 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiologically-Informed Hybrid Membership Inference Attacks on Generative Genomic Models
Nov 13, 2025The increased availability of genetic data has transformed genomics research, but raised many privacy concerns regarding its handling due to its sensitive nature. This work explores the use of language models (LMs) for the generation of synthetic genetic mutation profiles, leveraging differential privacy (DP) for the protection of sensitive genetic data. We empirically evaluate the privacy guarantees of our DP modes by introducing a novel Biologically-Informed Hybrid Membership Inference Attack (biHMIA), which combines traditional black box MIA with contextual genomics metrics for enhanced attack power. Our experiments show that both small and large transformer GPT-like models are viable synthetic variant generators for small-scale genomics, and that our hybrid attack leads, on average, to higher adversarial success compared to traditional metric-based MIAs.
Efficient and Private: Memorisation under differentially private parameter-efficient fine-tuning in language models
Nov 24, 2024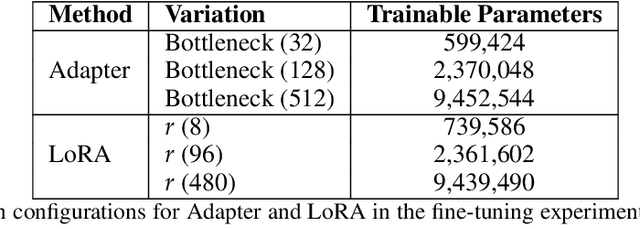
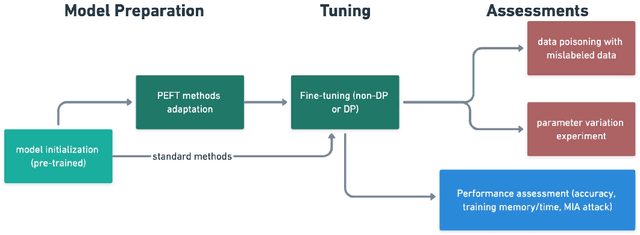

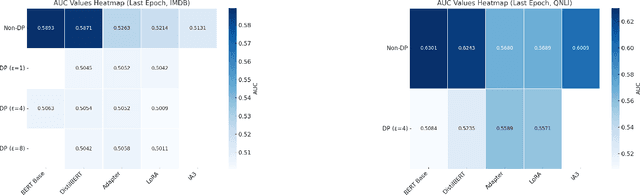
Fine-tuning large language models (LLMs) for specific tasks introduces privacy risks, as models may inadvertently memorise and leak sensitive training data. While Differential Privacy (DP) offers a solution to mitigate these risks, it introduces significant computational and performance trade-offs, particularly with standard fine-tuning approaches. Previous work has primarily focused on full-parameter updates, which are computationally intensive and may not fully leverage DPs potential in large models. In this work, we address these shortcomings by investigating Parameter-Efficient Fine-Tuning (PEFT) methods under DP constraints. We show that PEFT methods achieve comparable performance to standard fine-tuning while requiring fewer parameters and significantly reducing privacy leakage. Furthermore, we incorporate a data poisoning experiment involving intentional mislabelling to assess model memorisation and directly measure privacy risks. Our findings indicate that PEFT methods not only provide a promising alternative but also serve as a complementary approach for privacy-preserving, resource-efficient fine-tuning of LLMs.
Trust the Process: Zero-Knowledge Machine Learning to Enhance Trust in Generative AI Interactions
Feb 09, 2024Generative AI, exemplified by models like transformers, has opened up new possibilities in various domains but also raised concerns about fairness, transparency and reliability, especially in fields like medicine and law. This paper emphasizes the urgency of ensuring fairness and quality in these domains through generative AI. It explores using cryptographic techniques, particularly Zero-Knowledge Proofs (ZKPs), to address concerns regarding performance fairness and accuracy while protecting model privacy. Applying ZKPs to Machine Learning models, known as ZKML (Zero-Knowledge Machine Learning), enables independent validation of AI-generated content without revealing sensitive model information, promoting transparency and trust. ZKML enhances AI fairness by providing cryptographic audit trails for model predictions and ensuring uniform performance across users. We introduce snarkGPT, a practical ZKML implementation for transformers, to empower users to verify output accuracy and quality while preserving model privacy. We present a series of empirical results studying snarkGPT's scalability and performance to assess the feasibility and challenges of adopting a ZKML-powered approach to capture quality and performance fairness problems in generative AI models.
