 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRANITE: A Generalized Regional Framework for Identifying Agreement in Feature-Based Explanations
Jan 30, 2026Feature-based explanation methods aim to quantify how features influence the model's behavior, either locally or globally, but different methods often disagree, producing conflicting explanations. This disagreement arises primarily from two sources: how feature interactions are handled and how feature dependencies are incorporated. We propose GRANITE, a generalized regional explanation framework that partitions the feature space into regions where interaction and distribution influences are minimized. This approach aligns different explanation methods, yielding more consistent and interpretable explanations. GRANITE unifies existing regional approaches, extends them to feature groups, and introduces a recursive partitioning algorithm to estimate such regions. We demonstrate its effectiveness on real-world datasets, providing a practical tool for consistent and interpretable feature explanations.
Fairness and Sparsity within Rashomon sets: Enumeration-Free Exploration and Characterization
Feb 07, 2025



We introduce an enumeration-free method based on mathematical programming to precisely characterize various properties such as fairness or sparsity within the set of "good models", known as Rashomon set. This approach is generically applicable to any hypothesis class, provided that a mathematical formulation of the model learning task exists. It offers a structured framework to define the notion of business necessity and evaluate how fairness can be improved or degraded towards a specific protected group, while remaining within the Rashomon set and maintaining any desired sparsity level. We apply our approach to two hypothesis classes: scoring systems and decision diagrams, leveraging recent mathematical programming formulations for training such models. As seen in our experiments, the method comprehensively and certifiably quantifies trade-offs between predictive performance, sparsity, and fairness. We observe that a wide range of fairness values are attainable, ranging from highly favorable to significantly unfavorable for a protected group, while staying within less than 1% of the best possible training accuracy for the hypothesis class. Additionally, we observe that sparsity constraints limit these trade-offs and may disproportionately harm specific subgroups. As we evidenced, thoroughly characterizing the tensions between these key aspects is critical for an informed and accountable selection of models.
Mining Action Rules for Defect Reduction Planning
May 22, 2024



Defect reduction planning plays a vital role in enhancing software quality and minimizing software maintenance costs. By training a black box machine learning model and "explaining" its predictions, explainable AI for software engineering aims to identify the code characteristics that impact maintenance risks. However, post-hoc explanations do not always faithfully reflect what the original model computes. In this paper, we introduce CounterACT, a Counterfactual ACTion rule mining approach that can generate defect reduction plans without black-box models. By leveraging action rules, CounterACT provides a course of action that can be considered as a counterfactual explanation for the class (e.g., buggy or not buggy) assigned to a piece of code. We compare the effectiveness of CounterACT with the original action rule mining algorithm and six established defect reduction approaches on 9 software projects. Our evaluation is based on (a) overlap scores between proposed code changes and actual developer modifications; (b) improvement scores in future releases; and (c) the precision, recall, and F1-score of the plans. Our results show that, compared to competing approaches, CounterACT's explainable plans achieve higher overlap scores at the release level (median 95%) and commit level (median 85.97%), and they offer better trade-off between precision and recall (median F1-score 88.12%). Finally, we venture beyond planning and explore leveraging Large Language models (LLM) for generating code edits from our generated plans. Our results show that suggested LLM code edits supported by our plans are actionable and are more likely to pass relevant test cases than vanilla LLM code recommendations.
