 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection and Evaluation of bias-inducing Features in Machine learning
Paper and Code
Oct 19, 2023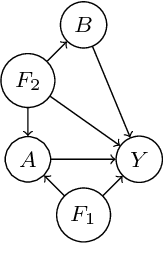
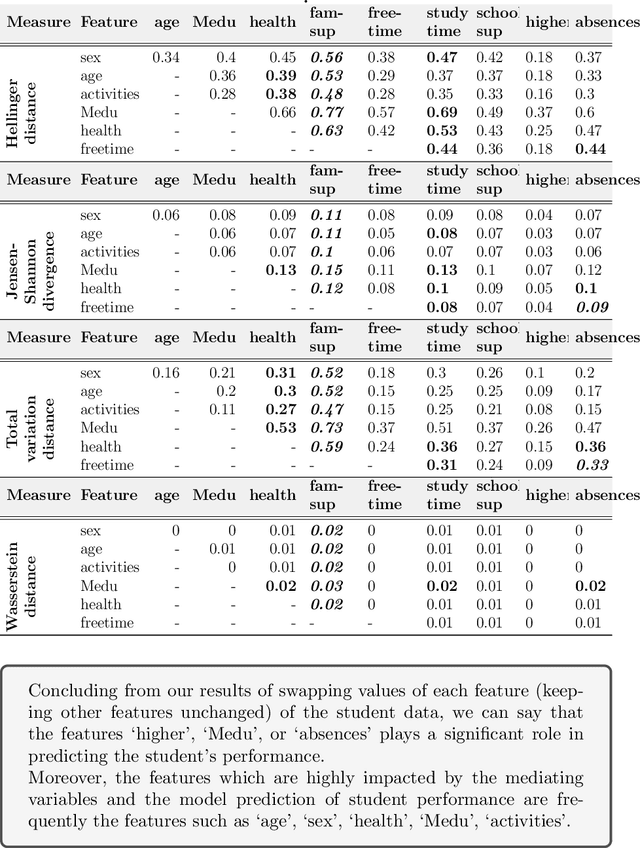
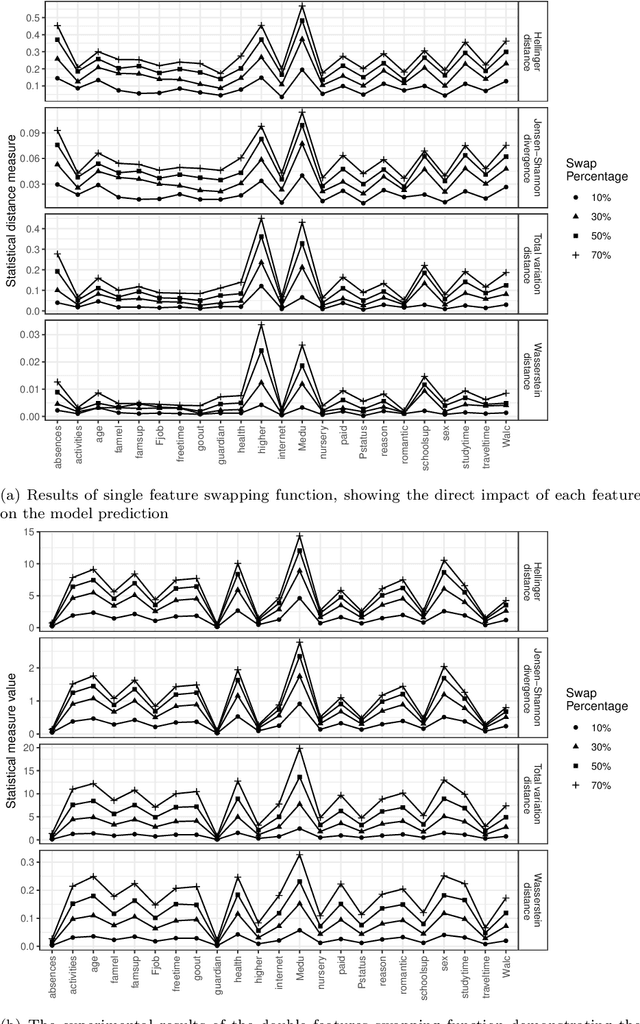
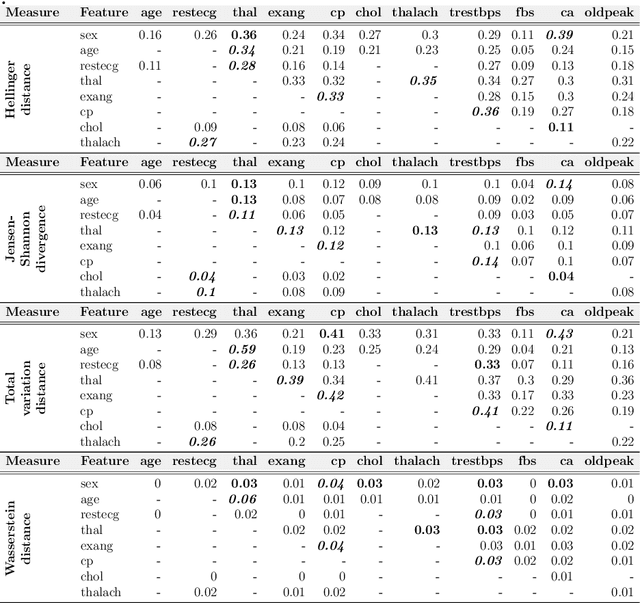
The cause-to-effect analysis can help us decompose all the likely causes of a problem, such as an undesirable business situation or unintended harm to the individual(s). This implies that we can identify how the problems are inherited, rank the causes to help prioritize fixes, simplify a complex problem and visualize them. In the context of machine learning (ML), one can use cause-to-effect analysis to understand the reason for the biased behavior of the system. For example, we can examine the root causes of biases by checking each feature for a potential cause of bias in the model. To approach this, one can apply small changes to a given feature or a pair of features in the data, following some guidelines and observing how it impacts the decision made by the model (i.e., model prediction). Therefore, we can use cause-to-effect analysis to identify the potential bias-inducing features, even when these features are originally are unknown. This is important since most current methods require a pre-identification of sensitive features for bias assessment and can actually miss other relevant bias-inducing features, which is why systematic identification of such features is necessary. Moreover, it often occurs that to achieve an equitable outcome, one has to take into account sensitive features in the model decision. Therefore, it should be up to the domain experts to decide based on their knowledge of the context of a decision whether bias induced by specific features is acceptable or not. In this study, we propose an approach for systematically identifying all bias-inducing features of a model to help support the decision-making of domain experts. We evaluated our technique using four well-known datasets to showcase how our contribution can help spearhead the standard procedure when developing, testing, maintaining, and deploying fair/equitable machine learning systems.