ARIA: On the interaction between Architectures, Aggregation methods and Initializations in federated visual classification
Nov 24, 2023Federated Learning (FL) is a collaborative training paradigm that allows for privacy-preserving learning of cross-institutional models by eliminating the exchange of sensitive data and instead relying on the exchange of model parameters between the clients and a server. Despite individual studies on how client models are aggregated, and, more recently, on the benefits of ImageNet pre-training, there is a lack of understanding of the effect the architecture chosen for the federation has, and of how the aforementioned elements interconnect. To this end, we conduct the first joint ARchitecture-Initialization-Aggregation study and benchmark ARIAs across a range of medical image classification tasks. We find that, contrary to current practices, ARIA elements have to be chosen together to achieve the best possible performance. Our results also shed light on good choices for each element depending on the task, the effect of normalisation layers, and the utility of SSL pre-training, pointing to potential directions for designing FL-specific architectures and training pipelines.
Contribution Evaluation in Federated Learning: Examining Current Approaches
Nov 16, 2023Federated Learning (FL) has seen increasing interest in cases where entities want to collaboratively train models while maintaining privacy and governance over their data. In FL, clients with private and potentially heterogeneous data and compute resources come together to train a common model without raw data ever leaving their locale. Instead, the participants contribute by sharing local model updates, which, naturally, differ in quality. Quantitatively evaluating the worth of these contributions is termed the Contribution Evaluation (CE) problem. We review current CE approaches from the underlying mathematical framework to efficiently calculate a fair value for each client. Furthermore, we benchmark some of the most promising state-of-the-art approaches, along with a new one we introduce, on MNIST and CIFAR-10, to showcase their differences. Designing a fair and efficient CE method, while a small part of the overall FL system design, is tantamount to the mainstream adoption of FL.
Cooperative AI via Decentralized Commitment Devices
