 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollision Resolution in RFID Systems Using Antenna Arrays and Mix Source Separation
Nov 19, 2025In this letter, we propose an efficient mix source separation algorithm for collision resolution in radio frequency identification (RFID) systems equipped with an antenna array at the reader. We first introduce an approach that exploits the zero constant modulus (ZCM) criterion to separate colliding tags through gradient descent, without using pilot symbols. We show that the ZCM characteristic, considered alone, in the design of the objective function can lead to significant ambiguities in the determination of the beamformers used in the recovery of tag messages. To address this limitation, we propose a more sophisticated approach, relying on a hybrid objective function, incorporating a new ambiguity-raising criterion in addition to the ZCM criterion.
* 4 pages, 3 figures
Uncoordinated Cooperative OFDM Multi-Hop UAV Relay Networks Using Virtual Channels Based on All-Pass Filters
Nov 19, 2025In this paper, we propose an efficient transmission scheme for autonomous cooperative Orthogonal Frequency Division Multiplexing (OFDM) based multi-hop Unmanned Aerial Vehicle (UAV) relay networks. These systems often suffer from destructive interference at the destination node due to uncoordinated transmissions of common packets by cooperating UAVs. To address this issue, we introduce the concept of virtual transmit channels at each UAV, implemented using truncated all-pass filters (APFs). This approach ensures that all subcarriers benefit from comparable transmit powers, guaranteeing excellent performance when a single UAV is transmitting. In scenarios where multiple UAVs cooperate without coordination, the inherent randomness of the generated virtual channels facilitates cooperative diversity, effectively mitigating destructive interference. We further integrate this method with the distributed randomized space-time block coding (STBC) scheme to enhance transmission reliability. Additionally, we propose efficient algorithms for estimating the composite channels that combine both the true propagation channels and the virtual channels. Simulation results demonstrate that our proposed scheme significantly outperforms the classical phase dithering scheme across various scenarios.
* 14 pages, 5 figures
Randomized Power Transmission with Optimized Level Selection Probabilities in Uncoordinated Uplink NOMA
Nov 19, 2025We consider uncoordinated random uplink non-orthogonal multiple access (NOMA) systems using a set of predetermined power levels. We propose to optimize the probabilities of selection of power levels in order to minimize performance metrics as block error probability (BLEP) or bit error probability (BEP). When the multiuser detection algorithm at the BS treats at most two colliding users' packets, our optimization problem is a quadratic programming problem. For more colliding users' packets, we solve the problem iteratively. Our solution is original because it applies to any multiuser detection algorithm and any set of power levels.
