 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparison of Reinforcement Learning Frameworks for Software Testing Tasks
Aug 30, 2022
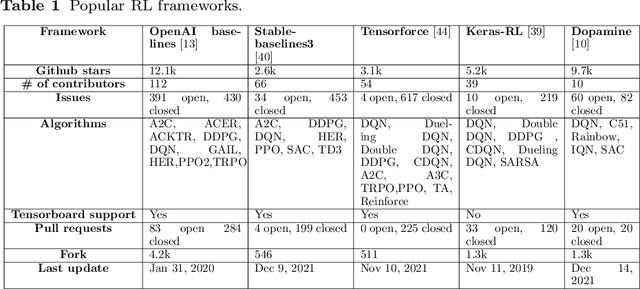
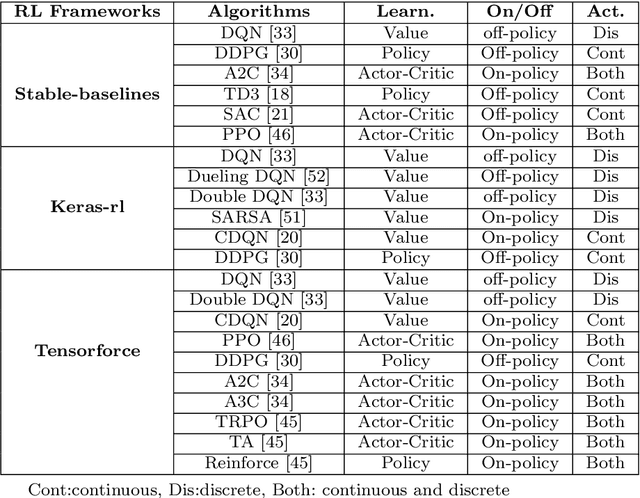
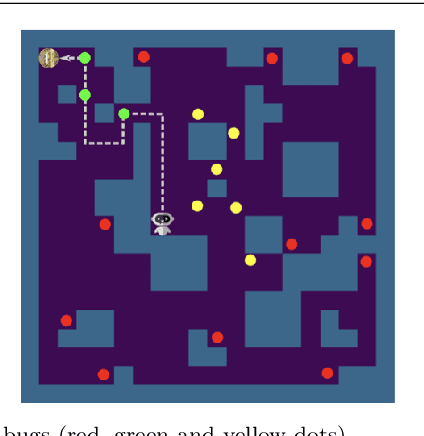
Software testing activities aim to find the possible defects of a software product and ensure that the product meets its expected requirements. Some software testing approached are lacking automation or are partly automated which increases the testing time and overall software testing costs. Recently, Reinforcement Learning (RL) has been successfully employed in complex testing tasks such as game testing, regression testing, and test case prioritization to automate the process and provide continuous adaptation. Practitioners can employ RL by implementing from scratch an RL algorithm or use an RL framework. Developers have widely used these frameworks to solve problems in various domains including software testing. However, to the best of our knowledge, there is no study that empirically evaluates the effectiveness and performance of pre-implemented algorithms in RL frameworks. In this paper, we empirically investigate the applications of carefully selected RL algorithms on two important software testing tasks: test case prioritization in the context of Continuous Integration (CI) and game testing. For the game testing task, we conduct experiments on a simple game and use RL algorithms to explore the game to detect bugs. Results show that some of the selected RL frameworks such as Tensorforce outperform recent approaches in the literature. To prioritize test cases, we run experiments on a CI environment where RL algorithms from different frameworks are used to rank the test cases. Our results show that the performance difference between pre-implemented algorithms in some cases is considerable, motivating further investigation. Moreover, empirical evaluations on some benchmark problems are recommended for researchers looking to select RL frameworks, to make sure that RL algorithms perform as intended.
