 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Release: Access Considerations for Generative AI Systems
Feb 23, 2025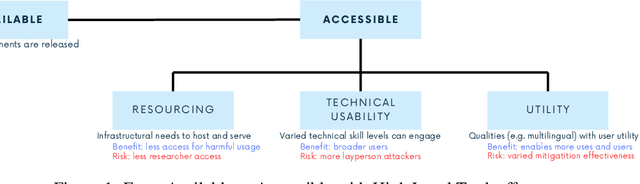
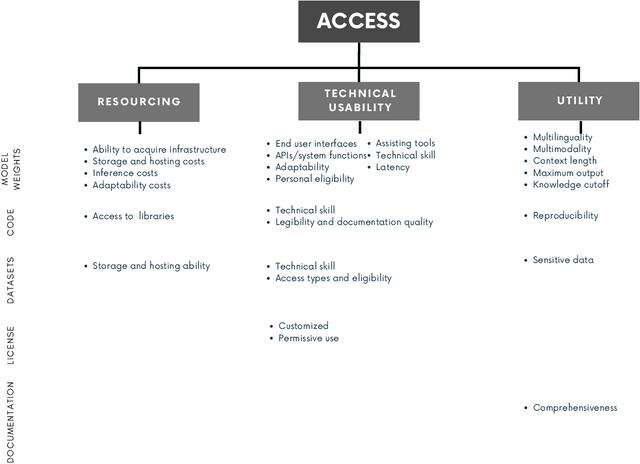
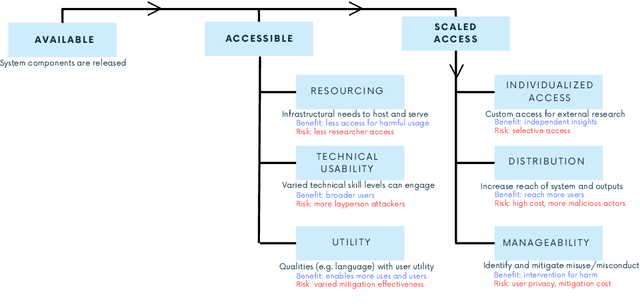
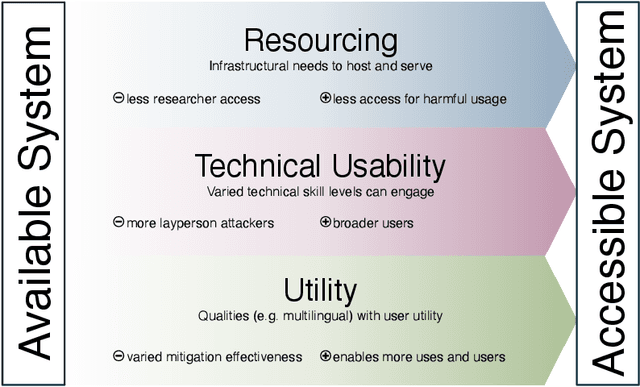
Generative AI release decisions determine whether system components are made available, but release does not address many other elements that change how users and stakeholders are able to engage with a system. Beyond release, access to system components informs potential risks and benefits. Access refers to practical needs, infrastructurally, technically, and societally, in order to use available components in some way. We deconstruct access along three axes: resourcing, technical usability, and utility. Within each category, a set of variables per system component clarify tradeoffs. For example, resourcing requires access to computing infrastructure to serve model weights. We also compare the accessibility of four high performance language models, two open-weight and two closed-weight, showing similar considerations for all based instead on access variables. Access variables set the foundation for being able to scale or increase access to users; we examine the scale of access and how scale affects ability to manage and intervene on risks. This framework better encompasses the landscape and risk-benefit tradeoffs of system releases to inform system release decisions, research, and policy.
