 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey on AI Ethics: A Socio-technical Perspective
Nov 28, 2023
The past decade has observed a great advancement in AI with deep learning-based models being deployed in diverse scenarios including safety-critical applications. As these AI systems become deeply embedded in our societal infrastructure, the repercussions of their decisions and actions have significant consequences, making the ethical implications of AI deployment highly relevant and important. The ethical concerns associated with AI are multifaceted, including challenging issues of fairness, privacy and data protection, responsibility and accountability, safety and robustness, transparency and explainability, and environmental impact. These principles together form the foundations of ethical AI considerations that concern every stakeholder in the AI system lifecycle. In light of the present ethical and future x-risk concerns, governments have shown increasing interest in establishing guidelines for the ethical deployment of AI. This work unifies the current and future ethical concerns of deploying AI into society. While we acknowledge and appreciate the technical surveys for each of the ethical principles concerned, in this paper, we aim to provide a comprehensive overview that not only addresses each principle from a technical point of view but also discusses them from a social perspective.
Fairness Under Demographic Scarce Regime
Jul 24, 2023

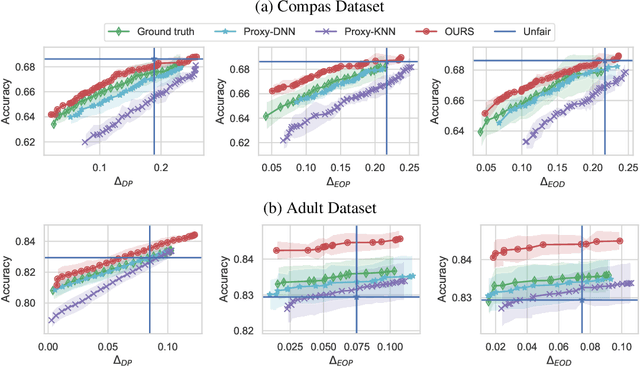

Most existing works on fairness assume the model has full access to demographic information. However, there exist scenarios where demographic information is partially available because a record was not maintained throughout data collection or due to privacy reasons. This setting is known as demographic scarce regime. Prior research have shown that training an attribute classifier to replace the missing sensitive attributes (proxy) can still improve fairness. However, the use of proxy-sensitive attributes worsens fairness-accuracy trade-offs compared to true sensitive attributes. To address this limitation, we propose a framework to build attribute classifiers that achieve better fairness-accuracy trade-offs. Our method introduces uncertainty awareness in the attribute classifier and enforces fairness on samples with demographic information inferred with the lowest uncertainty. We show empirically that enforcing fairness constraints on samples with uncertain sensitive attributes is detrimental to fairness and accuracy. Our experiments on two datasets showed that the proposed framework yields models with significantly better fairness-accuracy trade-offs compared to classic attribute classifiers. Surprisingly, our framework outperforms models trained with constraints on the true sensitive attributes.
RepFair-GAN: Mitigating Representation Bias in GANs Using Gradient Clipping
Jul 13, 2022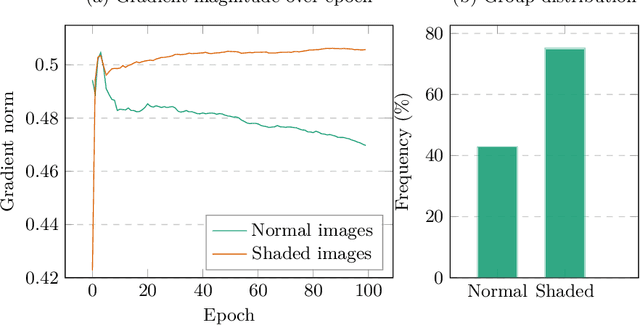