Detection and Evaluation of bias-inducing Features in Machine learning
Oct 19, 2023
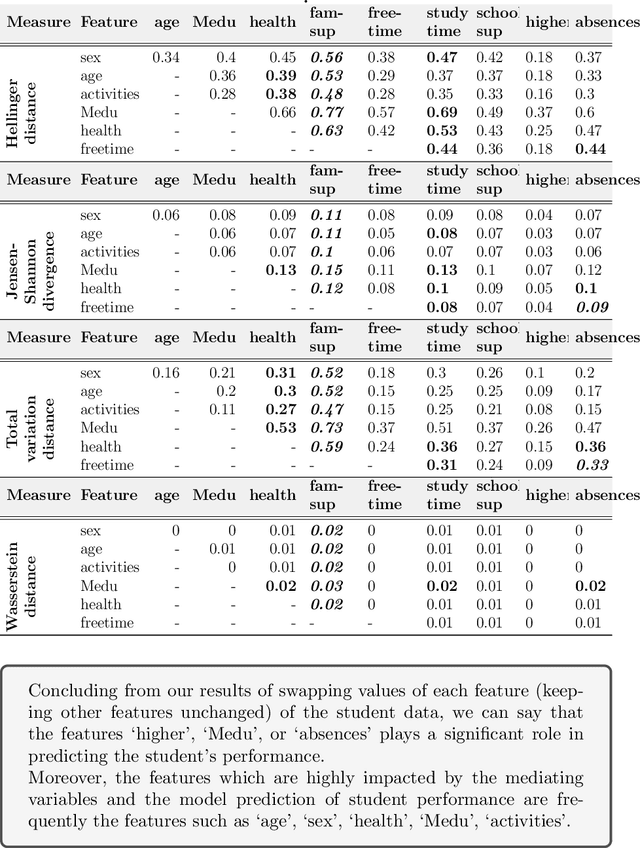
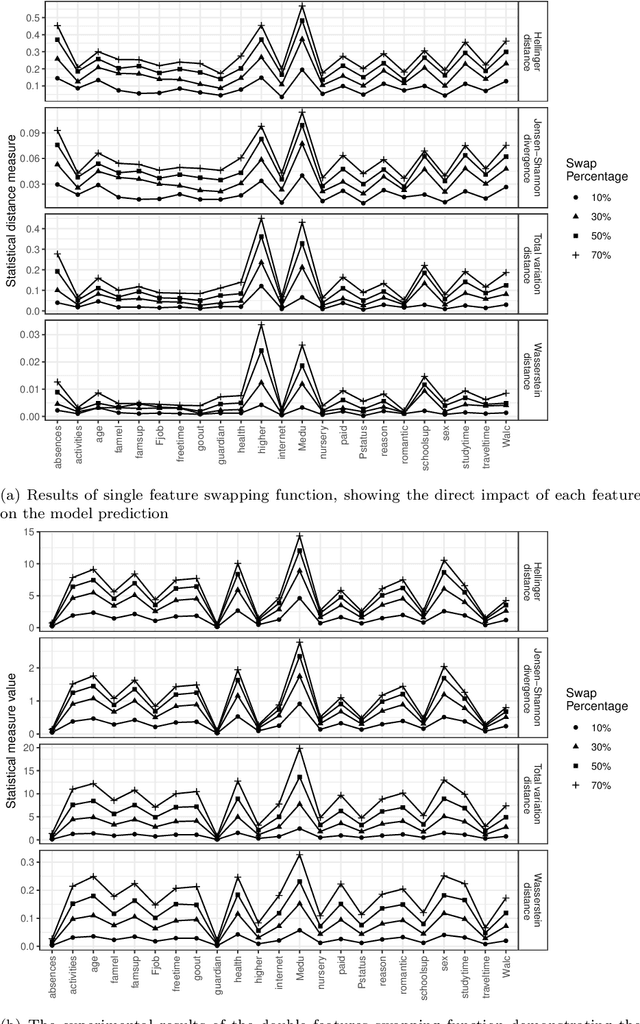
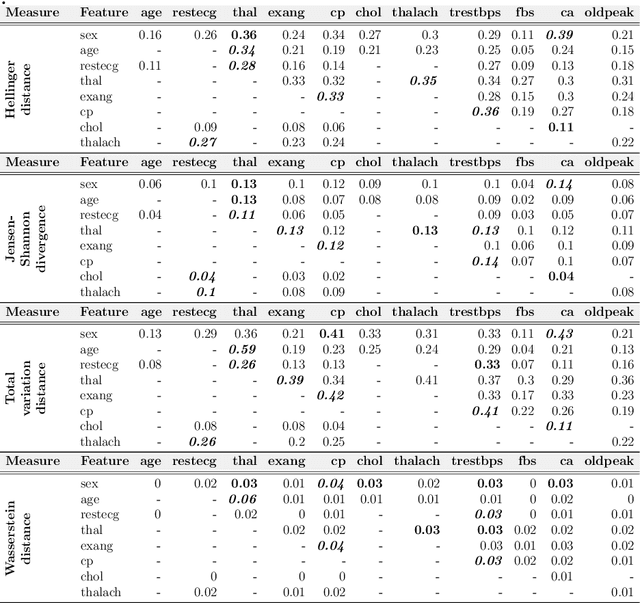
The cause-to-effect analysis can help us decompose all the likely causes of a problem, such as an undesirable business situation or unintended harm to the individual(s). This implies that we can identify how the problems are inherited, rank the causes to help prioritize fixes, simplify a complex problem and visualize them. In the context of machine learning (ML), one can use cause-to-effect analysis to understand the reason for the biased behavior of the system. For example, we can examine the root causes of biases by checking each feature for a potential cause of bias in the model. To approach this, one can apply small changes to a given feature or a pair of features in the data, following some guidelines and observing how it impacts the decision made by the model (i.e., model prediction). Therefore, we can use cause-to-effect analysis to identify the potential bias-inducing features, even when these features are originally are unknown. This is important since most current methods require a pre-identification of sensitive features for bias assessment and can actually miss other relevant bias-inducing features, which is why systematic identification of such features is necessary. Moreover, it often occurs that to achieve an equitable outcome, one has to take into account sensitive features in the model decision. Therefore, it should be up to the domain experts to decide based on their knowledge of the context of a decision whether bias induced by specific features is acceptable or not. In this study, we propose an approach for systematically identifying all bias-inducing features of a model to help support the decision-making of domain experts. We evaluated our technique using four well-known datasets to showcase how our contribution can help spearhead the standard procedure when developing, testing, maintaining, and deploying fair/equitable machine learning systems.