Exploring the Relevance of Data Privacy-Enhancing Technologies for AI Governance Use Cases
Mar 20, 2023
The development of privacy-enhancing technologies has made immense progress in reducing trade-offs between privacy and performance in data exchange and analysis. Similar tools for structured transparency could be useful for AI governance by offering capabilities such as external scrutiny, auditing, and source verification. It is useful to view these different AI governance objectives as a system of information flows in order to avoid partial solutions and significant gaps in governance, as there may be significant overlap in the software stacks needed for the AI governance use cases mentioned in this text. When viewing the system as a whole, the importance of interoperability between these different AI governance solutions becomes clear. Therefore, it is imminently important to look at these problems in AI governance as a system, before these standards, auditing procedures, software, and norms settle into place.
Towards General-purpose Infrastructure for Protecting Scientific Data Under Study
Oct 04, 2021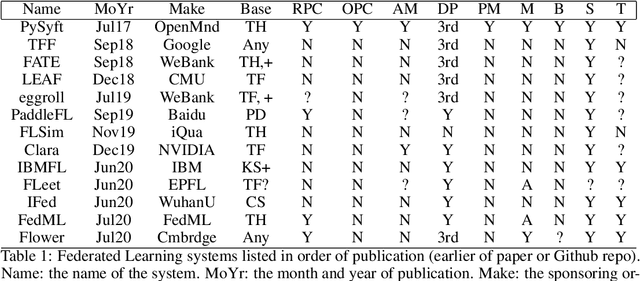

The scientific method presents a key challenge to privacy because it requires many samples to support a claim. When samples are commercially valuable or privacy-sensitive enough, their owners have strong reasons to avoid releasing them for scientific study. Privacy techniques seek to mitigate this tension by enforcing limits on one's ability to use studied samples for secondary purposes. Recent work has begun combining these techniques into end-to-end systems for protecting data. In this work, we assemble the first such combination which is sufficient for a privacy-layman to use familiar tools to experiment over private data while the infrastructure automatically prohibits privacy leakage. We support this theoretical system with a prototype within the Syft privacy platform using the PyTorch framework.
Sensitivity analysis in differentially private machine learning using hybrid automatic differentiation
Jul 09, 2021In recent years, formal methods of privacy protection such as differential privacy (DP), capable of deployment to data-driven tasks such as machine learning (ML), have emerged. Reconciling large-scale ML with the closed-form reasoning required for the principled analysis of individual privacy loss requires the introduction of new tools for automatic sensitivity analysis and for tracking an individual's data and their features through the flow of computation. For this purpose, we introduce a novel \textit{hybrid} automatic differentiation (AD) system which combines the efficiency of reverse-mode AD with an ability to obtain a closed-form expression for any given quantity in the computational graph. This enables modelling the sensitivity of arbitrary differentiable function compositions, such as the training of neural networks on private data. We demonstrate our approach by analysing the individual DP guarantees of statistical database queries. Moreover, we investigate the application of our technique to the training of DP neural networks. Our approach can enable the principled reasoning about privacy loss in the setting of data processing, and further the development of automatic sensitivity analysis and privacy budgeting systems.
DP-SGD vs PATE: Which Has Less Disparate Impact on Model Accuracy?
