 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for History-Aware Hyperparameter Optimisation in Reinforcement Learning
Mar 09, 2023A Reinforcement Learning (RL) system depends on a set of initial conditions (hyperparameters) that affect the system's performance. However, defining a good choice of hyperparameters is a challenging problem. Hyperparameter tuning often requires manual or automated searches to find optimal values. Nonetheless, a noticeable limitation is the high cost of algorithm evaluation for complex models, making the tuning process computationally expensive and time-consuming. In this paper, we propose a framework based on integrating complex event processing and temporal models, to alleviate these trade-offs. Through this combination, it is possible to gain insights about a running RL system efficiently and unobtrusively based on data stream monitoring and to create abstract representations that allow reasoning about the historical behaviour of the RL system. The obtained knowledge is exploited to provide feedback to the RL system for optimising its hyperparameters while making effective use of parallel resources. We introduce a novel history-aware epsilon-greedy logic for hyperparameter optimisation that instead of using static hyperparameters that are kept fixed for the whole training, adjusts the hyperparameters at runtime based on the analysis of the agent's performance over time windows in a single agent's lifetime. We tested the proposed approach in a 5G mobile communications case study that uses DQN, a variant of RL, for its decision-making. Our experiments demonstrated the effects of hyperparameter tuning using history on training stability and reward values. The encouraging results show that the proposed history-aware framework significantly improved performance compared to traditional hyperparameter tuning approaches.
Automating In-Network Machine Learning
May 18, 2022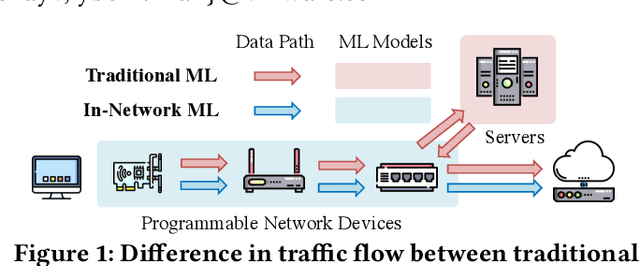
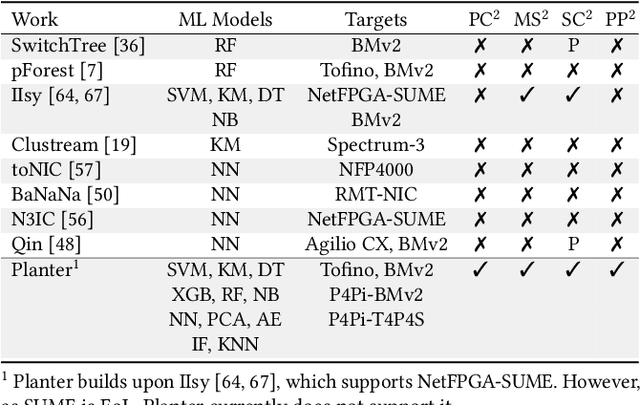


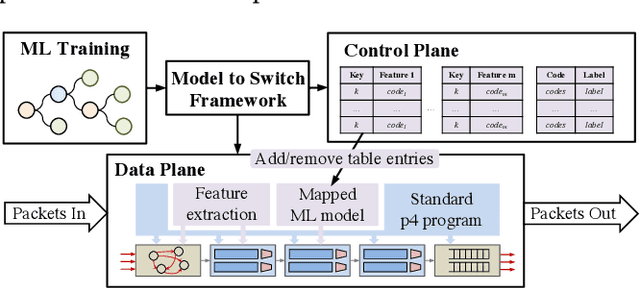
Using programmable network devices to aid in-network machine learning has been the focus of significant research. However, most of the research was of a limited scope, providing a proof of concept or describing a closed-source algorithm. To date, no general solution has been provided for mapping machine learning algorithms to programmable network devices. In this paper, we present Planter, an open-source, modular framework for mapping trained machine learning models to programmable devices. Planter supports a wide range of machine learning models, multiple targets and can be easily extended. The evaluation of Planter compares different mapping approaches, and demonstrates the feasibility, performance, and resource efficiency for applications such as anomaly detection, financial transactions, and quality of experience. The results show that Planter-based in-network machine learning algorithms can run at line rate, have a negligible effect on latency, coexist with standard switching functionality, and have no or minor accuracy trade-offs.
IIsy: Practical In-Network Classification
May 17, 2022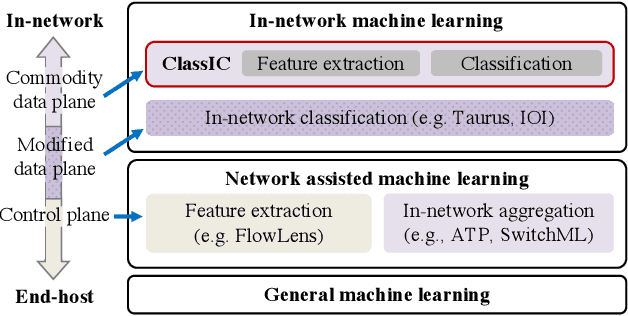
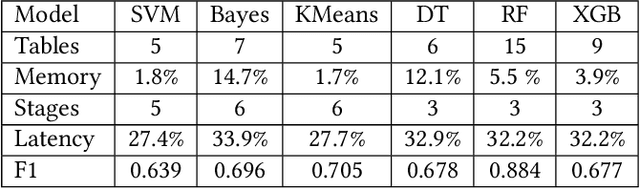
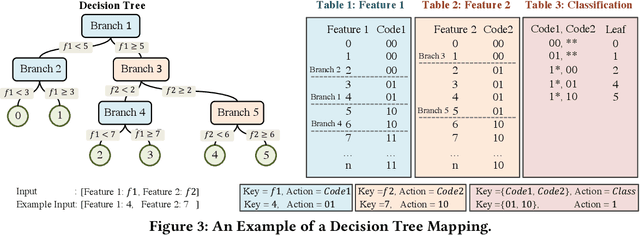
The rat race between user-generated data and data-processing systems is currently won by data. The increased use of machine learning leads to further increase in processing requirements, while data volume keeps growing. To win the race, machine learning needs to be applied to the data as it goes through the network. In-network classification of data can reduce the load on servers, reduce response time and increase scalability. In this paper, we introduce IIsy, implementing machine learning classification models in a hybrid fashion using off-the-shelf network devices. IIsy targets three main challenges of in-network classification: (i) mapping classification models to network devices (ii) extracting the required features and (iii) addressing resource and functionality constraints. IIsy supports a range of traditional and ensemble machine learning models, scaling independently of the number of stages in a switch pipeline. Moreover, we demonstrate the use of IIsy for hybrid classification, where a small model is implemented on a switch and a large model at the backend, achieving near optimal classification results, while significantly reducing latency and load on the servers.