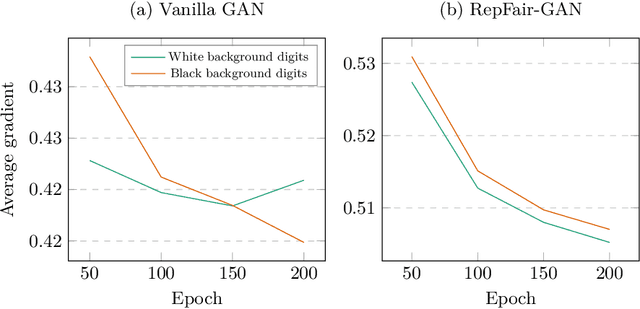
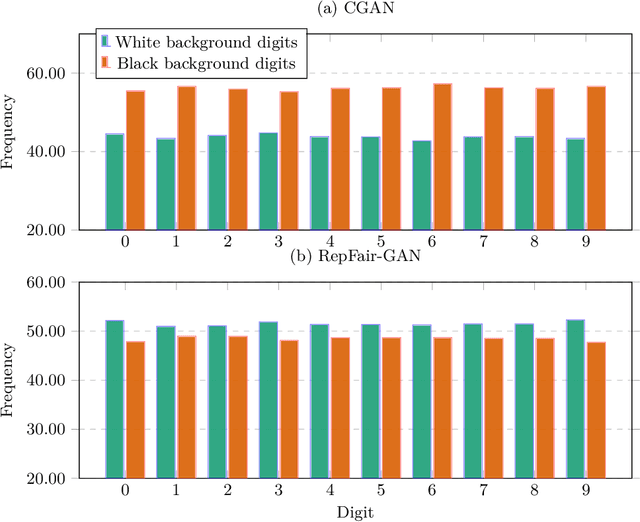
Fairness has become an essential problem in many domains of Machine Learning (ML), such as classification, natural language processing, and Generative Adversarial Networks (GANs). In this research effort, we study the unfairness of GANs. We formally define a new fairness notion for generative models in terms of the distribution of generated samples sharing the same protected attributes (gender, race, etc.). The defined fairness notion (representational fairness) requires the distribution of the sensitive attributes at the test time to be uniform, and, in particular for GAN model, we show that this fairness notion is violated even when the dataset contains equally represented groups, i.e., the generator favors generating one group of samples over the others at the test time. In this work, we shed light on the source of this representation bias in GANs along with a straightforward method to overcome this problem. We first show on two widely used datasets (MNIST, SVHN) that when the norm of the gradient of one group is more important than the other during the discriminator's training, the generator favours sampling data from one group more than the other at test time. We then show that controlling the groups' gradient norm by performing group-wise gradient norm clipping in the discriminator during the training leads to a more fair data generation in terms of representational fairness compared to existing models while preserving the quality of generated samples.
Adversarial Stacked Auto-Encoders for Fair Representation Learning
Jul 27, 2021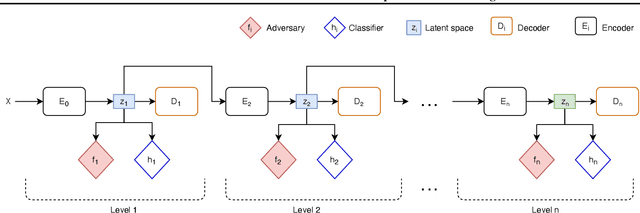
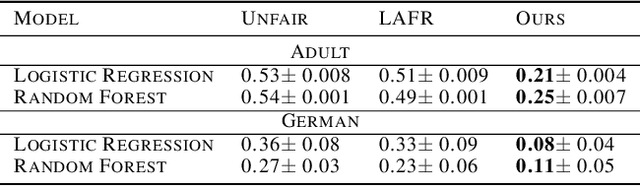