Jun 22, 2021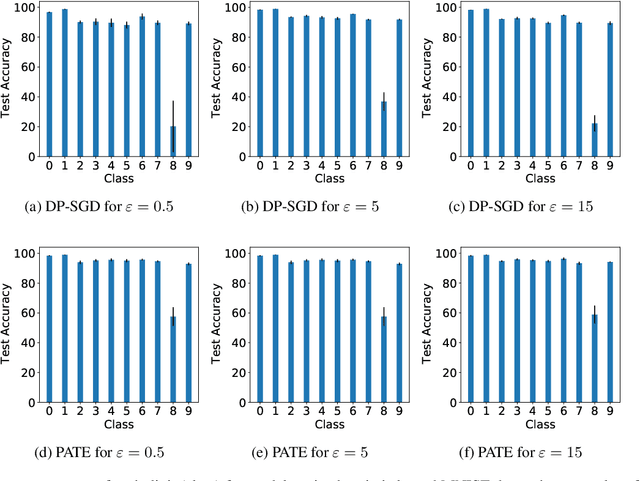
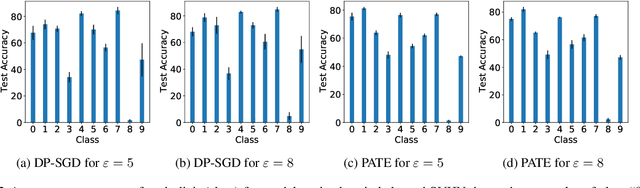
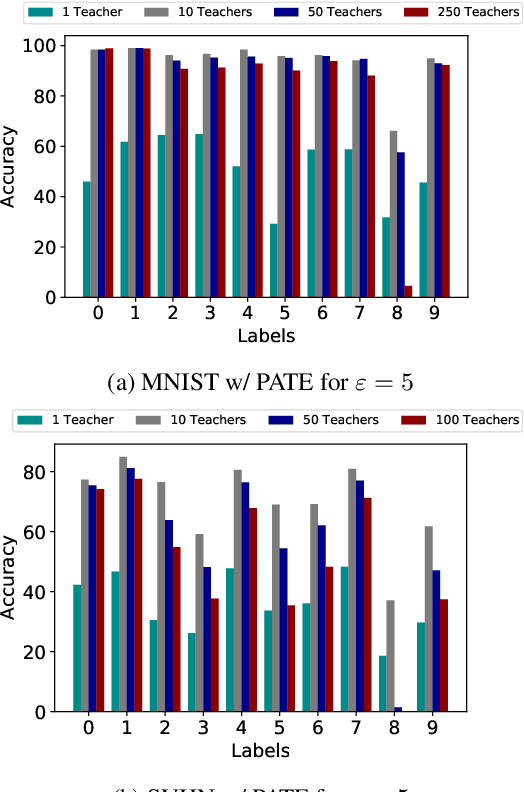
Recent advances in differentially private deep learning have demonstrated that application of differential privacy, specifically the DP-SGD algorithm, has a disparate impact on different sub-groups in the population, which leads to a significantly high drop-in model utility for sub-populations that are under-represented (minorities), compared to well-represented ones. In this work, we aim to compare PATE, another mechanism for training deep learning models using differential privacy, with DP-SGD in terms of fairness. We show that PATE does have a disparate impact too, however, it is much less severe than DP-SGD. We draw insights from this observation on what might be promising directions in achieving better fairness-privacy trade-offs.
Syft 0.5: A Platform for Universally Deployable Structured Transparency
Apr 27, 2021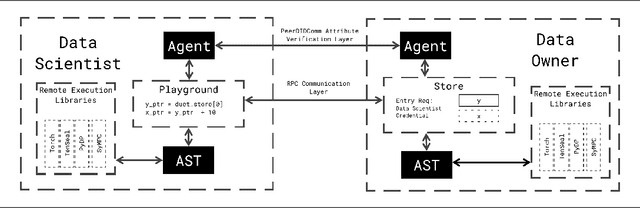
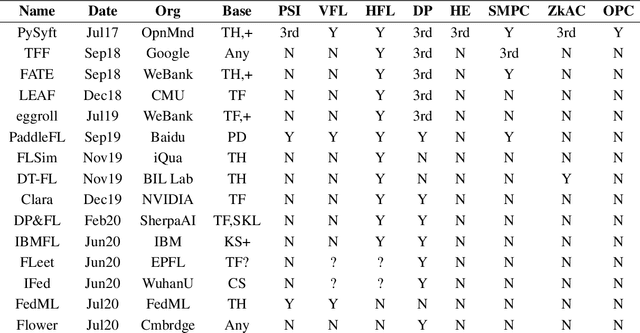
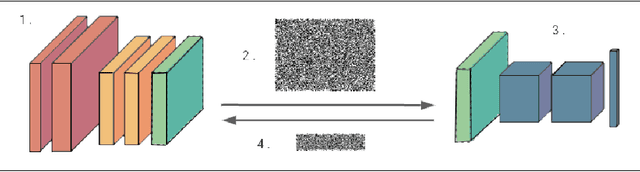
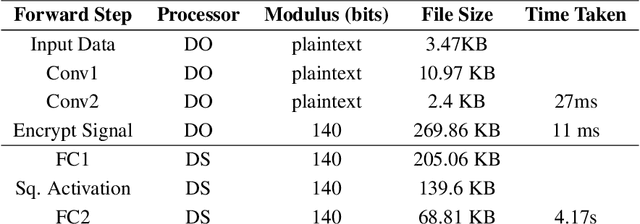
We present Syft 0.5, a general-purpose framework that combines a core group of privacy-enhancing technologies that facilitate a universal set of structured transparency systems. This framework is demonstrated through the design and implementation of a novel privacy-preserving inference information flow where we pass homomorphically encrypted activation signals