Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Privacy Guarantees of Machine Learning Preprocessing Techniques
Sep 06, 2021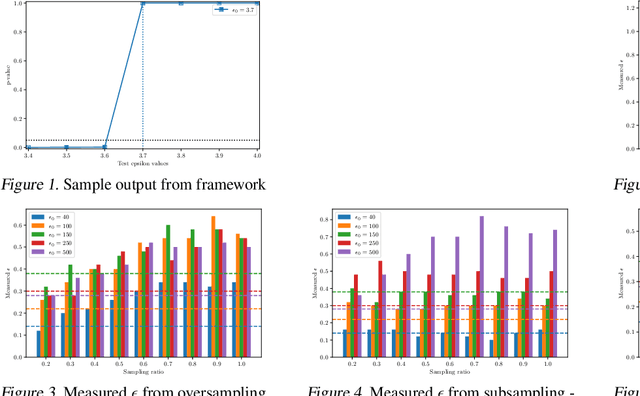
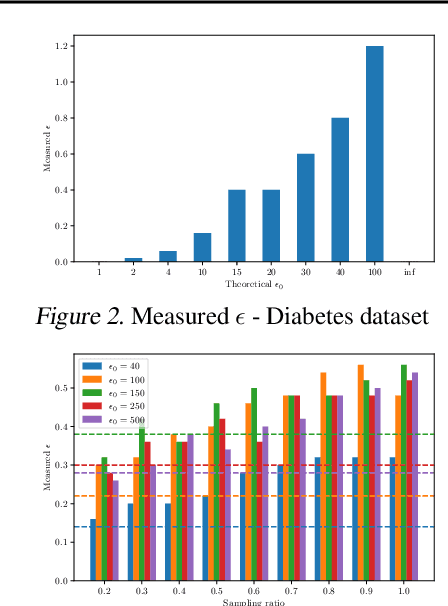
Differential privacy provides strong privacy guarantees for machine learning applications. Much recent work has been focused on developing differentially private models, however there has been a gap in other stages of the machine learning pipeline, in particular during the preprocessing phase. Our contributions are twofold: we adapt a privacy violation detection framework based on statistical methods to empirically measure privacy levels of machine learning pipelines, and apply the newly created framework to show that resampling techniques used when dealing with imbalanced datasets cause the resultant model to leak more privacy. These results highlight the need for developing private preprocessing techniques.
* Accepted to the ICML 2021 Theory and Practice of Differential Privacy
Workshop
Via