 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperative Task Offloading through Asynchronous Deep Reinforcement Learning in Mobile Edge Computing for Future Networks
Apr 24, 2025Future networks (including 6G) are poised to accelerate the realisation of Internet of Everything. However, it will result in a high demand for computing resources to support new services. Mobile Edge Computing (MEC) is a promising solution, enabling to offload computation-intensive tasks to nearby edge servers from the end-user devices, thereby reducing latency and energy consumption. However, relying solely on a single MEC server for task offloading can lead to uneven resource utilisation and suboptimal performance in complex scenarios. Additionally, traditional task offloading strategies specialise in centralised policy decisions, which unavoidably entail extreme transmission latency and reach computational bottleneck. To fill the gaps, we propose a latency and energy efficient Cooperative Task Offloading framework with Transformer-driven Prediction (CTO-TP), leveraging asynchronous multi-agent deep reinforcement learning to address these challenges. This approach fosters edge-edge cooperation and decreases the synchronous waiting time by performing asynchronous training, optimising task offloading, and resource allocation across distributed networks. The performance evaluation demonstrates that the proposed CTO-TP algorithm reduces up to 80% overall system latency and 87% energy consumption compared to the baseline schemes.
Federated Fairness Analytics: Quantifying Fairness in Federated Learning
Aug 15, 2024



Federated Learning (FL) is a privacy-enhancing technology for distributed ML. By training models locally and aggregating updates - a federation learns together, while bypassing centralised data collection. FL is increasingly popular in healthcare, finance and personal computing. However, it inherits fairness challenges from classical ML and introduces new ones, resulting from differences in data quality, client participation, communication constraints, aggregation methods and underlying hardware. Fairness remains an unresolved issue in FL and the community has identified an absence of succinct definitions and metrics to quantify fairness; to address this, we propose Federated Fairness Analytics - a methodology for measuring fairness. Our definition of fairness comprises four notions with novel, corresponding metrics. They are symptomatically defined and leverage techniques originating from XAI, cooperative game-theory and networking engineering. We tested a range of experimental settings, varying the FL approach, ML task and data settings. The results show that statistical heterogeneity and client participation affect fairness and fairness conscious approaches such as Ditto and q-FedAvg marginally improve fairness-performance trade-offs. Using our techniques, FL practitioners can uncover previously unobtainable insights into their system's fairness, at differing levels of granularity in order to address fairness challenges in FL. We have open-sourced our work at: https://github.com/oscardilley/federated-fairness.
Adversarial Stacked Auto-Encoders for Fair Representation Learning
Jul 27, 2021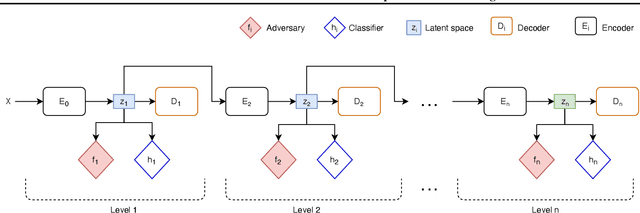
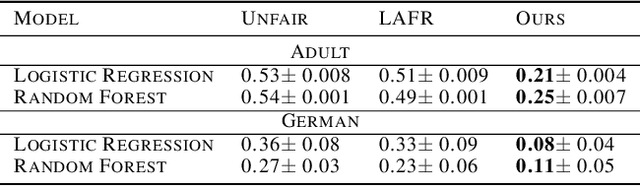

Training machine learning models with the only accuracy as a final goal may promote prejudices and discriminatory behaviors embedded in the data. One solution is to learn latent representations that fulfill specific fairness metrics. Different types of learning methods are employed to map data into the fair representational space. The main purpose is to learn a latent representation of data that scores well on a fairness metric while maintaining the usability for the downstream task. In this paper, we propose a new fair representation learning approach that leverages different levels of representation of data to tighten the fairness bounds of the learned representation. Our results show that stacking different auto-encoders and enforcing fairness at different latent spaces result in an improvement of fairness compared to other existing approaches.
On the Fairness of Generative Adversarial Networks (GANs)
Mar 01, 2021