through a split neural network for inference. We show that splitting the model further up the computation chain significantly reduces the computation time of inference and the payload size of activation signals at the cost of model secrecy. We evaluate our proposed flow with respect to its provision of the core structural transparency principles.
Privacy-preserving medical image analysis
Dec 10, 2020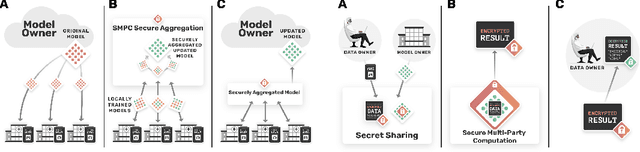
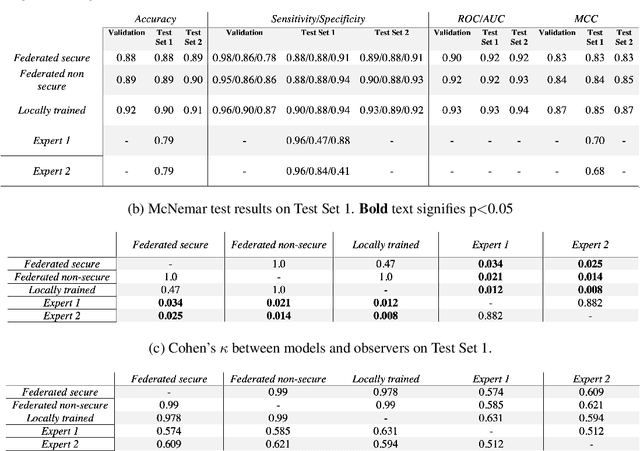
The utilisation of artificial intelligence in medicine and healthcare has led to successful clinical applications in several domains. The conflict between data usage and privacy protection requirements in such systems must be resolved for optimal results as well as ethical and legal compliance. This calls for innovative solutions such as privacy-preserving machine learning (PPML). We present PriMIA (Privacy-preserving Medical Image Analysis), a software framework designed for PPML in medical imaging. In a real-life case study we demonstrate significantly better classification performance of a securely aggregated federated learning model compared to human experts on unseen datasets. Furthermore, we show an inference-as-a-service scenario for end-to-end encrypted diagnosis, where neither the data nor the model are revealed. Lastly, we empirically evaluate the framework's security against a gradient-based model inversion attack and demonstrate that no usable information can be recovered from the model.
