 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Counterfactuals to Trees: Competitive Analysis of Model Extraction Attacks
Feb 07, 2025The advent of Machine Learning as a Service (MLaaS) has heightened the trade-off between model explainability and security. In particular, explainability techniques, such as counterfactual explanations, inadvertently increase the risk of model extraction attacks, enabling unauthorized replication of proprietary models. In this paper, we formalize and characterize the risks and inherent complexity of model reconstruction, focusing on the "oracle'' queries required for faithfully inferring the underlying prediction function. We present the first formal analysis of model extraction attacks through the lens of competitive analysis, establishing a foundational framework to evaluate their efficiency. Focusing on models based on additive decision trees (e.g., decision trees, gradient boosting, and random forests), we introduce novel reconstruction algorithms that achieve provably perfect fidelity while demonstrating strong anytime performance. Our framework provides theoretical bounds on the query complexity for extracting tree-based model, offering new insights into the security vulnerabilities of their deployment.
Fairness and Sparsity within Rashomon sets: Enumeration-Free Exploration and Characterization
Feb 07, 2025



We introduce an enumeration-free method based on mathematical programming to precisely characterize various properties such as fairness or sparsity within the set of "good models", known as Rashomon set. This approach is generically applicable to any hypothesis class, provided that a mathematical formulation of the model learning task exists. It offers a structured framework to define the notion of business necessity and evaluate how fairness can be improved or degraded towards a specific protected group, while remaining within the Rashomon set and maintaining any desired sparsity level. We apply our approach to two hypothesis classes: scoring systems and decision diagrams, leveraging recent mathematical programming formulations for training such models. As seen in our experiments, the method comprehensively and certifiably quantifies trade-offs between predictive performance, sparsity, and fairness. We observe that a wide range of fairness values are attainable, ranging from highly favorable to significantly unfavorable for a protected group, while staying within less than 1% of the best possible training accuracy for the hypothesis class. Additionally, we observe that sparsity constraints limit these trade-offs and may disproportionately harm specific subgroups. As we evidenced, thoroughly characterizing the tensions between these key aspects is critical for an informed and accountable selection of models.
Training Set Reconstruction from Differentially Private Forests: How Effective is DP?
Feb 07, 2025



Recent research has shown that machine learning models are vulnerable to privacy attacks targeting their training data. Differential privacy (DP) has become a widely adopted countermeasure, as it offers rigorous privacy protections. In this paper, we introduce a reconstruction attack targeting state-of-the-art $\varepsilon$-DP random forests. By leveraging a constraint programming model that incorporates knowledge of the forest's structure and DP mechanism characteristics, our approach formally reconstructs the most likely dataset that could have produced a given forest. Through extensive computational experiments, we examine the interplay between model utility, privacy guarantees, and reconstruction accuracy across various configurations. Our results reveal that random forests trained with meaningful DP guarantees can still leak substantial portions of their training data. Specifically, while DP reduces the success of reconstruction attacks, the only forests fully robust to our attack exhibit predictive performance no better than a constant classifier. Building on these insights, we provide practical recommendations for the construction of DP random forests that are more resilient to reconstruction attacks and maintain non-trivial predictive performance.
Smooth Sensitivity for Learning Differentially-Private yet Accurate Rule Lists
Mar 18, 2024


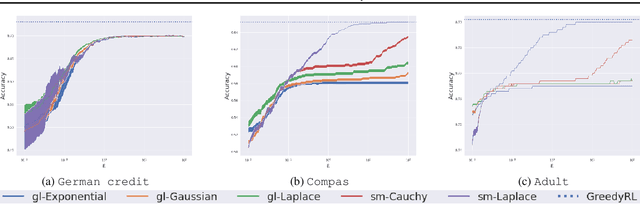
Differentially-private (DP) mechanisms can be embedded into the design of a machine learningalgorithm to protect the resulting model against privacy leakage, although this often comes with asignificant loss of accuracy. In this paper, we aim at improving this trade-off for rule lists modelsby establishing the smooth sensitivity of the Gini impurity and leveraging it to propose a DP greedyrule list algorithm. In particular, our theoretical analysis and experimental results demonstrate thatthe DP rule lists models integrating smooth sensitivity have higher accuracy that those using otherDP frameworks based on global sensitivity.
Trained Random Forests Completely Reveal your Dataset
Feb 29, 2024