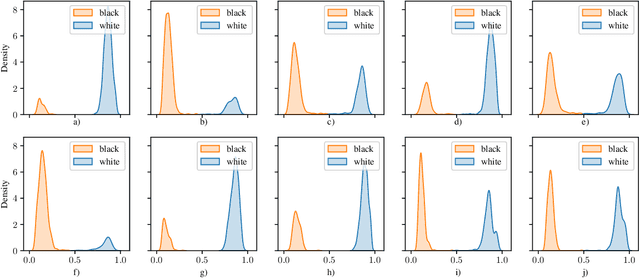
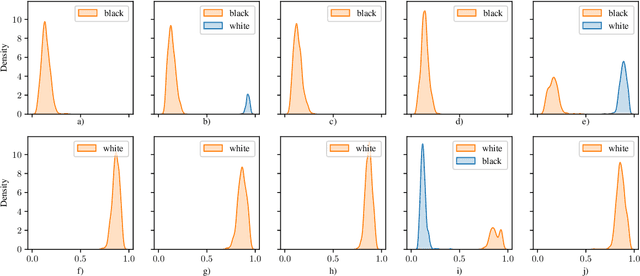
Generative adversarial networks (GANs) are one of the greatest advances in AI in recent years. With their ability to directly learn the probability distribution of data, and then sample synthetic realistic data. Many applications have emerged, using GANs to solve classical problems in machine learning, such as data augmentation, class unbalance problems, and fair representation learning. In this paper, we analyze and highlight fairness concerns of GANs model. In this regard, we show empirically that GANs models may inherently prefer certain groups during the training process and therefore they're not able to homogeneously generate data from different groups during the testing phase. Furthermore, we propose solutions to solve this issue by conditioning the GAN model towards samples' group or using ensemble method (boosting) to allow the GAN model to leverage distributed structure of data during the training phase and generate groups at equal rate during the testing phase.
Machine Learning in IoT Security: Current Solutions and Future Challenges
Mar 14, 2019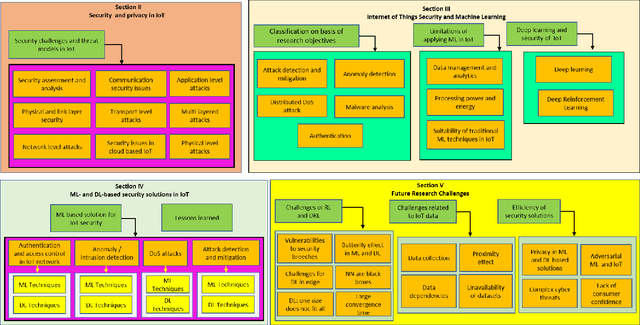

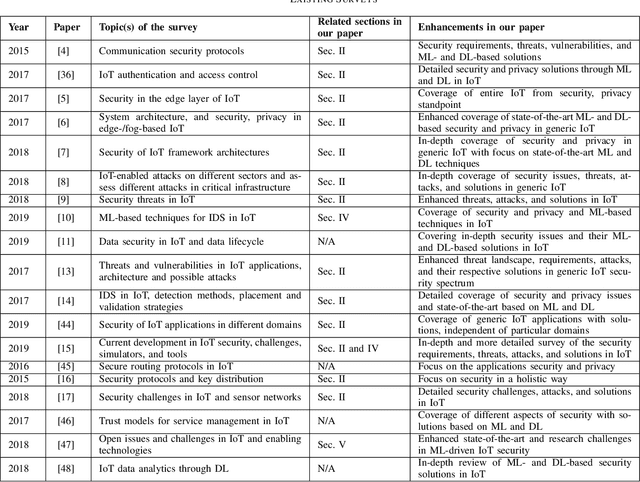
The future Internet of Things (IoT) will have a deep economical, commercial and social impact on our lives. The participating nodes in IoT networks are usually resource-constrained, which makes them luring targets for cyber attacks. In this regard, extensive efforts have been made to address the security and privacy issues in IoT networks primarily through traditional cryptographic approaches. However, the unique characteristics of IoT nodes render the existing solutions insufficient to encompass the entire security spectrum of the IoT networks. This is, at least in part, because of the resource constraints, heterogeneity, massive real-time data generated by the IoT devices, and the extensively dynamic behavior of the networks. Therefore, Machine Learning (ML) and Deep Learning (DL) techniques, which are able to provide embedded intelligence in the IoT devices and networks, are leveraged to cope with different security problems. In this paper, we systematically review the security requirements, attack vectors, and the current security solutions for the IoT networks. We then shed light on the gaps in these security solutions that call for ML and DL approaches. We also discuss in detail the existing ML and DL solutions for addressing different security problems in IoT networks. At last, based on the detailed investigation of the existing solutions in the literature, we discuss the future research directions for ML- and DL-based IoT security.
Multi-label Class-imbalanced Action Recognition in Hockey Videos via 3D Convolutional Neural Networks
May 03, 2018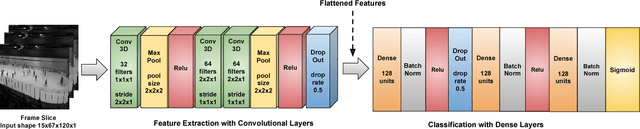