Neither Private Nor Fair: Impact of Data Imbalance on Utility and Fairness in Differential Privacy
Oct 03, 2020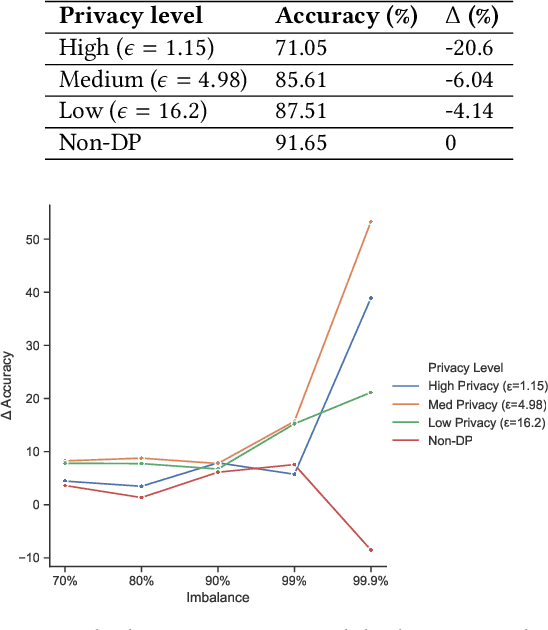
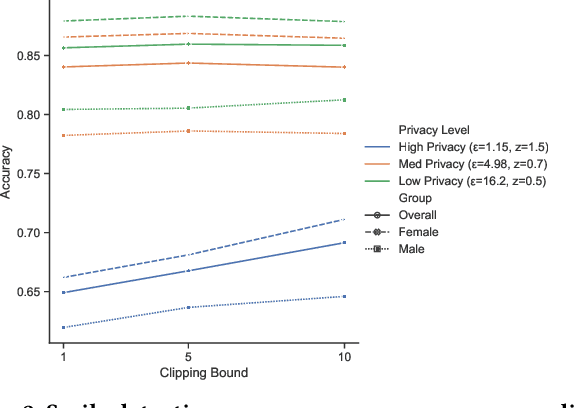
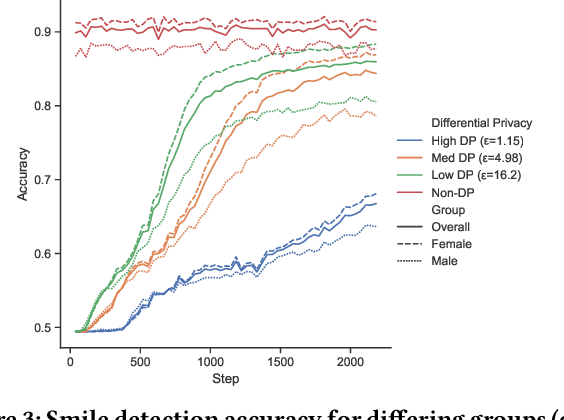
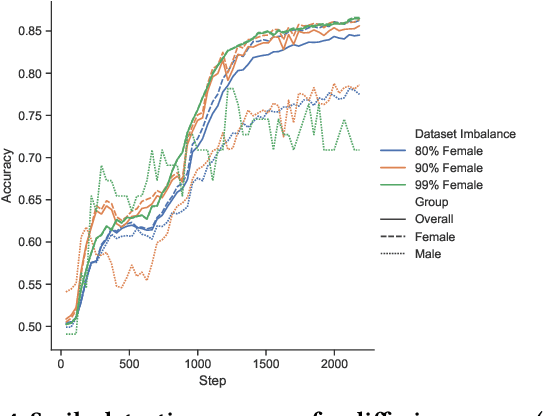
Deployment of deep learning in different fields and industries is growing day by day due to its performance, which relies on the availability of data and compute. Data is often crowd-sourced and contains sensitive information about its contributors, which leaks into models that are trained on it. To achieve rigorous privacy guarantees, differentially private training mechanisms are used. However, it has recently been shown that differential privacy can exacerbate existing biases in the data and have disparate impacts on the accuracy of different subgroups of data. In this paper, we aim to study these effects within differentially private deep learning. Specifically, we aim to study how different levels of imbalance in the data affect the accuracy and the fairness of the decisions made by the model, given different levels of privacy. We demonstrate that even small imbalances and loose privacy guarantees can cause disparate impacts.
