 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeither Private Nor Fair: Impact of Data Imbalance on Utility and Fairness in Differential Privacy
Oct 03, 2020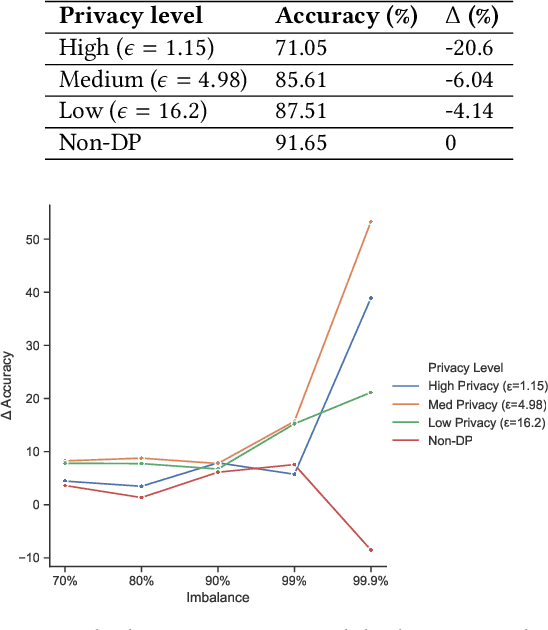
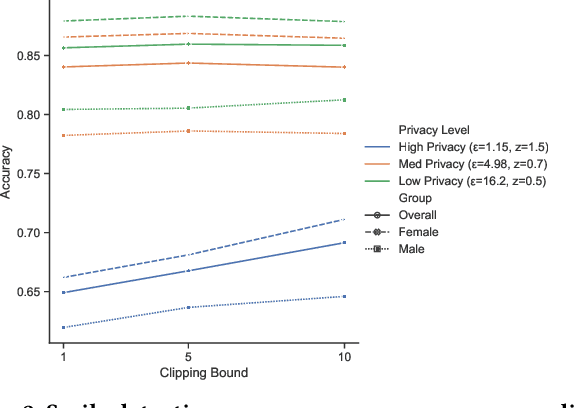
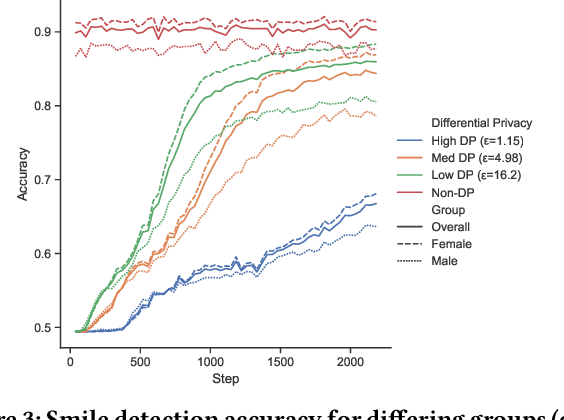
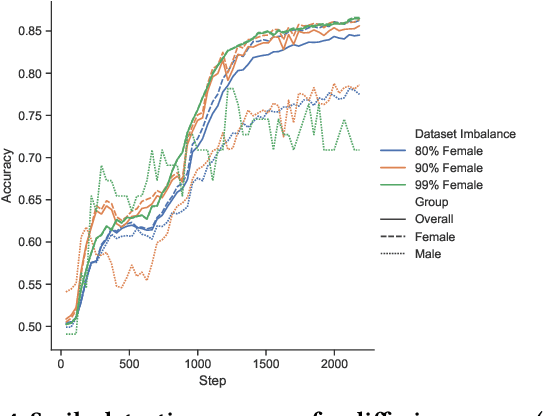
Deployment of deep learning in different fields and industries is growing day by day due to its performance, which relies on the availability of data and compute. Data is often crowd-sourced and contains sensitive information about its contributors, which leaks into models that are trained on it. To achieve rigorous privacy guarantees, differentially private training mechanisms are used. However, it has recently been shown that differential privacy can exacerbate existing biases in the data and have disparate impacts on the accuracy of different subgroups of data. In this paper, we aim to study these effects within differentially private deep learning. Specifically, we aim to study how different levels of imbalance in the data affect the accuracy and the fairness of the decisions made by the model, given different levels of privacy. We demonstrate that even small imbalances and loose privacy guarantees can cause disparate impacts.