Automatic analysis of the video is one of most complex problems in the fields of computer vision and machine learning. A significant part of this research deals with (human) activity recognition (HAR) since humans, and the activities that they perform, generate most of the video semantics. Video-based HAR has applications in various domains, but one of the most important and challenging is HAR in sports videos. Some of the major issues include high inter- and intra-class variations, large class imbalance, the presence of both group actions and single player actions, and recognizing simultaneous actions, i.e., the multi-label learning problem. Keeping in mind these challenges and the recent success of CNNs in solving various computer vision problems, in this work, we implement a 3D CNN based multi-label deep HAR system for multi-label class-imbalanced action recognition in hockey videos. We test our system for two different scenarios: an ensemble of $k$ binary networks vs. a single $k$-output network, on a publicly available dataset. We also compare our results with the system that was originally designed for the chosen dataset. Experimental results show that the proposed approach performs better than the existing solution.
Segmented and Non-Segmented Stacked Denoising Autoencoder for Hyperspectral Band Reduction
Apr 22, 2018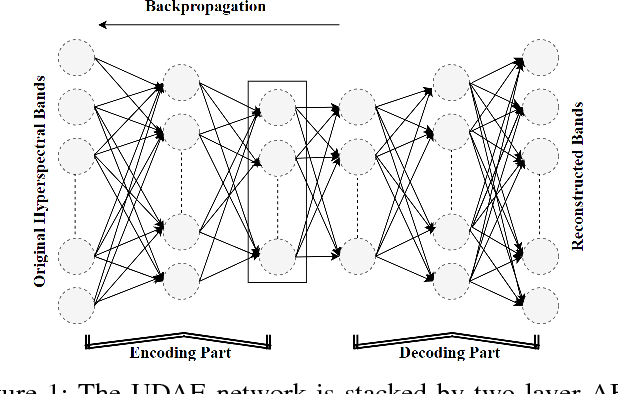


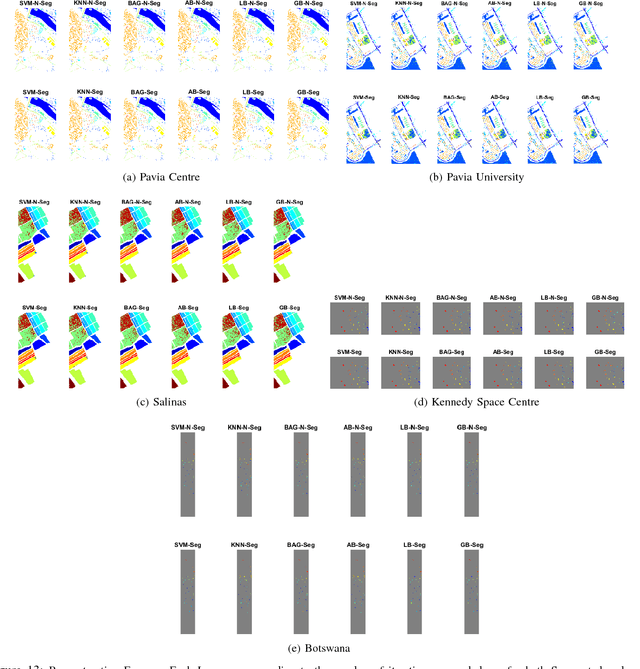
Hyperspectral image analysis often requires selecting the most informative bands instead of processing the whole data without losing the key information. Existing band reduction (BR) methods have the capability to reveal the nonlinear properties exhibited in the data but at the expense of loosing its original representation. To cope with the said issue, an unsupervised non-linear segmented and non-segmented stacked denoising autoencoder (UDAE) based BR method is proposed. Our aim is to find an optimal mapping and construct a lower-dimensional space that has a similar structure to the original data with least reconstruction error. The proposed method first confronts the original hyperspectral data into smaller regions in a spatial domain and then each region is processed by UDAE individually. This results in reduced complexity and improved efficiency of BR for both semi-supervised and unsupervised tasks, i.e. classification and clustering. Our experiments on publicly available hyperspectral datasets with various types of classifiers demonstrate the effectiveness of UDAE method which equates favorably with other state-of-the-art dimensionality reduction and BR methods.