Benchmarking Differentially Private Residual Networks for Medical Imagery
Jun 28, 2020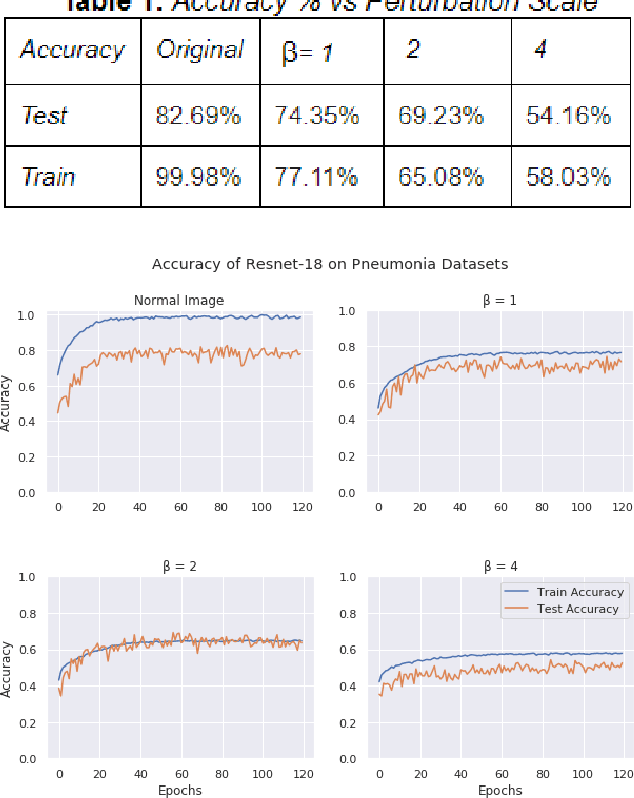
Hospitals and other medical institutions often have vast amounts of medical data which can provide significant value when utilized to advance research. However, this data is often sensitive in nature and as such is not readily available for use in a research setting, often due to privacy concerns. In this paper, we measure the performance of a deep neural network on differentially private image datasets pertaining to Pneumonia. We analyze the trade-off between the model's accuracy and the scale of perturbation among the images. Knowing how the model's accuracy varies among different perturbation levels in differentially private medical images can be quite a useful measure for hospitals to know. Furthermore, we also seek to measure the usefulness of local differential privacy for such medical imagery tasks and see if there's room for improvement.
The Future of Digital Health with Federated Learning
Mar 18, 2020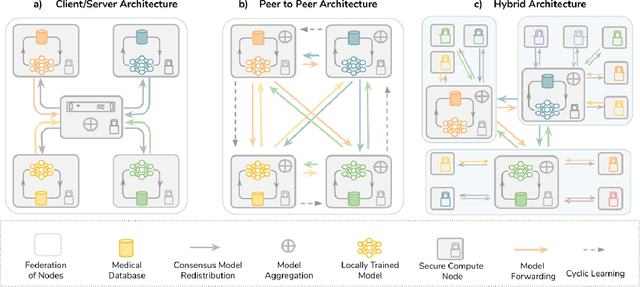
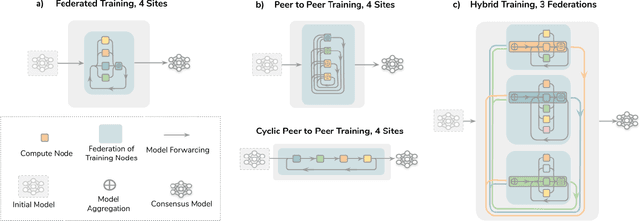
Data-driven Machine Learning has emerged as a promising approach for building accurate and robust statistical models from medical data, which is collected in huge volumes by modern healthcare systems. Existing medical data is not fully exploited by ML primarily because it sits in data silos and privacy concerns restrict access to this data. However, without access to sufficient data, ML will be prevented from reaching its full potential and, ultimately, from making the transition from research to clinical practice. This paper considers key factors contributing to this issue, explores how Federated Learning (FL) may provide a solution for the future of digital health and highlights the challenges and considerations that need to be addressed.