* 5 pages, 7 figures
Nyquist Signaling Modulation (NSM): An FTN-Inspired Paradigm Shift in Modulation Design for 6G and Beyond
Nov 11, 2025
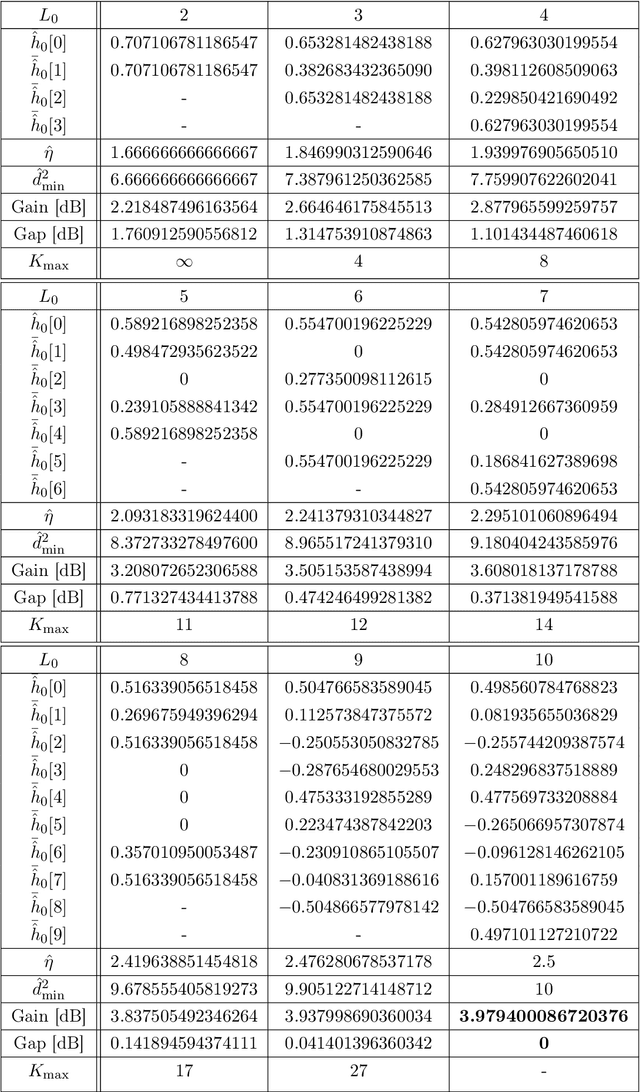
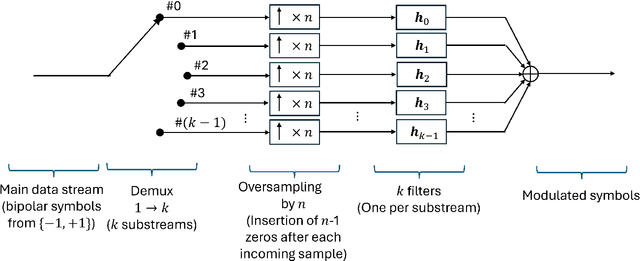

Nyquist Signaling Modulations (NSMs) are a new signaling paradigm inspired by faster-than-Nyquist principles but based on a distinct approach that enables controlled inter-symbol interference through carefully designed finite-impulse-response filters. NSMs can operate in any number of dimensions, including mixed-dimensional configurations, offering wide flexibility in filter design, optional energy balancing, and preservation of the 2-ASK minimum squared Euclidean distance (MSED). Both real and rational tapped filters are investigated, and closed-form expressions are derived for the optimal real-tap filters in the one-dimensional case (MS-PRS), providing analytical insight and strong agreement with simulated bit-error behavior across wide SNR ranges. The paradigm is conceptually expanded through an analog Low-Density Generator Matrix (LDGM) formulation, which broadens the NSM family and unifies modulation and coding within a single, structurally coherent framework. When combined with LDPC coding, it enables efficient and naturally synergistic interaction between the analog modulation and the digital LDPC code. Alternatively, when analog LDGM is employed for both source coding and modulation, a simple and harmonious joint source-channel-modulation structure emerges. In both configurations, the constituent blocks exhibit dual graph-based architectures suited to message passing, achieving high flexibility and complexity-efficient operation. Collectively, these results establish promising physical-layer directions for future 6G communication systems.
On Trustworthy Rule-Based Models and Explanations
Jul 10, 2025A task of interest in machine learning (ML) is that of ascribing explanations to the predictions made by ML models. Furthermore, in domains deemed high risk, the rigor of explanations is paramount. Indeed, incorrect explanations can and will mislead human decision makers. As a result, and even if interpretability is acknowledged as an elusive concept, so-called interpretable models are employed ubiquitously in high-risk uses of ML and data mining (DM). This is the case for rule-based ML models, which encompass decision trees, diagrams, sets and lists. This paper relates explanations with well-known undesired facets of rule-based ML models, which include negative overlap and several forms of redundancy. The paper develops algorithms for the analysis of these undesired facets of rule-based systems, and concludes that well-known and widely used tools for learning rule-based ML models will induce rule sets that exhibit one or more negative facets.