Learning Hybrid Interpretable Models: Theory, Taxonomy, and Methods
Mar 08, 2023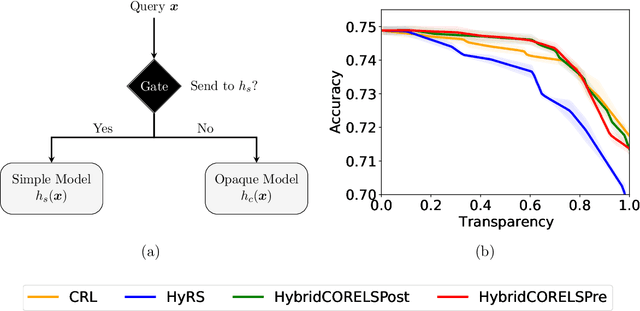
A hybrid model involves the cooperation of an interpretable model and a complex black box. At inference, any input of the hybrid model is assigned to either its interpretable or complex component based on a gating mechanism. The advantages of such models over classical ones are two-fold: 1) They grant users precise control over the level of transparency of the system and 2) They can potentially perform better than a standalone black box since redirecting some of the inputs to an interpretable model implicitly acts as regularization. Still, despite their high potential, hybrid models remain under-studied in the interpretability/explainability literature. In this paper, we remedy this fact by presenting a thorough investigation of such models from three perspectives: Theory, Taxonomy, and Methods. First, we explore the theory behind the generalization of hybrid models from the Probably-Approximately-Correct (PAC) perspective. A consequence of our PAC guarantee is the existence of a sweet spot for the optimal transparency of the system. When such a sweet spot is attained, a hybrid model can potentially perform better than a standalone black box. Secondly, we provide a general taxonomy for the different ways of training hybrid models: the Post-Black-Box and Pre-Black-Box paradigms. These approaches differ in the order in which the interpretable and complex components are trained. We show where the state-of-the-art hybrid models Hybrid-Rule-Set and Companion-Rule-List fall in this taxonomy. Thirdly, we implement the two paradigms in a single method: HybridCORELS, which extends the CORELS algorithm to hybrid modeling. By leveraging CORELS, HybridCORELS provides a certificate of optimality of its interpretable component and precise control over transparency. We finally show empirically that HybridCORELS is competitive with existing hybrid models, and performs just as well as a standalone black box (or even better) while being partly transparent.
