 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for History-Aware Hyperparameter Optimisation in Reinforcement Learning
Mar 09, 2023A Reinforcement Learning (RL) system depends on a set of initial conditions (hyperparameters) that affect the system's performance. However, defining a good choice of hyperparameters is a challenging problem. Hyperparameter tuning often requires manual or automated searches to find optimal values. Nonetheless, a noticeable limitation is the high cost of algorithm evaluation for complex models, making the tuning process computationally expensive and time-consuming. In this paper, we propose a framework based on integrating complex event processing and temporal models, to alleviate these trade-offs. Through this combination, it is possible to gain insights about a running RL system efficiently and unobtrusively based on data stream monitoring and to create abstract representations that allow reasoning about the historical behaviour of the RL system. The obtained knowledge is exploited to provide feedback to the RL system for optimising its hyperparameters while making effective use of parallel resources. We introduce a novel history-aware epsilon-greedy logic for hyperparameter optimisation that instead of using static hyperparameters that are kept fixed for the whole training, adjusts the hyperparameters at runtime based on the analysis of the agent's performance over time windows in a single agent's lifetime. We tested the proposed approach in a 5G mobile communications case study that uses DQN, a variant of RL, for its decision-making. Our experiments demonstrated the effects of hyperparameter tuning using history on training stability and reward values. The encouraging results show that the proposed history-aware framework significantly improved performance compared to traditional hyperparameter tuning approaches.
RDMSim: An Exemplar for Evaluation and Comparison of Decision-Making Techniques for Self-Adaptation
May 05, 2021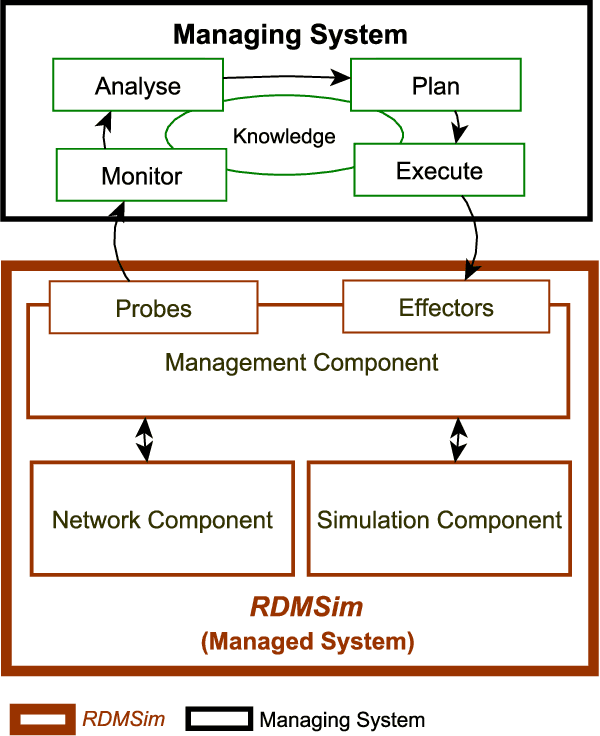
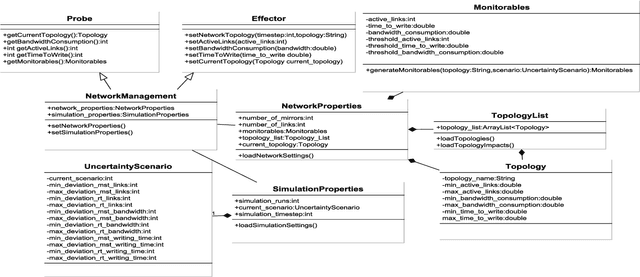
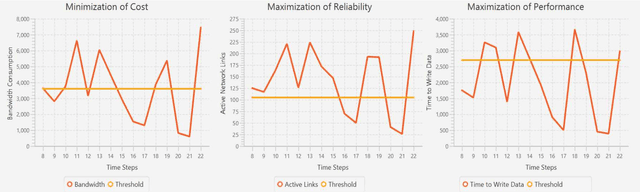
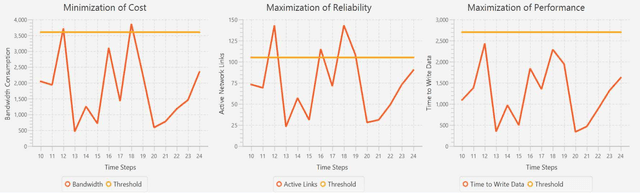
Decision-making for self-adaptation approaches need to address different challenges, including the quantification of the uncertainty of events that cannot be foreseen in advance and their effects, and dealing with conflicting objectives that inherently involve multi-objective decision making (e.g., avoiding costs vs. providing reliable service). To enable researchers to evaluate and compare decision-making techniques for self-adaptation, we present the RDMSim exemplar. RDMSim enables