Kalman Filtering for Precise Indoor Position and Orientation Estimation Using IMU and Acoustics on Riemannian Manifolds
Sep 02, 2024


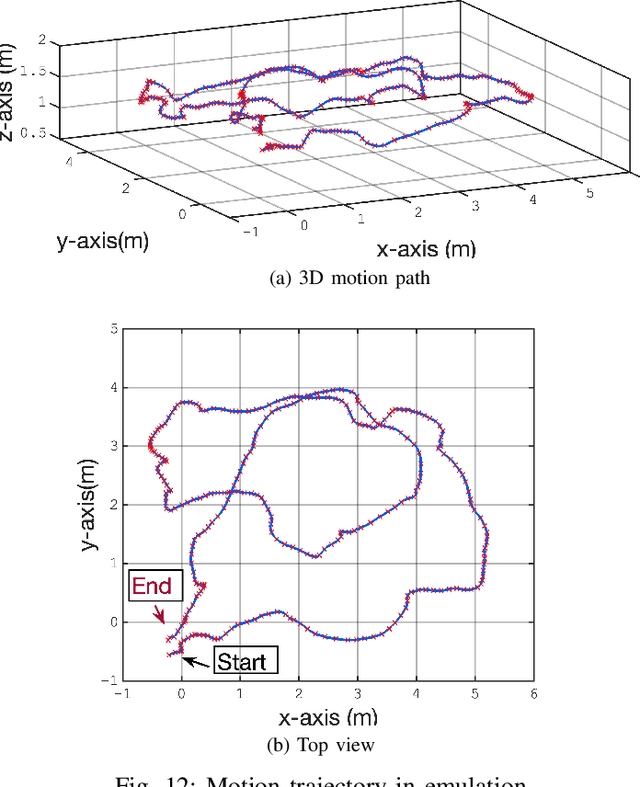
Indoor tracking and pose estimation, i.e., determining the position and orientation of a moving target, are increasingly important due to their numerous applications. While Inertial Navigation Systems (INS) provide high update rates, their positioning errors can accumulate rapidly over time. To mitigate this, it is common to integrate INS with complementary systems to correct drift and improve accuracy. This paper presents a novel approach that combines INS with an acoustic Riemannian-based localization system to enhance indoor positioning and orientation tracking. The proposed method employs both the Extended Kalman Filter (EKF) and the Unscented Kalman Filter (UKF) for fusing data from the two systems. The Riemannian-based localization system delivers high-accuracy estimates of the target's position and orientation, which are then used to correct the INS data. A new projection algorithm is introduced to map the EKF or UKF output onto the Riemannian manifold, further improving estimation accuracy. Our results show that the proposed methods significantly outperform benchmark algorithms in both position and orientation estimation. The effectiveness of the proposed methods was evaluated through extensive numerical simulations and testing using our in-house experimental setup. These evaluations confirm the superior performance of our approach in practical scenarios.
SoK: Taming the Triangle -- On the Interplays between Fairness, Interpretability and Privacy in Machine Learning
Dec 22, 2023

Machine learning techniques are increasingly used for high-stakes decision-making, such as college admissions, loan attribution or recidivism prediction. Thus, it is crucial to ensure that the models learnt can be audited or understood by human users, do not create or reproduce discrimination or bias, and do not leak sensitive information regarding their training data. Indeed, interpretability, fairness and privacy are key requirements for the development of responsible machine learning, and all three have been studied extensively during the last decade. However, they were mainly considered in isolation, while in practice they interplay with each other, either positively or negatively. In this Systematization of Knowledge (SoK) paper, we survey the literature on the interactions between these three desiderata. More precisely, for each pairwise interaction, we summarize the identified synergies and tensions. These findings highlight several fundamental theoretical and empirical conflicts, while also demonstrating that jointly considering these different requirements is challenging when one aims at preserving a high level of utility. To solve this issue, we also discuss possible conciliation mechanisms, showing that a careful design can enable to successfully handle these different concerns in practice.