Understanding Interventional TreeSHAP : How and Why it Works
Sep 29, 2022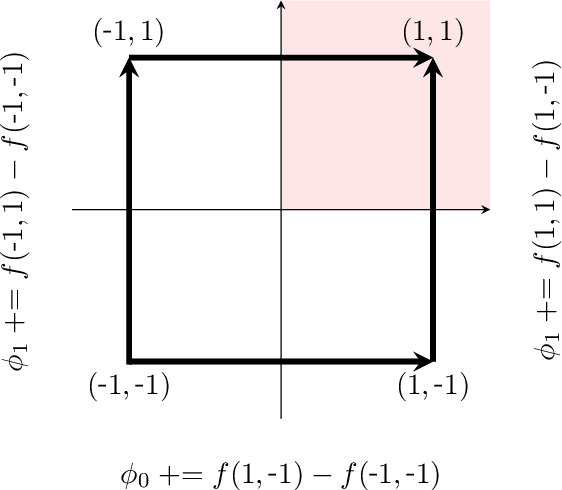
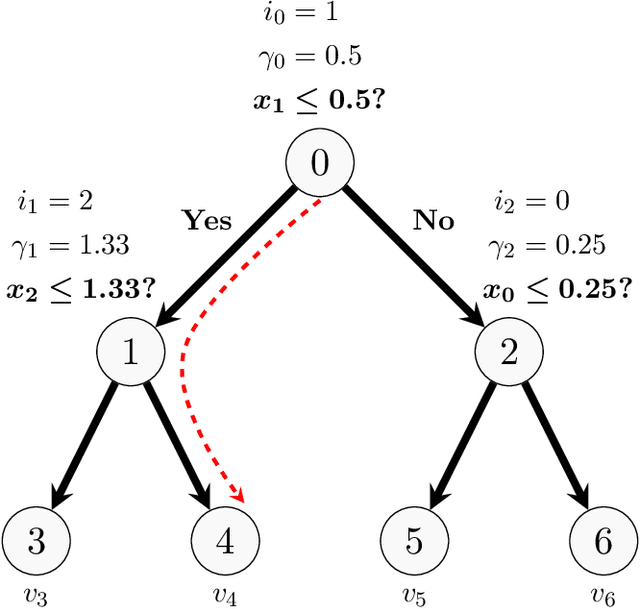

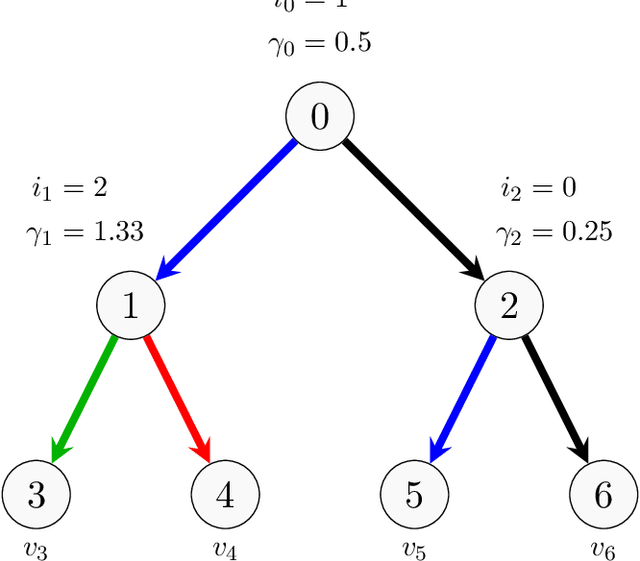
Shapley values are ubiquitous in interpretable Machine Learning due to their strong theoretical background and efficient implementation in the SHAP library. Computing these values used to induce an exponential cost with respect to the number of input features of an opaque model. Now, with efficient implementations such as Interventional TreeSHAP, this exponential burden is alleviated assuming one is explaining ensembles of decision trees. Although Interventional TreeSHAP has risen in popularity, it still lacks a formal proof of how/why it works. We provide such proof with the aim of not only increasing the transparency of the algorithm but also to encourage further development of these ideas. Notably, our proof for Interventional TreeSHAP is easily adapted to Shapley-Taylor indices.
