 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Anomalies in Machine Learning Infrastructure via Hardware Telemetry
Oct 29, 2025Modern machine learning (ML) has grown into a tightly coupled, full-stack ecosystem that combines hardware, software, network, and applications. Many users rely on cloud providers for elastic, isolated, and cost-efficient resources. Unfortunately, these platforms as a service use virtualization, which means operators have little insight into the users' workloads. This hinders resource optimizations by the operator, which is essential to ensure cost efficiency and minimize execution time. In this paper, we argue that workload knowledge is unnecessary for system-level optimization. We propose System-X, which takes a \emph{hardware-centric} approach, relying only on hardware signals -- fully accessible by operators. Using low-level signals collected from the system, System-X detects anomalies through an unsupervised learning pipeline. The pipeline is developed by analyzing over 30 popular ML models on various hardware platforms, ensuring adaptability to emerging workloads and unknown deployment patterns. Using System-X, we successfully identified both network and system configuration issues, accelerating the DeepSeek model by 5.97%.
Automating In-Network Machine Learning
May 18, 2022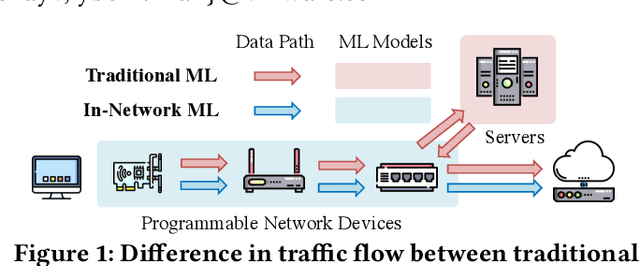
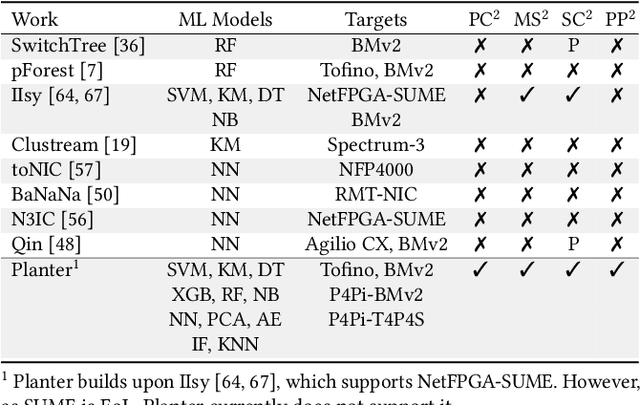


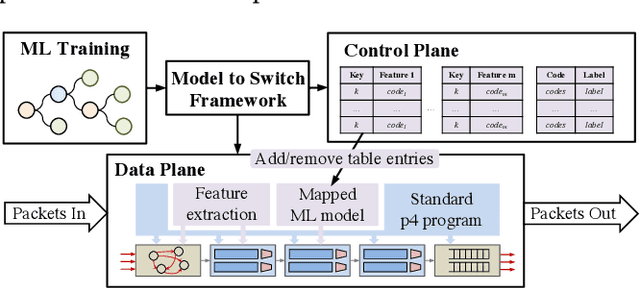
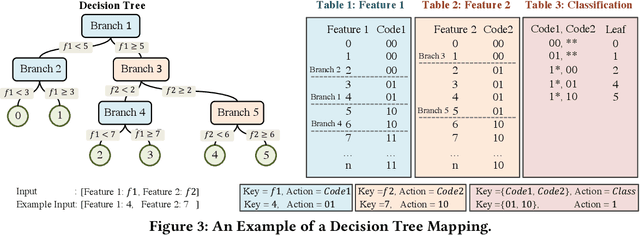
Using programmable network devices to aid in-network machine learning has been the focus of significant research. However, most of the research was of a limited scope, providing a proof of concept or describing a closed-source algorithm. To date, no general solution has been provided for mapping machine learning algorithms to programmable network devices. In this paper, we present Planter, an open-source, modular framework for mapping trained machine learning models to programmable devices. Planter supports a wide range of machine learning models, multiple targets and can be easily extended. The evaluation of Planter compares different mapping approaches, and demonstrates the feasibility, performance, and resource efficiency for applications such as anomaly detection, financial transactions, and quality of experience. The results show that Planter-based in-network machine learning algorithms can run at line rate, have a negligible effect on latency, coexist with standard switching functionality, and have no or minor accuracy trade-offs.
IIsy: Practical In-Network Classification
May 17, 2022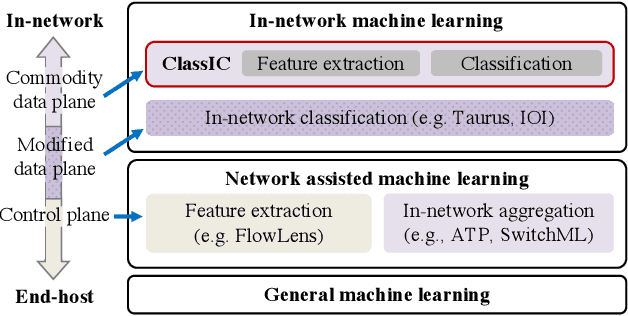
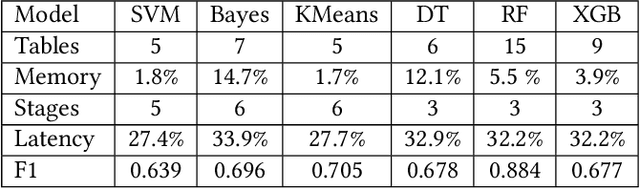
The rat race between user-generated data and data-processing systems is currently won by data. The increased use of machine learning leads to further increase in processing requirements, while data volume keeps growing. To win the race, machine learning needs to be applied to the data as it goes through the network. In-network classification of data can reduce the load on servers, reduce response time and increase scalability. In this paper, we introduce IIsy, implementing machine learning classification models in a hybrid fashion using off-the-shelf network devices. IIsy targets three main challenges of in-network classification: (i) mapping classification models to network devices (ii) extracting the required features and (iii) addressing resource and functionality constraints. IIsy supports a range of traditional and ensemble machine learning models, scaling independently of the number of stages in a switch pipeline. Moreover, we demonstrate the use of IIsy for hybrid classification, where a small model is implemented on a switch and a large model at the backend, achieving near optimal classification results, while significantly reducing latency and load on the servers.
Filling gaps in trustworthy development of AI
Dec 14, 2021The range of application of artificial intelligence (AI) is vast, as is the potential for harm. Growing awareness of potential risks from AI systems has spurred action to address those risks, while eroding confidence in AI systems and the organizations that develop them. A 2019 study found over 80 organizations that published and adopted "AI ethics principles'', and more have joined since. But the principles often leave a gap between the "what" and the "how" of trustworthy AI development. Such gaps have enabled questionable or ethically dubious behavior, which casts doubts on the trustworthiness of specific organizations, and the field more broadly. There is thus an urgent need for concrete methods that both enable AI developers to prevent harm and allow them to demonstrate their trustworthiness through verifiable behavior. Below, we explore mechanisms (drawn from arXiv:2004.07213) for creating an ecosystem where AI developers can earn trust - if they are trustworthy. Better assessment of developer trustworthiness could inform user choice, employee actions, investment decisions, legal recourse, and emerging governance regimes.