Probabilistic Dataset Reconstruction from Interpretable Models
Aug 29, 2023
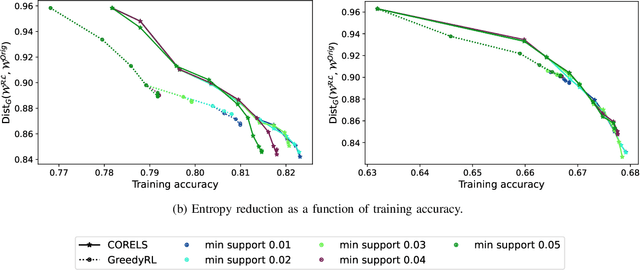
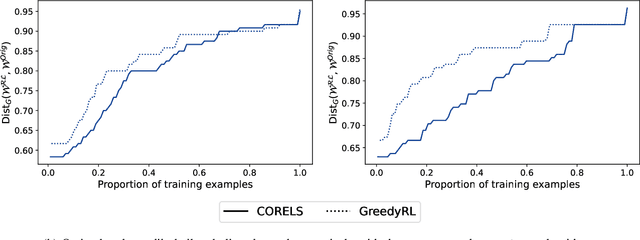
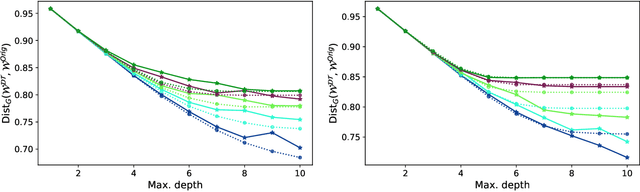
Interpretability is often pointed out as a key requirement for trustworthy machine learning. However, learning and releasing models that are inherently interpretable leaks information regarding the underlying training data. As such disclosure may directly conflict with privacy, a precise quantification of the privacy impact of such breach is a fundamental problem. For instance, previous work have shown that the structure of a decision tree can be leveraged to build a probabilistic reconstruction of its training dataset, with the uncertainty of the reconstruction being a relevant metric for the information leak. In this paper, we propose of a novel framework generalizing these probabilistic reconstructions in the sense that it can handle other forms of interpretable models and more generic types of knowledge. In addition, we demonstrate that under realistic assumptions regarding the interpretable models' structure, the uncertainty of the reconstruction can be computed efficiently. Finally, we illustrate the applicability of our approach on both decision trees and rule lists, by comparing the theoretical information leak associated to either exact or heuristic learning algorithms. Our results suggest that optimal interpretable models are often more compact and leak less information regarding their training data than greedily-built ones, for a given accuracy level.
Exploiting Fairness to Enhance Sensitive Attributes Reconstruction
Sep 02, 2022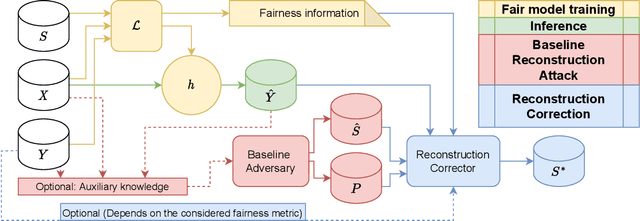
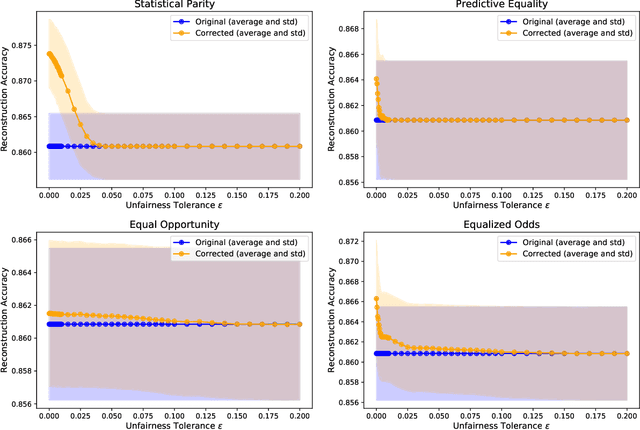
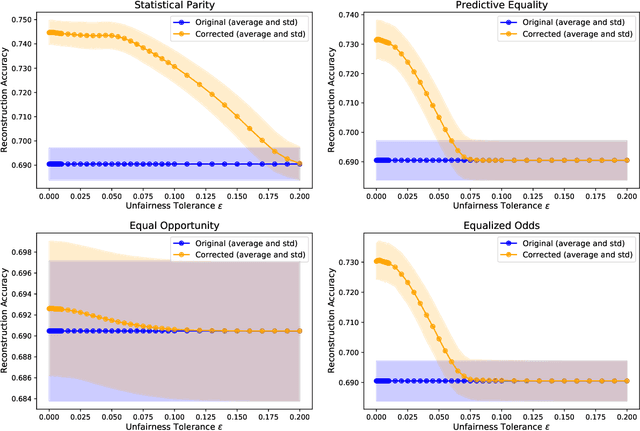
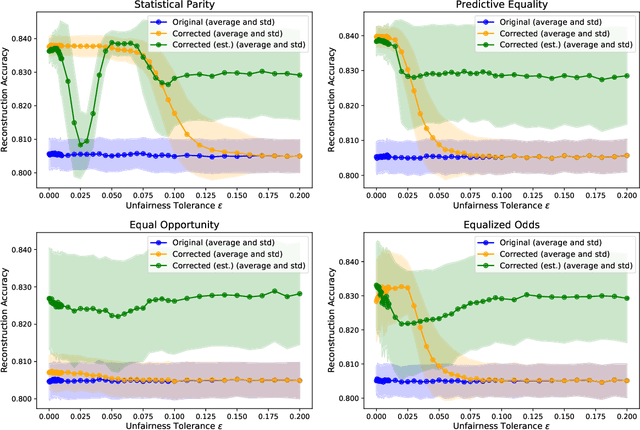
In recent years, a growing body of work has emerged on how to learn machine learning models under fairness constraints, often expressed with respect to some sensitive attributes. In this work, we consider the setting in which an adversary has black-box access to a target model and show that information about this model's fairness can be exploited by the adversary to enhance his reconstruction of the sensitive attributes of the training data. More precisely, we