Fooling SHAP with Stealthily Biased Sampling
May 30, 2022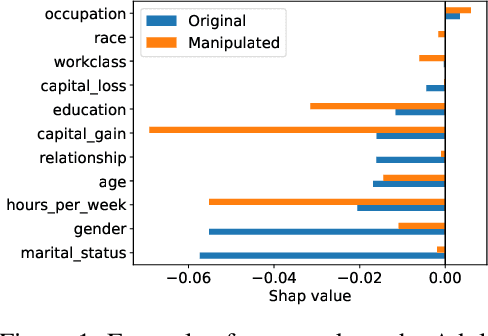
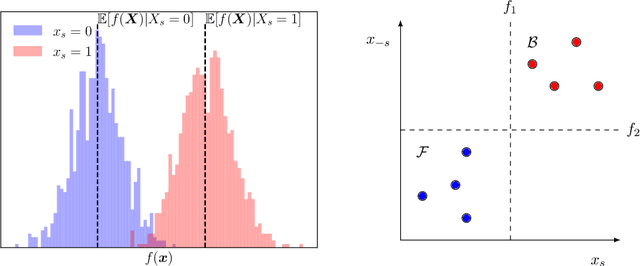

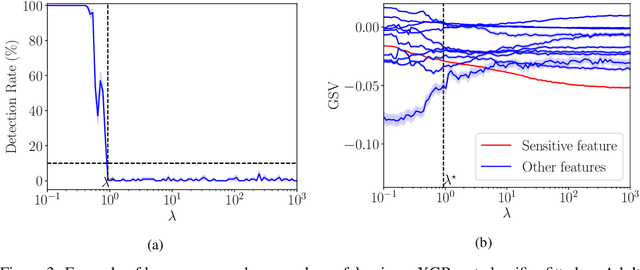
SHAP explanations aim at identifying which features contribute the most to the difference in model prediction at a specific input versus a background distribution. Recent studies have shown that they can be manipulated by malicious adversaries to produce arbitrary desired explanations. However, existing attacks focus solely on altering the black-box model itself. In this paper, we propose a complementary family of attacks that leave the model intact and manipulate SHAP explanations using stealthily biased sampling of the data points used to approximate expectations w.r.t the background distribution. In the context of fairness audit, we show that our attack can reduce the importance of a sensitive feature when explaining the difference in outcomes between groups, while remaining undetected. These results highlight the manipulability of SHAP explanations and encourage auditors to treat post-hoc explanations with skepticism.
