 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProfiling AI Models: Towards Efficient Computation Offloading in Heterogeneous Edge AI Systems
Oct 30, 2024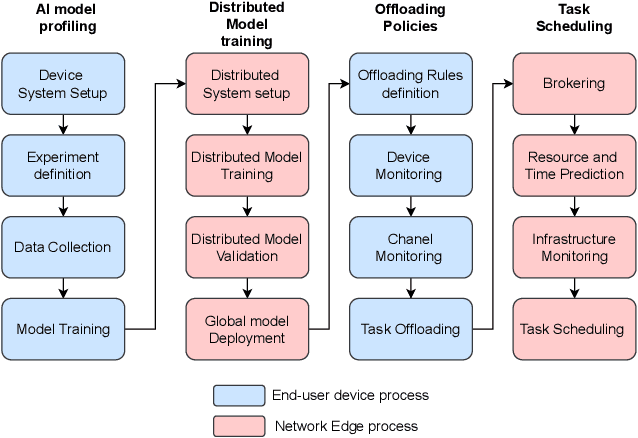
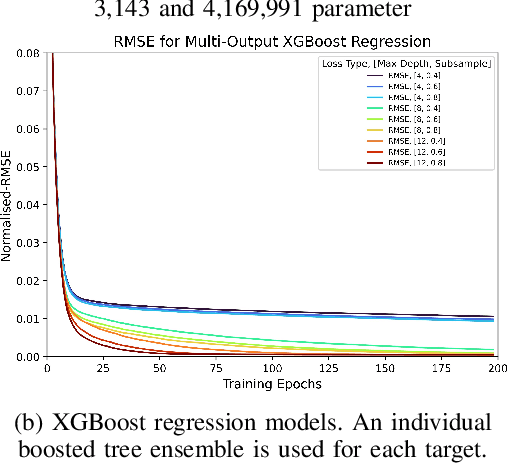
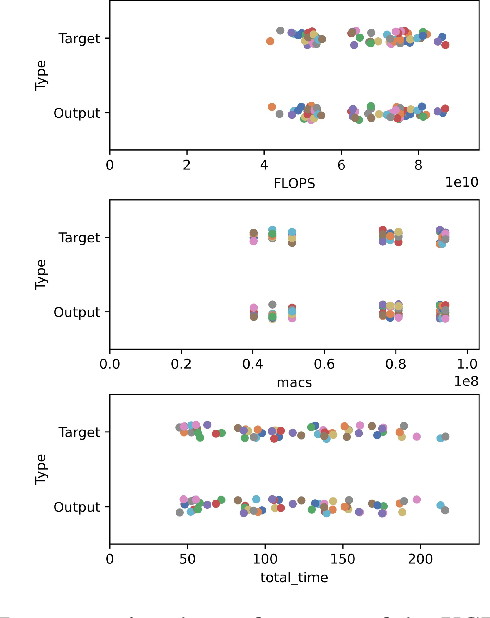
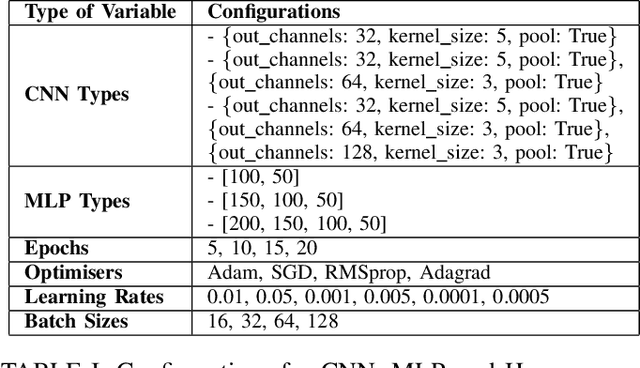
The rapid growth of end-user AI applications, such as computer vision and generative AI, has led to immense data and processing demands often exceeding user devices' capabilities. Edge AI addresses this by offloading computation to the network edge, crucial for future services in 6G networks. However, it faces challenges such as limited resources during simultaneous offloads and the unrealistic assumption of homogeneous system architecture. To address these, we propose a research roadmap focused on profiling AI models, capturing data about model types, hyperparameters, and underlying hardware to predict resource utilisation and task completion time. Initial experiments with over 3,000 runs show promise in optimising resource allocation and enhancing Edge AI performance.