On Assessing The Safety of Reinforcement Learning algorithms Using Formal Methods
Nov 10, 2021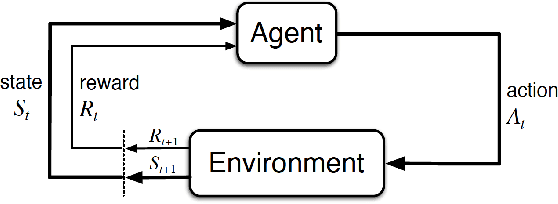



The increasing adoption of Reinforcement Learning in safety-critical systems domains such as autonomous vehicles, health, and aviation raises the need for ensuring their safety. Existing safety mechanisms such as adversarial training, adversarial detection, and robust learning are not always adapted to all disturbances in which the agent is deployed. Those disturbances include moving adversaries whose behavior can be unpredictable by the agent, and as a matter of fact harmful to its learning. Ensuring the safety of critical systems also requires methods that give formal guarantees on the behaviour of the agent evolving in a perturbed environment. It is therefore necessary to propose new solutions adapted to the learning challenges faced by the agent. In this paper, first we generate adversarial agents that exhibit flaws in the agent's policy by presenting moving adversaries. Secondly, We use reward shaping and a modified Q-learning algorithm as defense mechanisms to improve the agent's policy when facing adversarial perturbations. Finally, probabilistic model checking is employed to evaluate the effectiveness of both mechanisms. We have conducted experiments on a discrete grid world with a single agent facing non-learning and learning adversaries. Our results show a diminution in the number of collisions between the agent and the adversaries. Probabilistic model checking provides lower and upper probabilistic bounds regarding the agent's safety in the adversarial environment.
How to Certify Machine Learning Based Safety-critical Systems? A Systematic Literature Review
Aug 03, 2021
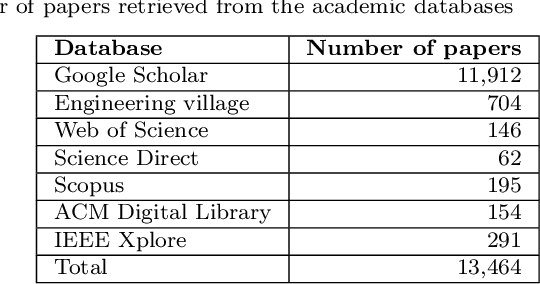

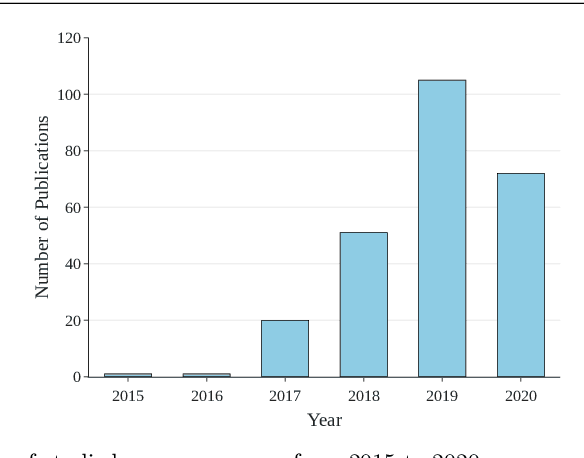
Context: Machine Learning (ML) has been at the heart of many innovations over the past years. However, including it in so-called 'safety-critical' systems such as automotive or aeronautic has proven to be very challenging, since the shift in paradigm that ML brings completely changes traditional certification approaches. Objective: This paper aims to elucidate challenges related to the certification of ML-based safety-critical systems, as well as the solutions that are proposed in the literature to tackle them, answering the question 'How to Certify Machine Learning Based Safety-critical Systems?'. Method: We conduct a Systematic Literature Review (SLR) of research papers published between 2015 to 2020, covering topics related to the certification of ML systems. In total, we identified 217 papers covering topics considered to be the main pillars of ML certification: Robustness, Uncertainty, Explainability, Verification, Safe Reinforcement Learning, and Direct Certification. We analyzed the main trends and problems of each sub-field and provided summaries of the papers extracted. Results: The SLR results highlighted the enthusiasm of the community for this subject, as well as the lack of diversity in terms of datasets and type of models. It also emphasized the need to further develop connections between academia and industries to deepen the domain study. Finally, it also illustrated the necessity to build connections between the above mention main pillars that are for now mainly studied separately. Conclusion: We highlighted current efforts deployed to enable the certification of ML based software systems, and discuss some future research directions.