We introduce an optimization-based reconstruction attack capable of completely or near-completely reconstructing a dataset utilized for training a random forest. Notably, our approach relies solely on information readily available in commonly used libraries such as scikit-learn. To achieve this, we formulate the reconstruction problem as a combinatorial problem under a maximum likelihood objective. We demonstrate that this problem is NP-hard, though solvable at scale using constraint programming -- an approach rooted in constraint propagation and solution-domain reduction. Through an extensive computational investigation, we demonstrate that random forests trained without bootstrap aggregation but with feature randomization are susceptible to a complete reconstruction. This holds true even with a small number of trees. Even with bootstrap aggregation, the majority of the data can also be reconstructed. These findings underscore a critical vulnerability inherent in widely adopted ensemble methods, warranting attention and mitigation. Although the potential for such reconstruction attacks has been discussed in privacy research, our study provides clear empirical evidence of their practicability.
SoK: Taming the Triangle -- On the Interplays between Fairness, Interpretability and Privacy in Machine Learning
Dec 22, 2023

Machine learning techniques are increasingly used for high-stakes decision-making, such as college admissions, loan attribution or recidivism prediction. Thus, it is crucial to ensure that the models learnt can be audited or understood by human users, do not create or reproduce discrimination or bias, and do not leak sensitive information regarding their training data. Indeed, interpretability, fairness and privacy are key requirements for the development of responsible machine learning, and all three have been studied extensively during the last decade. However, they were mainly considered in isolation, while in practice they interplay with each other, either positively or negatively. In this Systematization of Knowledge (SoK) paper, we survey the literature on the interactions between these three desiderata. More precisely, for each pairwise interaction, we summarize the identified synergies and tensions. These findings highlight several fundamental theoretical and empirical conflicts, while also demonstrating that jointly considering these different requirements is challenging when one aims at preserving a high level of utility. To solve this issue, we also discuss possible conciliation mechanisms, showing that a careful design can enable to successfully handle these different concerns in practice.
Probabilistic Dataset Reconstruction from Interpretable Models
Aug 29, 2023
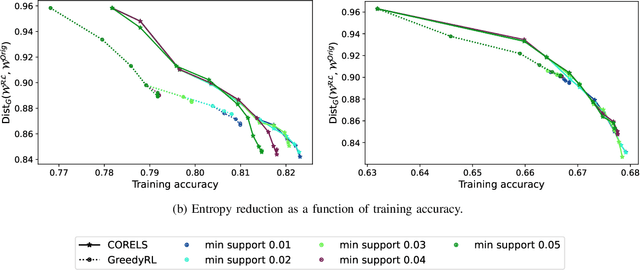
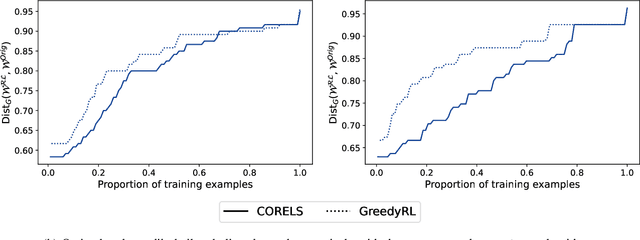
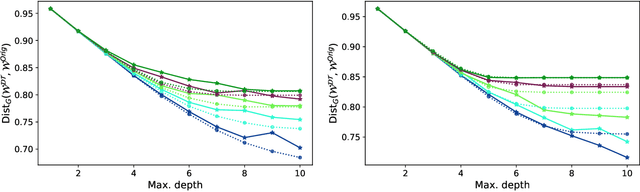
Interpretability is often pointed out as a key requirement for trustworthy machine learning. However, learning and releasing models that are inherently interpretable leaks information regarding the underlying training data. As such disclosure may directly conflict with privacy, a precise quantification of the privacy impact of such breach is a fundamental problem. For instance, previous work have shown that the structure of a decision tree can be leveraged to build a probabilistic reconstruction of its training dataset, with the uncertainty of the reconstruction being a relevant metric for the information leak. In this paper, we propose of a novel framework generalizing these probabilistic reconstructions in the sense that it can handle other forms of interpretable models and more generic types of knowledge. In addition, we demonstrate that under realistic assumptions regarding the interpretable models' structure, the uncertainty of the reconstruction can be computed efficiently. Finally, we illustrate the applicability of our approach on both decision trees and rule lists, by comparing the theoretical information leak associated to either exact or heuristic learning algorithms. Our results suggest that optimal interpretable models are often more compact and leak less information regarding their training data than greedily-built ones, for a given accuracy level.
Learning Optimal Fair Scoring Systems for Multi-Class Classification
Apr 11, 2023