Nov 14, 2023Credible commitment devices have been a popular approach for robust multi-agent coordination. However, existing commitment mechanisms face limitations like privacy, integrity, and susceptibility to mediator or user strategic behavior. It is unclear if the cooperative AI techniques we study are robust to real-world incentives and attack vectors. However, decentralized commitment devices that utilize cryptography have been deployed in the wild, and numerous studies have shown their ability to coordinate algorithmic agents facing adversarial opponents with significant economic incentives, currently in the order of several million to billions of dollars. In this paper, we use examples in the decentralization and, in particular, Maximal Extractable Value (MEV) (arXiv:1904.05234) literature to illustrate the potential security issues in cooperative AI. We call for expanded research into decentralized commitments to advance cooperative AI capabilities for secure coordination in open environments and empirical testing frameworks to evaluate multi-agent coordination ability given real-world commitment constraints.
Split HE: Fast Secure Inference Combining Split Learning and Homomorphic Encryption
Feb 27, 2022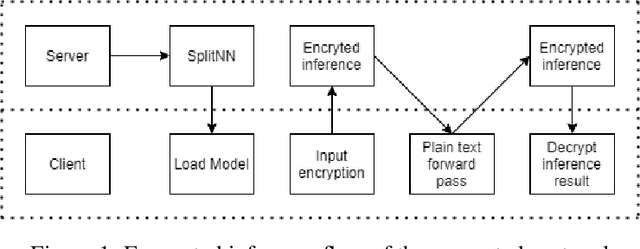

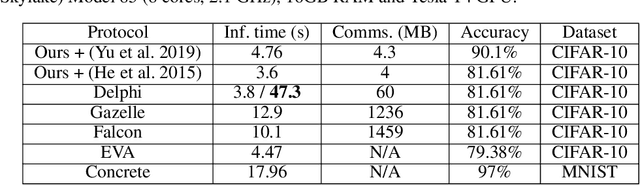
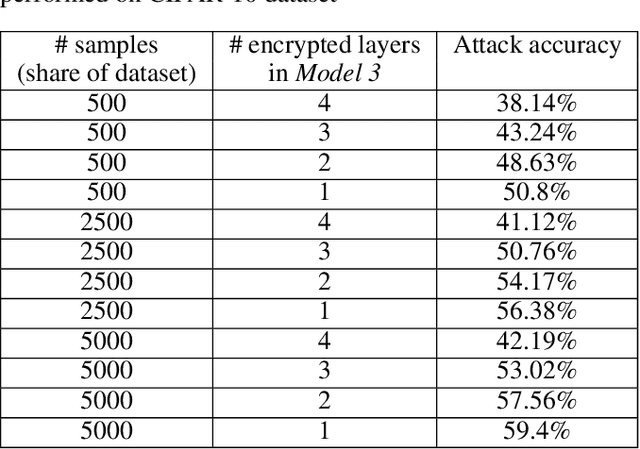
This work presents a novel protocol for fast secure inference of neural networks applied to computer vision applications. It focuses on improving the overall performance of the online execution by deploying a subset of the model weights in plaintext on the client's machine, in the fashion of SplitNNs. We evaluate our protocol on benchmark neural networks trained on the CIFAR-10 dataset using SEAL via TenSEAL and discuss runtime and security performances. Empirical security evaluation using Membership Inference and Model Extraction attacks showed that the protocol was more resilient under the same attacks than a similar approach also based on SplitNN. When compared to related work, we demonstrate improvements of 2.5x-10x for the inference time and 14x-290x in communication costs.
Distributed Machine Learning and the Semblance of Trust
Dec 21, 2021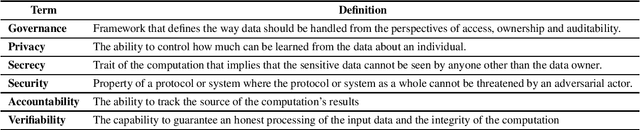
The utilisation of large and diverse datasets for machine learning (ML) at scale is required to promote scientific insight into many meaningful problems. However, due to data governance regulations such as GDPR as well as ethical concerns, the aggregation of personal and sensitive data is problematic, which prompted the development of alternative strategies such as distributed ML (DML). Techniques such as Federated Learning (FL) allow the data owner to maintain data governance and perform model training locally without having to share their data. FL and related techniques are often described as privacy-preserving. We explain why this term is not appropriate and outline the risks associated with over-reliance on protocols that were not designed with formal definitions of privacy in mind. We further provide recommendations and examples on how such algorithms can be augmented to provide guarantees of governance, security, privacy and verifiability for a general ML audience without prior exposure to formal privacy techniques.