propose a generic reconstruction correction method, which takes as input an initial guess made by the adversary and corrects it to comply with some user-defined constraints (such as the fairness information) while minimizing the changes in the adversary's guess. The proposed method is agnostic to the type of target model, the fairness-aware learning method as well as the auxiliary knowledge of the adversary. To assess the applicability of our approach, we have conducted a thorough experimental evaluation on two state-of-the-art fair learning methods, using four different fairness metrics with a wide range of tolerances and with three datasets of diverse sizes and sensitive attributes. The experimental results demonstrate the effectiveness of the proposed approach to improve the reconstruction of the sensitive attributes of the training set.
Optimizing Binary Decision Diagrams with MaxSAT for classification
Mar 21, 2022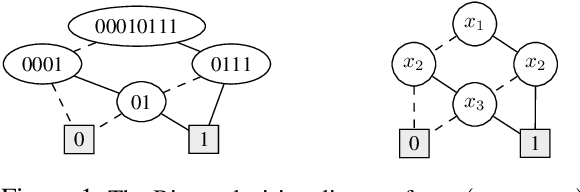
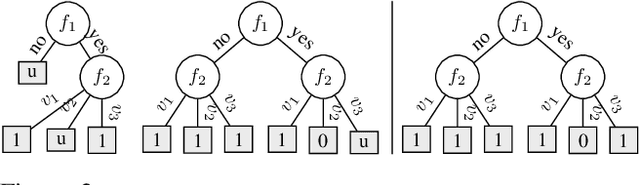

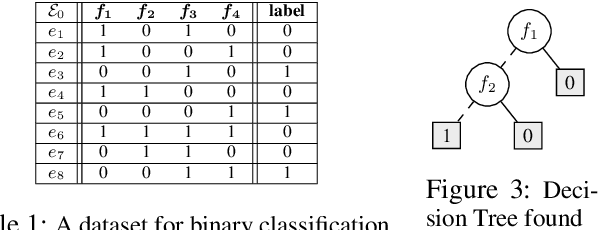
The growing interest in explainable artificial intelligence (XAI) for critical decision making motivates the need for interpretable machine learning (ML) models. In fact, due to their structure (especially with small sizes), these models are inherently understandable by humans. Recently, several exact methods for computing such models are proposed to overcome weaknesses of traditional heuristic methods by providing more compact models or better prediction quality. Despite their compressed representation of Boolean functions, Binary decision diagrams (BDDs) did not gain enough interest as other interpretable ML models. In this paper, we first propose SAT-based models for learning optimal BDDs (in terms of the number of features) that classify all input examples. Then, we lift the encoding to a MaxSAT model to learn optimal BDDs in limited depths, that maximize the number of examples correctly classified. Finally, we tackle the fragmentation problem by introducing a method to merge compatible subtrees for the BDDs found via the MaxSAT model. Our empirical study shows clear benefits of the proposed approach in terms of prediction quality and intrepretability (i.e., lighter size) compared to the state-of-the-art approaches.