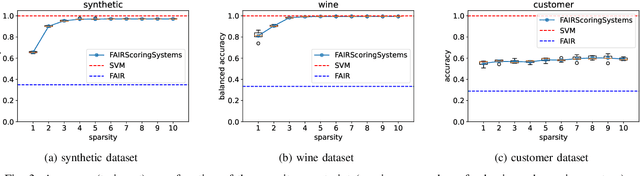

Machine Learning models are increasingly used for decision making, in particular in high-stakes applications such as credit scoring, medicine or recidivism prediction. However, there are growing concerns about these models with respect to their lack of interpretability and the undesirable biases they can generate or reproduce. While the concepts of interpretability and fairness have been extensively studied by the scientific community in recent years, few works have tackled the general multi-class classification problem under fairness constraints, and none of them proposes to generate fair and interpretable models for multi-class classification. In this paper, we use Mixed-Integer Linear Programming (MILP) techniques to produce inherently interpretable scoring systems under sparsity and fairness constraints, for the general multi-class classification setup. Our work generalizes the SLIM (Supersparse Linear Integer Models) framework that was proposed by Rudin and Ustun to learn optimal scoring systems for binary classification. The use of MILP techniques allows for an easy integration of diverse operational constraints (such as, but not restricted to, fairness or sparsity), but also for the building of certifiably optimal models (or sub-optimal models with bounded optimality gap).
Learning Hybrid Interpretable Models: Theory, Taxonomy, and Methods
Mar 08, 2023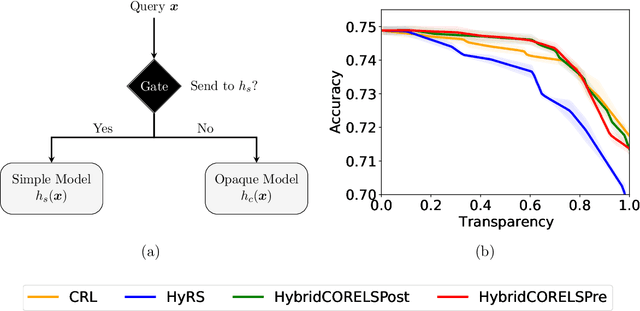
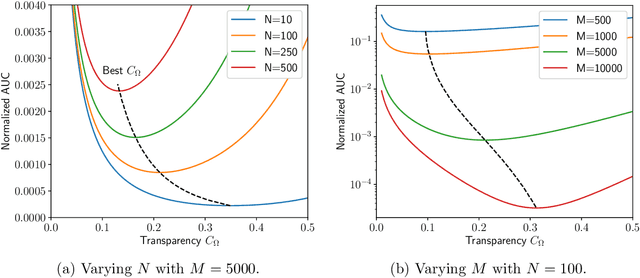
A hybrid model involves the cooperation of an interpretable model and a complex black box. At inference, any input of the hybrid model is assigned to either its interpretable or complex component based on a gating mechanism. The advantages of such models over classical ones are two-fold: 1) They grant users precise control over the level of transparency of the system and 2) They can potentially perform better than a standalone black box since redirecting some of the inputs to an interpretable model implicitly acts as regularization. Still, despite their high potential, hybrid models remain under-studied in the interpretability/explainability literature. In this paper, we remedy this fact by presenting a thorough investigation of such models from three perspectives: Theory, Taxonomy, and Methods. First, we explore the theory behind the generalization of hybrid models from the Probably-Approximately-Correct (PAC) perspective. A consequence of our PAC guarantee is the existence of a sweet spot for the