researchers to evaluate and compare techniques for decision-making under environmental uncertainty that support self-adaptation. The focus of the exemplar is on the domain problem related to Remote Data Mirroring, which gives opportunity to face the challenges described above. RDMSim provides probe and effector components for easy integration with external adaptation managers, which are associated with decision-making techniques and based on the MAPE-K loop. Specifically, the paper presents (i) RDMSim, a simulator for real-world experimentation, (ii) a set of realistic simulation scenarios that can be used for experimentation and comparison purposes, (iii) data for the sake of comparison.
Gamified and Self-Adaptive Applications for the Common Good: Research Challenges Ahead
Mar 22, 2021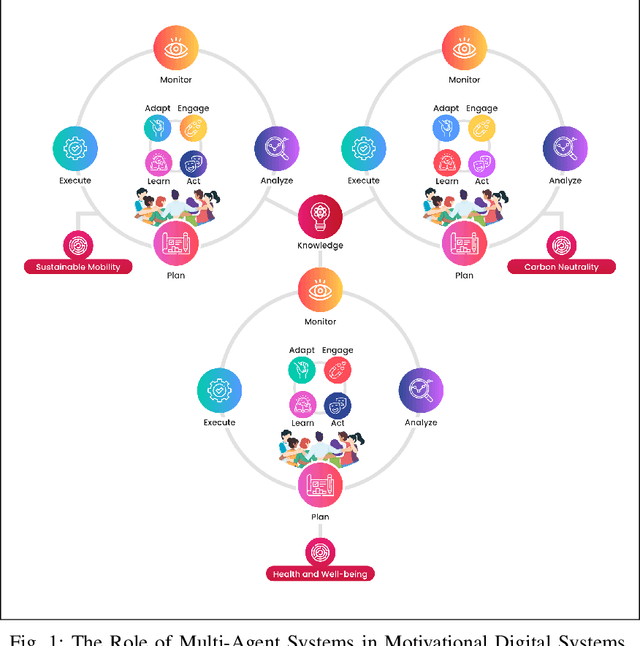
Motivational digital systems offer capabilities to engage and motivate end-users to foster behavioral changes towards a common goal. In general these systems use gamification principles in non-games contexts. Over the years, gamification has gained consensus among researchers and practitioners as a tool to motivate people to perform activities with the ultimate goal of promoting behavioural change, or engaging the users to perform activities that can offer relevant benefits but which can be seen as unrewarding and even tedious. There exists a plethora of heterogeneous application scenarios towards reaching the common good that can benefit from gamification. However, an open problem is how to effectively combine multiple motivational campaigns to maximise the degree of participation without exposing the system to counterproductive behaviours. We conceive motivational digital systems as multi-agent systems: self-adaptation is a feature of the overall system, while individual agents may self-adapt in order to leverage other agents' resources, functionalities and capabilities to perform tasks more efficiently and effectively. Consequently, multiple campaigns can be run and adapted to reach common good. At the same time, agents are grouped into micro-communities in which agents contribute with their own social capital and leverage others' capabilities to balance their weaknesses. In this paper we propose our vision on how the principles at the base of the autonomous and multi-agent systems can be exploited to design multi-challenge motivational systems to engage smart communities towards common goals. We present an initial version of a general framework based on the MAPE-K loop and a set of research challenges that characterise our research roadmap for the implementation of our vision.