Federated Fairness Analytics: Quantifying Fairness in Federated Learning
Aug 15, 2024



Federated Learning (FL) is a privacy-enhancing technology for distributed ML. By training models locally and aggregating updates - a federation learns together, while bypassing centralised data collection. FL is increasingly popular in healthcare, finance and personal computing. However, it inherits fairness challenges from classical ML and introduces new ones, resulting from differences in data quality, client participation, communication constraints, aggregation methods and underlying hardware. Fairness remains an unresolved issue in FL and the community has identified an absence of succinct definitions and metrics to quantify fairness; to address this, we propose Federated Fairness Analytics - a methodology for measuring fairness. Our definition of fairness comprises four notions with novel, corresponding metrics. They are symptomatically defined and leverage techniques originating from XAI, cooperative game-theory and networking engineering. We tested a range of experimental settings, varying the FL approach, ML task and data settings. The results show that statistical heterogeneity and client participation affect fairness and fairness conscious approaches such as Ditto and q-FedAvg marginally improve fairness-performance trade-offs. Using our techniques, FL practitioners can uncover previously unobtainable insights into their system's fairness, at differing levels of granularity in order to address fairness challenges in FL. We have open-sourced our work at: https://github.com/oscardilley/federated-fairness.
Federated Transfer Component Analysis Towards Effective VNF Profiling
May 01, 2024



The increasing concerns of knowledge transfer and data privacy challenge the traditional gather-and-analyse paradigm in networks. Specifically, the intelligent orchestration of Virtual Network Functions (VNFs) requires understanding and profiling the resource consumption. However, profiling all kinds of VNFs is time-consuming. It is important to consider transferring the well-profiled VNF knowledge to other lack-profiled VNF types while keeping data private. To this end, this paper proposes a Federated Transfer Component Analysis (FTCA) method between the source and target VNFs. FTCA first trains Generative Adversarial Networks (GANs) based on the source VNF profiling data, and the trained GANs model is sent to the target VNF domain. Then, FTCA realizes federated domain adaptation by using the generated source VNF data and less target VNF profiling data, while keeping the raw data locally. Experiments show that the proposed FTCA can effectively predict the required resources for the target VNF. Specifically, the RMSE index of the regression model decreases by 38.5% and the R-squared metric advances up to 68.6%.
A Framework for History-Aware Hyperparameter Optimisation in Reinforcement Learning
Mar 09, 2023A Reinforcement Learning (RL) system depends on a set of initial conditions (hyperparameters) that affect the system's performance. However, defining a good choice of hyperparameters is a challenging problem. Hyperparameter tuning often requires manual or automated searches to find optimal values. Nonetheless, a noticeable limitation is the high cost of algorithm evaluation for complex models, making the tuning process computationally expensive and time-consuming. In this paper, we propose a framework based on integrating complex event processing and temporal models, to alleviate these trade-offs. Through this combination, it is possible to gain insights about a running RL system efficiently and unobtrusively based on data stream monitoring and to create abstract representations that allow reasoning about the historical behaviour of the RL system. The obtained knowledge is exploited to provide feedback to the RL system for optimising its hyperparameters while making effective use of parallel resources. We introduce a novel history-aware epsilon-greedy logic for hyperparameter optimisation that instead of using static hyperparameters that are kept fixed for the whole training, adjusts the hyperparameters at runtime based on the analysis of the agent's performance over time windows in a single agent's lifetime. We tested the proposed approach in a 5G mobile communications case study that uses DQN, a variant of RL, for its decision-making. Our experiments demonstrated the effects of hyperparameter tuning using history on training stability and reward values. The encouraging results show that the proposed history-aware framework significantly improved performance compared to traditional hyperparameter tuning approaches.