FedRAD: Federated Robust Adaptive Distillation
Dec 02, 2021
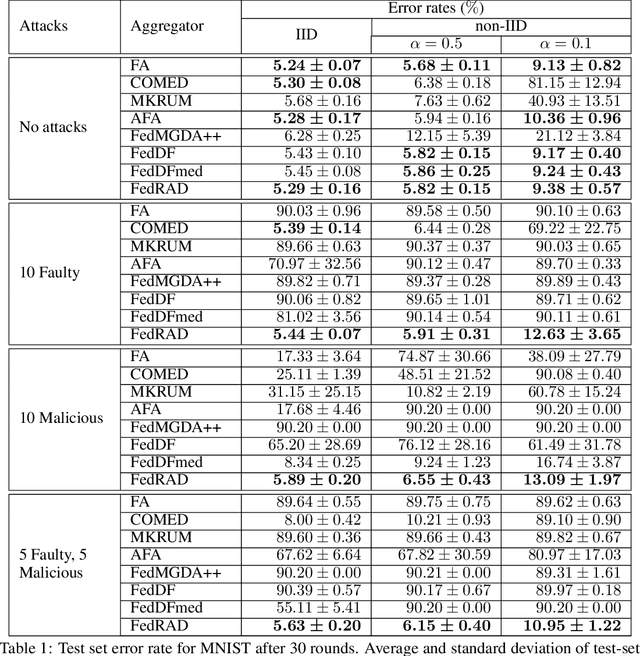
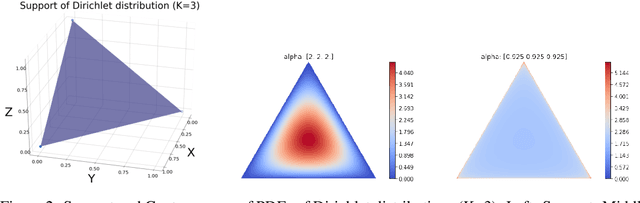
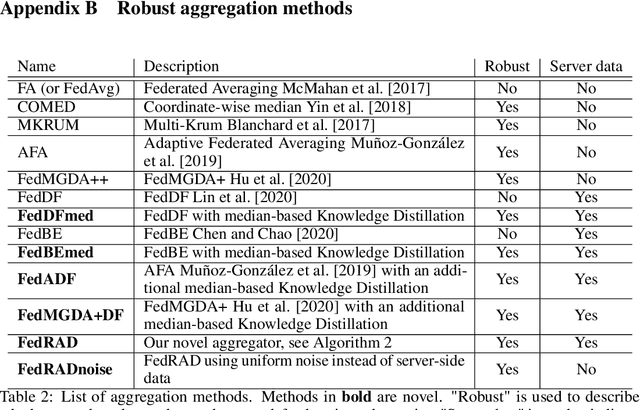
The robustness of federated learning (FL) is vital for the distributed training of an accurate global model that is shared among large number of clients. The collaborative learning framework by typically aggregating model updates is vulnerable to model poisoning attacks from adversarial clients. Since the shared information between the global server and participants are only limited to model parameters, it is challenging to detect bad model updates. Moreover, real-world datasets are usually heterogeneous and not independent and identically distributed (Non-IID) among participants, which makes the design of such robust FL pipeline more difficult. In this work, we propose a novel robust aggregation method, Federated Robust Adaptive Distillation (FedRAD), to detect adversaries and robustly aggregate local models based on properties of the median statistic, and then performing an adapted version of ensemble Knowledge Distillation. We run extensive experiments to evaluate the proposed method against recently published works. The results show that FedRAD outperforms all other aggregators in the presence of adversaries, as well as in heterogeneous data distributions.
Statistical Privacy Guarantees of Machine Learning Preprocessing Techniques
Sep 06, 2021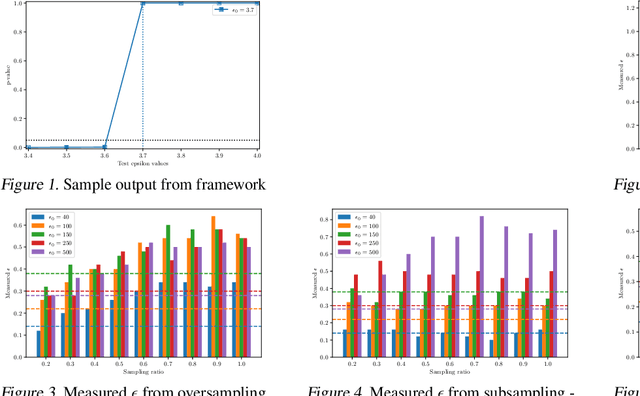
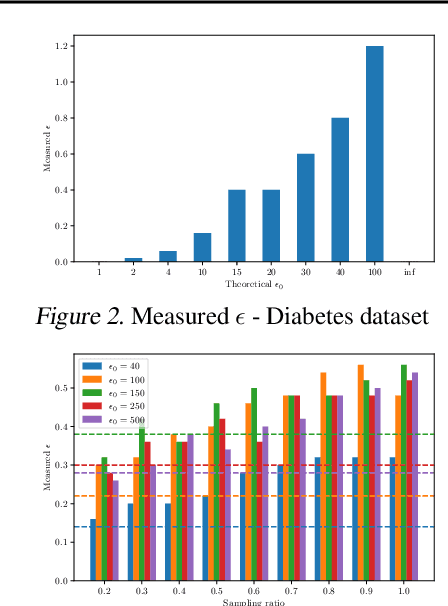
Differential privacy provides strong privacy guarantees for machine learning applications. Much recent work has been focused on developing differentially private models, however there has been a gap in other stages of the machine learning pipeline, in particular during the preprocessing phase. Our contributions are twofold: we adapt a privacy violation detection framework based on statistical methods to empirically measure privacy levels of machine learning pipelines, and apply the newly created framework to show that resampling techniques used when dealing with imbalanced datasets cause the resultant model to leak more privacy. These results highlight the need for developing private preprocessing techniques.