Partial order: Finding Consensus among Uncertain Feature Attributions
Oct 26, 2021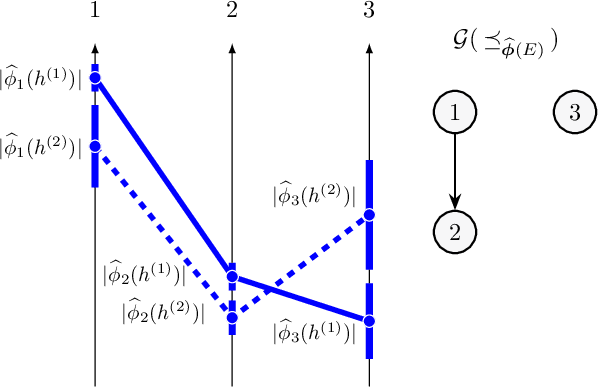


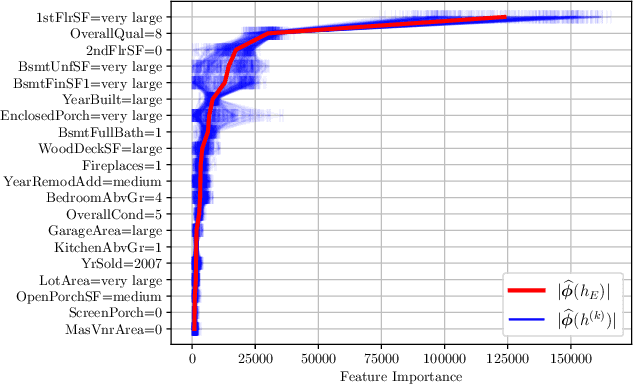
Post-hoc feature importance is progressively being employed to explain decisions of complex machine learning models. Yet in practice, reruns of the training algorithm and/or the explainer can result in contradicting statements of feature importance, henceforth reducing trust in those techniques. A possible avenue to address this issue is to develop strategies to aggregate diverse explanations about feature importance. While the arithmetic mean, which yields a total order, has been advanced, we introduce an alternative: the consensus among multiple models, which results in partial orders. The two aggregation strategies are compared using Integrated Gradients and Shapley values on two regression datasets, and we show that a large portion of the information provided by the mean aggregation is not supported by the consensus of each individual model, raising suspicion on the trustworthiness of this practice.
How to Certify Machine Learning Based Safety-critical Systems? A Systematic Literature Review
Aug 03, 2021
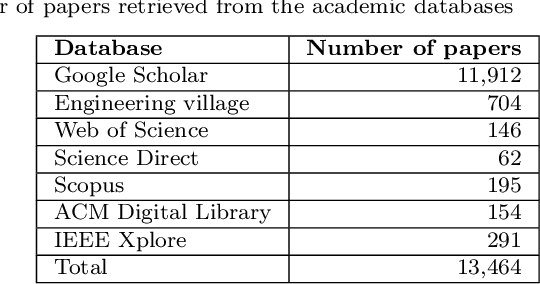

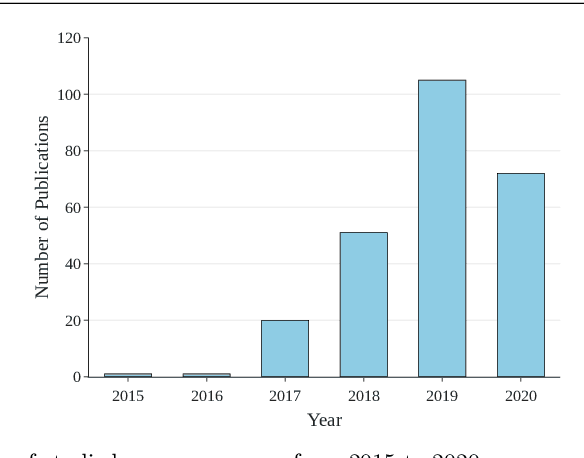
Context: Machine Learning (ML) has been at the heart of many innovations over the past years. However, including it in so-called 'safety-critical' systems such as automotive or aeronautic has proven to be very challenging, since the shift in paradigm that ML brings completely changes traditional certification approaches. Objective: This paper aims to elucidate challenges related to the certification of ML-based safety-critical systems, as well as the solutions that are proposed in the literature to tackle them, answering the question 'How to Certify Machine Learning Based Safety-critical Systems?'. Method: We conduct a Systematic Literature Review (SLR) of research papers published between 2015 to 2020, covering topics related to the certification of ML systems. In total, we identified 217 papers covering topics considered to be the main pillars of ML certification: Robustness, Uncertainty, Explainability, Verification, Safe Reinforcement Learning, and Direct Certification. We analyzed the main trends and problems of each sub-field and provided summaries of the papers extracted. Results: The SLR results highlighted the enthusiasm of the community for this subject, as well as the lack of diversity in terms of datasets and type of models. It also emphasized the need to further develop connections between academia and industries to deepen the domain study. Finally, it also illustrated the necessity to build connections between the above mention main pillars that are for now mainly studied separately. Conclusion: We highlighted current efforts deployed to enable the certification of ML based software systems, and discuss some future research directions.