 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Stacked Auto-Encoders for Fair Representation Learning
Jul 27, 2021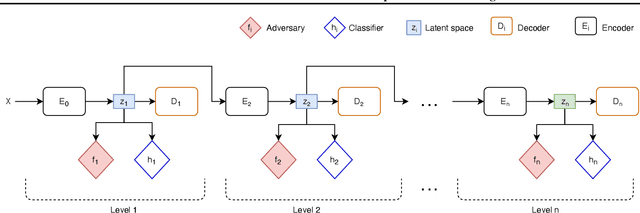
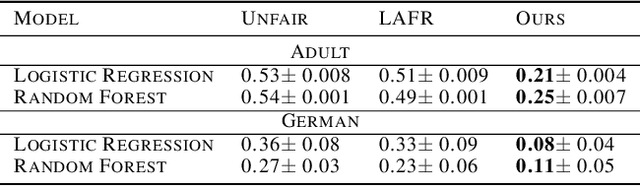

Training machine learning models with the only accuracy as a final goal may promote prejudices and discriminatory behaviors embedded in the data. One solution is to learn latent representations that fulfill specific fairness metrics. Different types of learning methods are employed to map data into the fair representational space. The main purpose is to learn a latent representation of data that scores well on a fairness metric while maintaining the usability for the downstream task. In this paper, we propose a new fair representation learning approach that leverages different levels of representation of data to tighten the fairness bounds of the learned representation. Our results show that stacking different auto-encoders and enforcing fairness at different latent spaces result in an improvement of fairness compared to other existing approaches.
On the Fairness of Generative Adversarial Networks (GANs)
Mar 01, 2021

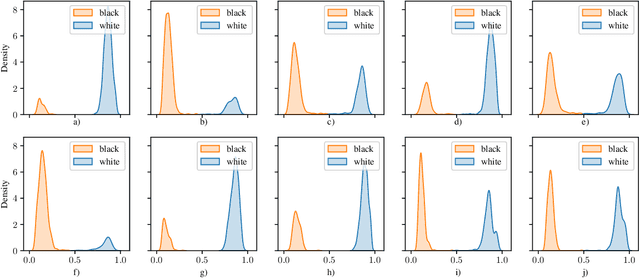
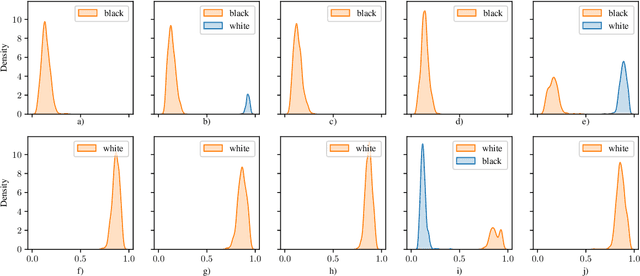
Generative adversarial networks (GANs) are one of the greatest advances in AI in recent years. With their ability to directly learn the probability distribution of data, and then sample synthetic realistic data. Many applications have emerged, using GANs to solve classical problems in machine learning, such as data augmentation, class unbalance problems, and fair representation learning. In this paper, we analyze and highlight fairness concerns of GANs model. In this regard, we show empirically that GANs models may inherently prefer certain groups during the training process and therefore they're not able to homogeneously generate data from different groups during the testing phase. Furthermore, we propose solutions to solve this issue by conditioning the GAN model towards samples' group or using ensemble method (boosting) to allow the GAN model to leverage distributed structure of data during the training phase and generate groups at equal rate during the testing phase.