optimal transparency of the system. When such a sweet spot is attained, a hybrid model can potentially perform better than a standalone black box. Secondly, we provide a general taxonomy for the different ways of training hybrid models: the Post-Black-Box and Pre-Black-Box paradigms. These approaches differ in the order in which the interpretable and complex components are trained. We show where the state-of-the-art hybrid models Hybrid-Rule-Set and Companion-Rule-List fall in this taxonomy. Thirdly, we implement the two paradigms in a single method: HybridCORELS, which extends the CORELS algorithm to hybrid modeling. By leveraging CORELS, HybridCORELS provides a certificate of optimality of its interpretable component and precise control over transparency. We finally show empirically that HybridCORELS is competitive with existing hybrid models, and performs just as well as a standalone black box (or even better) while being partly transparent.
Exploiting Fairness to Enhance Sensitive Attributes Reconstruction
Sep 02, 2022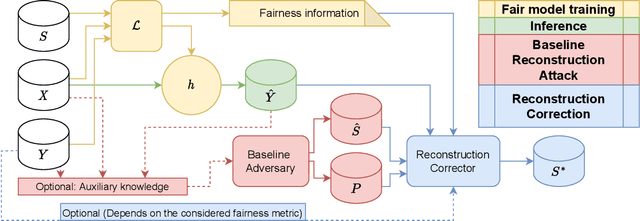
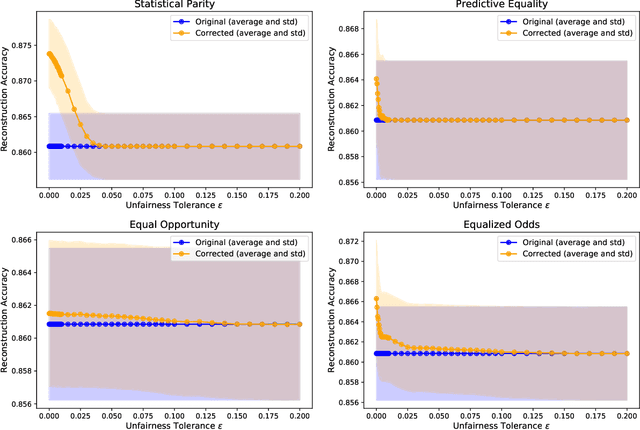
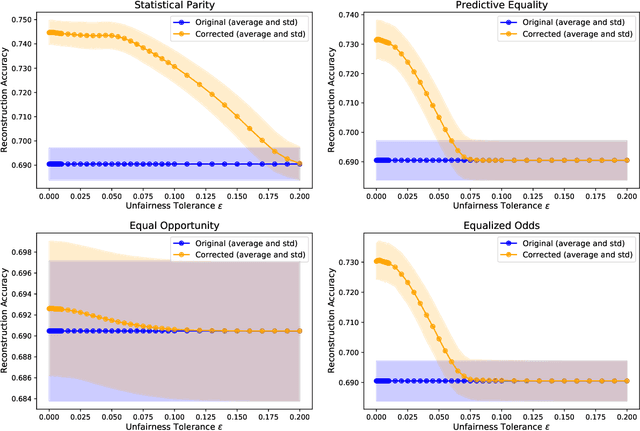
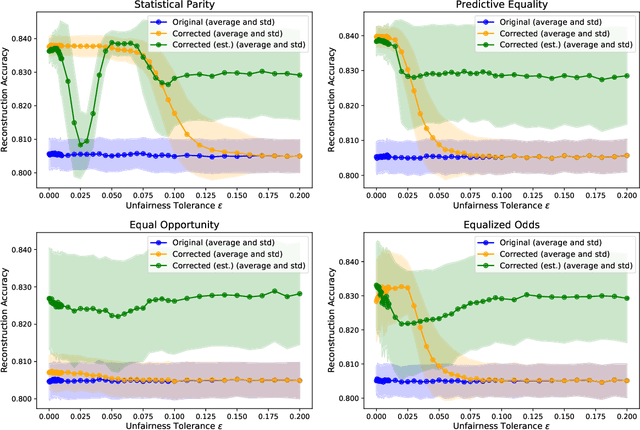
In recent years, a growing body of work has emerged on how to learn machine learning models under fairness constraints, often expressed with respect to some sensitive attributes. In this work, we consider the setting in which an adversary has black-box access to a target model and show that information about this model's fairness can be exploited by the adversary to enhance his reconstruction of the sensitive attributes of the training data. More precisely, we propose a generic reconstruction correction method, which takes as input an initial guess made by the adversary and corrects it to comply with some user-defined constraints (such as the fairness information) while minimizing the changes in the adversary's guess. The proposed method is agnostic to the type of target model, the fairness-aware learning method as well as the auxiliary knowledge of the adversary. To assess the applicability of our approach, we have conducted a thorough experimental evaluation on two state-of-the-art fair learning methods, using four different fairness metrics with a wide range of tolerances and with three datasets of diverse sizes and sensitive attributes. The experimental results demonstrate the effectiveness of the proposed approach to improve the reconstruction of the sensitive attributes of the training set.