Training machine learning models with the only accuracy as a final goal may promote prejudices and discriminatory behaviors embedded in the data. One solution is to learn latent representations that fulfill specific fairness metrics. Different types of learning methods are employed to map data into the fair representational space. The main purpose is to learn a latent representation of data that scores well on a fairness metric while maintaining the usability for the downstream task. In this paper, we propose a new fair representation learning approach that leverages different levels of representation of data to tighten the fairness bounds of the learned representation. Our results show that stacking different auto-encoders and enforcing fairness at different latent spaces result in an improvement of fairness compared to other existing approaches.
DP-SGD vs PATE: Which Has Less Disparate Impact on Model Accuracy?
Jun 22, 2021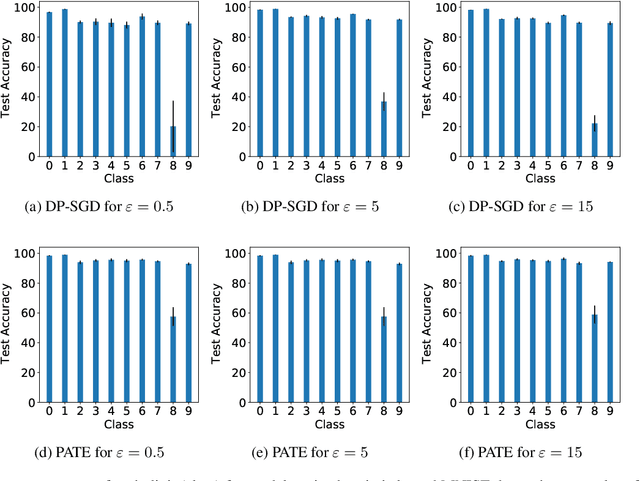
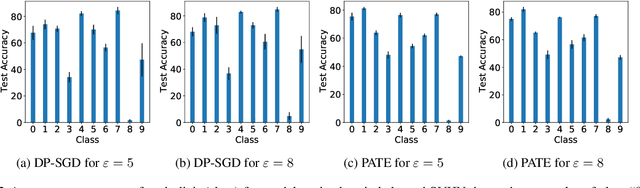
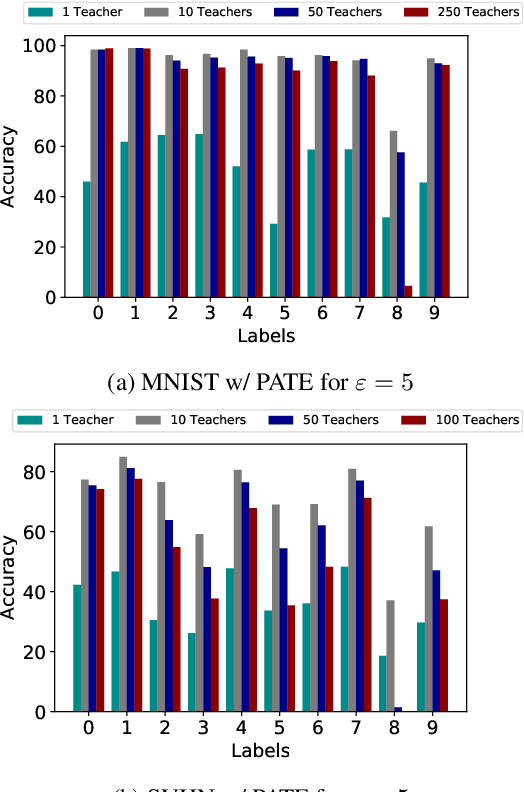
Recent advances in differentially private deep learning have demonstrated that application of differential privacy, specifically the DP-SGD algorithm, has a disparate impact on different sub-groups in the population, which leads to a significantly high drop-in model utility for sub-populations that are under-represented (minorities), compared to well-represented ones. In this work, we aim to compare PATE, another mechanism for training deep learning models using differential privacy, with DP-SGD in terms of fairness. We show that PATE does have a disparate impact too, however, it is much less severe than DP-SGD. We draw insights from this observation on what might be promising directions in achieving better fairness-privacy trade-offs.
On the Fairness of Generative Adversarial Networks (GANs)
Mar 01, 2021

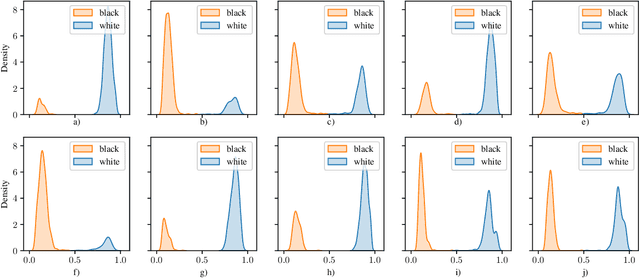
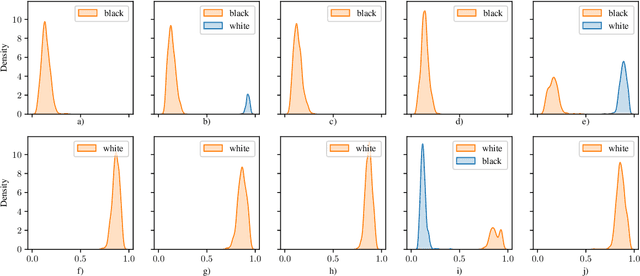
Generative adversarial networks (GANs) are one of the greatest advances in AI in recent years. With their ability to directly learn the probability distribution of data, and then sample synthetic realistic data. Many applications have emerged, using GANs to solve classical problems in machine learning, such as data augmentation, class unbalance problems, and fair representation learning. In this paper, we analyze and highlight fairness concerns of GANs model. In this regard, we show empirically that GANs models may inherently prefer certain groups during the training process and therefore they're not able to homogeneously generate data from different groups during the testing phase. Furthermore, we propose solutions to solve this issue by conditioning the GAN model towards samples' group or using ensemble method (boosting) to allow the GAN model to leverage distributed structure of data during the training phase and generate groups at equal rate during the testing phase.