch, where a buffer with limited capacity represents the currently active equipment units, and we introduce an improvement of the propagation algorithm for this constraint. We then introduce a search strategy in which we sequentially solve the sub-problems (packing and sequencing). Experiments conducted on real and random instances show the respective interest of our contributions.